C
时间轴
2025-07-19
init
数据类型
常见整数的范围
| 数据类型 | 字节数 | 十进制取值范围 | 科学计数法表示(约) |
|---|---|---|---|
char |
1 | -128 ~ 127 | -1.28×10² ~ 1.27×10² |
unsigned char |
1 | 0 ~ 255 | 0 ~ 2.55×10² |
short |
2 | -32,768 ~ 32,767 | -3.28×10⁴ ~ 3.27×10⁴ |
unsigned short |
2 | 0 ~ 65,535 | 0 ~ 6.55×10⁴ |
int |
4 | -2,147,483,648 ~ 2,147,483,647 | -2.15×10⁹ ~ 2.15×10⁹ |
unsigned int |
4 | 0 ~ 4,294,967,295 | 0 ~ 4.29×10⁹ |
long (Linux 64 位) |
8 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | ±9.22×10¹⁸ |
unsigned long |
8 | 0 ~ 18,446,744,073,709,551,615 | 0 ~ 1.84×10¹⁹ |
long long |
8 | -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 | ±9.22×10¹⁸ |
unsigned long long |
8 | 0 ~ 18,446,744,073,709,551,615 | 0 ~ 1.84×10¹⁹ |
- long 的字节数在 不同平台上可能不同,如在 64 位 Linux 系统上通常为 8 字节。
- 实际大小和范围由编译器及目标平台的 data model 决定,如 LP64(Linux)/LLP64(Windows)
ASCII 表
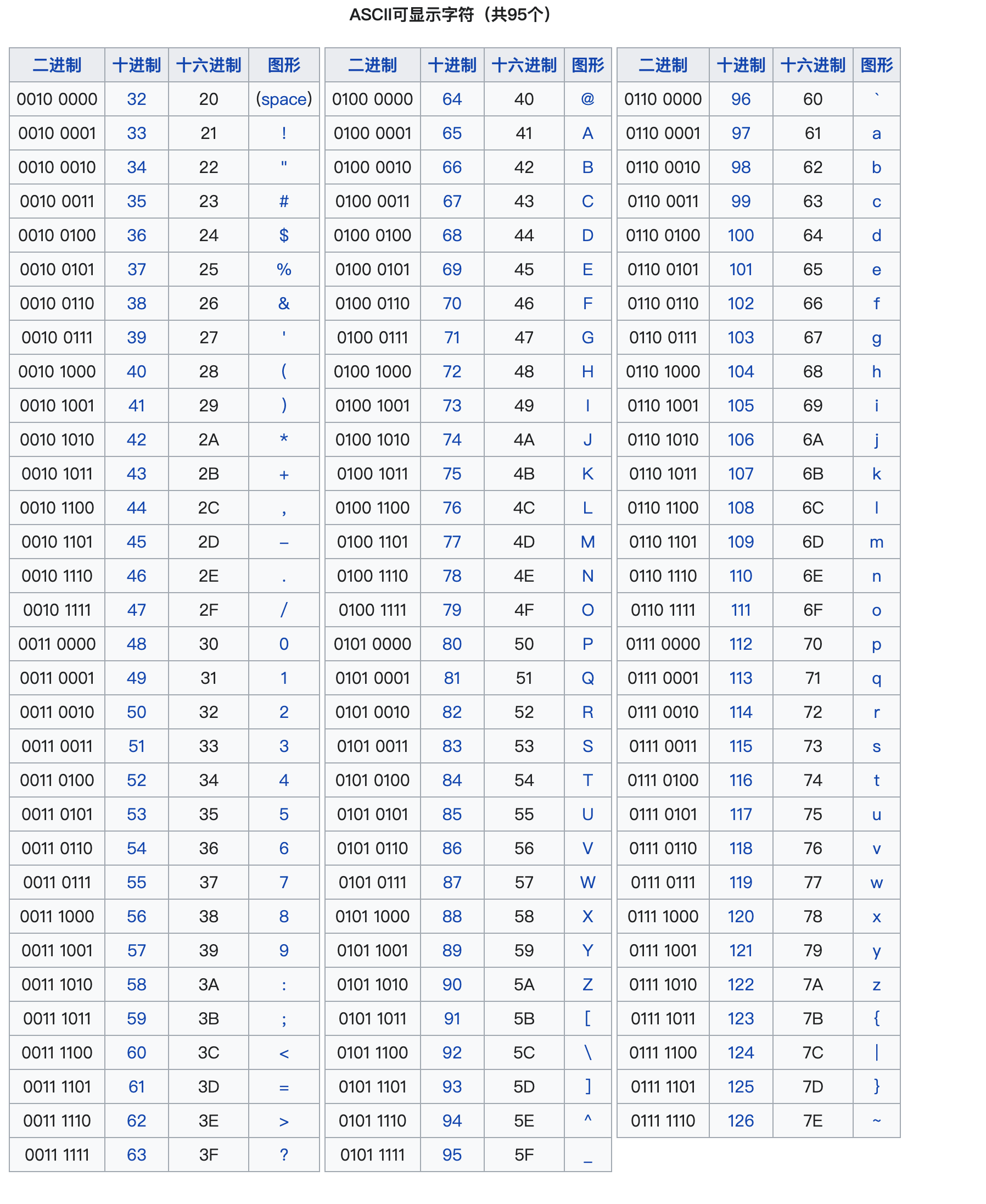
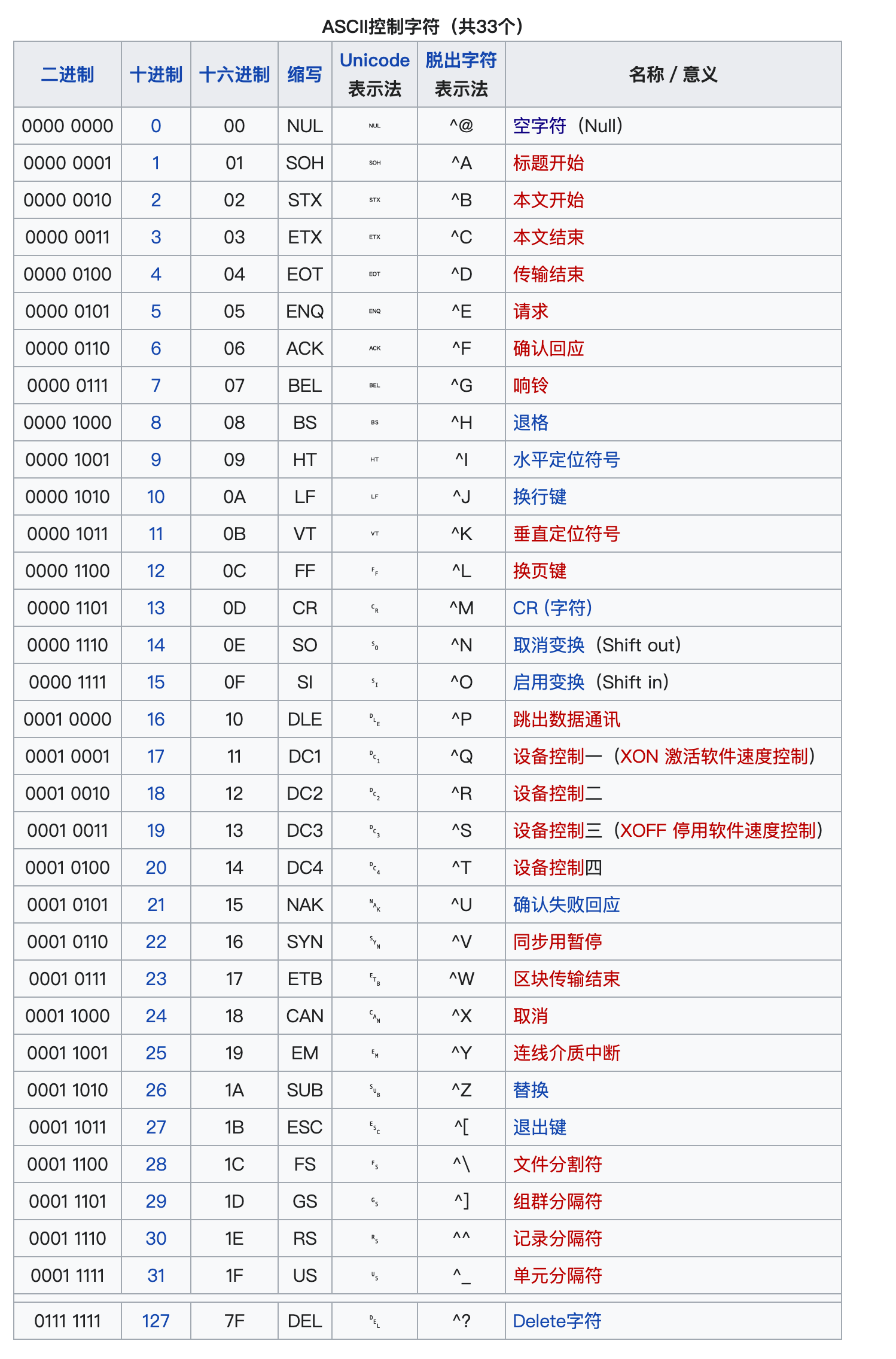
库函数
输入输出
scanf
%c 和空白的区别
1 | scanf("%c", &ch); |
会 原封不动 读取一个字符,包括空格、制表符、换行 \n。
1 | scanf(" %c", &ch); |
因为格式字符串里有个 空格,scanf 会先跳过所有 空白字符(space、\t、\n),再读一个有效字符。
1 | while(scanf("%d",&x)!=EOF) |
总结:
- scanf 读取非法值时会返回 EOF
- %d、%f 等数字格式符号:默认自动跳过空白。
- %c:不会跳过空白,需要 “ %c” 才能忽略空格、换行。
- 原理:scanf 的格式字符串里,空白符(空格、\n、\t)意味着“匹配任意数量的空白”。
getline
getline() 的返回值是读取的字符数(包括换行符)
| 参数 | 含义 |
|---|---|
char **lineptr |
指向一个 char* 指针(用来存储读入的字符串,函数内部会自动分配/扩展内存) |
size_t *n |
指向缓冲区大小(初始为 0),函数根据需要动态分配/扩展内存 |
FILE *stream |
输入流,例如 stdin、文件句柄等 |
返回值
- 成功:返回读取到的字符数(包括换行符
\n,但不包括终止符\0) - 失败:返回
-1,并设置errno
使用 getline 需要包含 GNU 扩展定义的 <stdio.h> 和 <stdlib.h>,但更关键的是在 某些非 POSIX 平台(如 Windows 或老标准 C 编译器) 中,getline() 并不是标准 C 函数。
综合解决方法(适用于 Linux/GCC 环境):
确保你包含了以下头文件:
1 | // 可选:启用 GNU 扩展 |
示例:
1 |
|
printf
printf 函数详解:
下面是 printf() 函数的声明。
1 | int printf(const char *format, ...) |
参数
- format – 这是字符串,包含了要被写入到标准输出 stdout 的文本。它可以包含嵌入的 format 标签,format 标签可被随后的附加参数中指定的值替换,并按需求进行格式化。
- format 标签属性是
1 | %[flags][width][.precision][length]specifier |
| 格式字符 | 意义 |
|---|---|
| a, A | 以十六进制形式输出浮点数(C99 新增)。实例 printf(“pi=%a\n”, 3.14); 输出 pi=0x1.91eb86p+1。 |
| d | 以十进制形式输出带符号整数(正数不输出符号) |
| o | 以八进制形式输出无符号整数(不输出前缀 0) |
| x,X | 以十六进制形式输出无符号整数(不输出前缀 Ox) |
| u | 以十进制形式输出无符号整数 |
| f | 以小数形式输出单、双精度实数 |
| e,E | 以指数形式输出单、双精度实数 |
| g,G | 以%f 或%e 中较短的输出宽度输出单、双精度实数 |
| c | 输出单个字符 |
| s | 输出字符串 |
| p | 输出指针地址 |
| lu | 32 位无符号整数 |
| llu | 64 位无符号整数 |
| flags(标识) | 描述 |
|---|---|
| - | 在给定的字段宽度内左对齐,默认是右对齐(参见 width 子说明符)。 |
| + | 强制在结果之前显示加号或减号(+ 或 -),即正数前面会显示 + 号。默认情况下,只有负数前面会显示一个 - 号。 |
| 空格 | 如果没有写入任何符号,则在该值前面插入一个空格。 |
| # | 与 o、x 或 X 说明符一起使用时,非零值前面会分别显示 0、0x 或 0X。 与 e、E 和 f 一起使用时,会强制输出包含一个小数点,即使后边没有数字时也会显示小数点。默认情况下,如果后边没有数字时候,不会显示显示小数点。 与 g 或 G 一起使用时,结果与使用 e 或 E 时相同,但是尾部的零不会被移除。 |
| 0 | 在指定填充 padding 的数字左边放置零(0),而不是空格(参见 width 子说明符)。 |
| width(宽度) | 描述 |
|---|---|
| (number) | 要输出的字符的最小数目。如果输出的值短于该数,结果会用空格填充。如果输出的值长于该数,结果不会被截断。 |
| * | 宽度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| .precision(精度) | 描述 |
|---|---|
| .number | 对于整数说明符(d、i、o、u、x、X):precision 指定了要写入的数字的最小位数。如果写入的值短于该数,结果会用前导零来填充。如果写入的值长于该数,结果不会被截断。精度为 0 意味着不写入任何字符。 对于 e、E 和 f 说明符:要在小数点后输出的小数位数。 对于 g 和 G 说明符:要输出的最大有效位数。 对于 s: 要输出的最大字符数。默认情况下,所有字符都会被输出,直到遇到末尾的空字符。 对于 c 类型:没有任何影响。 当未指定任何精度时,默认为 1。如果指定时不带有一个显式值,则假定为 0。 |
| .* | 精度在 format 字符串中未指定,但是会作为附加整数值参数放置于要被格式化的参数之前。 |
| length(长度) | 描述 |
|---|---|
| h | 参数被解释为短整型或无符号短整型(仅适用于整数说明符:i、d、o、u、x 和 X)。 |
| l | 参数被解释为长整型或无符号长整型,适用于整数说明符(i、d、o、u、x 和 X)及说明符 c(表示一个宽字符)和 s(表示宽字符字符串)。 |
| L | 参数被解释为长双精度型(仅适用于浮点数说明符:e、E、f、g 和 G)。 |
附加参数
根据不同的 format 字符串,函数可能需要一系列的附加参数,每个参数包含了一个要被插入的值,替换了 format 参数中指定的每个 % 标签。参数的个数应与 % 标签的个数相同。
返回值
如果成功,则返回写入的字符总数,否则返回一个负数。
math.h
错误状态宏定义
在 <math.h> 中,有一些宏用于表示数学函数的错误状态:
| 宏 | 描述 |
|---|---|
HUGE_VAL |
当函数结果溢出时返回的值(正无穷大)。此宏代表一个非常大的双精度浮点数,通常用来作为某些数学函数在结果超出可表示范围时的返回值。当一个函数的结果太大以至于无法用正常的浮点数表示(即发生上溢)时,会设置 errno 为 ERANGE(范围错误),并返回 HUGE_VAL 或其负值(对于负无穷大)。 |
HUGE_VALF |
当函数结果溢出时返回的值(正无穷大,浮点型) |
HUGE_VALL |
当函数结果溢出时返回的值(正无穷大,长双精度) |
INFINITY |
正无穷大 |
NAN |
非数字值(Not-A-Number) |
FP_INFINITE |
表示无穷大 |
FP_NAN |
表示非数字值 |
FP_NORMAL |
表示正常的浮点数 |
FP_SUBNORMAL |
表示次正规数 |
FP_ZERO |
表示零 |
库函数
下面列出了头文件 math.h 中定义的函数:
| 函数 | 描述 |
|---|---|
| double acos(double x) | 返回以弧度表示的 x 的反余弦。 |
| double asin(double x) | 返回以弧度表示的 x 的反正弦。 |
| double atan(double x) | 返回以弧度表示的 x 的反正切。 |
| double atan2(double y, double x) | 返回以弧度表示的 y/x 的反正切。y 和 x 的值的符号决定了正确的象限。 |
| double cos(double x) | 返回弧度角 x 的余弦。 |
| double cosh(double x) | 返回 x 的双曲余弦。 |
| double sin(double x) | 返回弧度角 x 的正弦。 |
| double sinh(double x) | 返回 x 的双曲正弦。 |
| double tanh(double x) | 返回 x 的双曲正切。 |
| double exp(double x) | 返回 e 的 x 次幂的值。 |
| double frexp(double x, int *exponent) | 把浮点数 x 分解成尾数和指数。返回值是尾数,并将指数存入 exponent 中。所得的值是 x = mantissa * 2 ^ exponent。 |
| double ldexp(double x, int exponent) | 返回 x 乘以 2 的 exponent 次幂。 |
| double log(double x) | 返回 x 的自然对数(基数为 e 的对数)。 |
| double log10(double x) | 返回 x 的常用对数(基数为 10 的对数)。 |
| double modf(double x, double *integer) | 返回值为小数部分(小数点后的部分),并设置 integer 为整数部分。 |
| double pow(double x, double y) | 返回 x 的 y 次幂。 |
| double sqrt(double x) | 返回 x 的平方根。 |
| double ceil(double x) | 返回大于或等于 x 的最小的整数值。 |
| double fabs(double x) | 返回 x 的绝对值。 |
| double floor(double x) | 返回小于或等于 x 的最大的整数值。 |
| double fmod(double x, double y) | 返回 x 除以 y 的余数。 |
| 函数名 | 作用 | 向哪边取整 |
|---|---|---|
round() |
四舍五入 | 到最近整数 |
floor() |
向下取整(不大于原数的最大整数) | 向 -∞ |
ceil() |
向上取整(不小于原数的最小整数) | 向 +∞ |
trunc() |
去除小数部分(直接截断) | 向 0 |
常用数学常量
以下是 <math.h> 中定义的一些常用数学常量:
| 常量 | 值 | 描述 |
|---|---|---|
M_PI |
3.14159265358979323846 | 圆周率 π |
M_E |
2.71828182845904523536 | 自然对数的底数 e |
M_LOG2E |
1.44269504088896340736 | log2(e) |
M_LOG10E |
0.43429448190325182765 | log10(e) |
M_LN2 |
0.69314718055994530942 | ln(2) |
M_LN10 |
2.30258509299404568402 | ln(10) |
M_PI_2 |
1.57079632679489661923 | π/2 |
M_PI_4 |
0.78539816339744830962 | π/4 |
M_1_PI |
0.31830988618379067154 | 1/π |
M_2_PI |
0.63661977236758134308 | 2/π |
M_2_SQRTPI |
1.12837916709551257390 | 2/√π |
M_SQRT2 |
1.41421356237309504880 | √2 |
M_SQRT1_2 |
0.70710678118654752440 | 1/√2 |
string.h
strdup
1 |
|
相当于 strcpy 但是会自动分配内存
strtok
1 | char *strtok(char *str, const char *delim) |
参数
str: 要分割的字符串。在第一次调用时,传入要分割的字符串;后续调用时,传入 NULL,表示继续分割同一个字符串。
delim: 分隔符字符串。strtok() 会根据这个字符串中的任意一个字符来分割 str。
返回值
返回指向下一个标记的指针。如果没有更多的标记,则返回 NULL。
1 | /* 获取第一个子字符串 */ |
注意事项
- 修改原字符串: strtok() 会修改传入的字符串,将分隔符替换为 \0(空字符)。因此,原始字符串会被破坏。
- 不可重入: strtok() 使用静态缓冲区来保存状态,因此它不是线程安全的。如果在多线程环境中使用,可以考虑使用 strtok_r()(可重入版本)。
- 连续分隔符: 如果字符串中有连续的分隔符,strtok() 会忽略它们,并返回下一个有效的标记。
可重入版本:strtok_r()
strtok_r() 是 strtok() 的可重入版本,它允许你在多线程环境中安全地使用。它的原型如下:
char *strtok_r(char *str, const char delim, char **saveptr);
saveptr: 是一个指向 char 的指针,用于保存分割的状态。
示例:
1 |
|
strcspn
strcspn 是 C 标准库 <string.h> 中的一个字符串处理函数,用于查找目标字符串中第一个匹配指定字符集合的字符的位置。
- 函数原型
1 |
|
- 功能说明
它返回字符串 s 中第一个包含 reject 中任意字符的位置(索引),如果 s 中不包含 reject 中的任何字符,就返回 strlen(s)。
💡 “cspn” 全称是 complement span,意思是:返回“不是 reject 的最长前缀”长度
- 示例
1 |
|
strspn
strspn 是 C 语言标准库 <string.h> 中的函数,用来计算一个字符串开头有多少字符全部属于指定的字符集合。
strspn 这个函数名来自 “string span” 的缩写,意思是“字符串的跨度”或“字符串中连续满足条件的前缀长度”。
对比 strcspn
| 函数名 | 含义说明 |
|---|---|
strspn |
span of characters in accept |
strcspn |
span of characters not in reject |
也就是说:
strspn(s, accept):从开头开始,统计多少字符在 accept 中
strcspn(s, reject):从开头开始,统计多少字符不在 reject 中
函数原型
1 |
|
- 功能说明
strspn(s, accept) 会返回字符串 s 开头连续有多少个字符,全部都出现在 accept 中。
- 它不会跳过字符,也不会检查整个字符串;
- 一旦遇到一个不属于 accept 的字符,就停止统计;
- 返回值是一个 size_t 类型(即无符号整数),表示匹配的长度。
- 示例
1 |
|
✨ 分析:
字符串 s = “abcabc123”
以 “a”, “b”, “c” 开头,刚好连着 6 个字符都在 “abc” 中
第 7 个字符是 ‘1’,不在 “abc” 中 → 统计停止
所以返回 6应用场景
📌 检查字符串开头是否只包含某些字符
1 | if (strspn(s, "0123456789") == strlen(s)) { |
📌 跳过前缀中所有合法字符
1 | char *s = " \t\n hello"; |
错误处理
errno
你可以在标准库函数调用失败时,通过读取 errno 的值来判断失败的具体原因,然后使用 perror() 或 strerror(errno) 获取对应的错误描述。
示例:使用 errno
1 |
|
输出:
1 | errno = 2 |