AArch64 ASM Book
时间轴
2025-06-22
init
preknowledge
1 byte has 8 bits
- char has 1 byte
- short has 2 byte
- int has 4 byte
每个地址代表一个字节的存储单元
1 | gcc -E hello.c -o hello.i |
All AARCH64 instructions are 4 bytes in width.
All AARCH64 pointers are 8 bytes in width†.
While this is technically true, typically only the lower 39, 42 or 48 bits of addresses in Linux systems are used - i.e. the virtual address space of an ARM Linux process is smaller than 64 bits. The upper bits are set to zero when considering the address as an 8-byte value.
register
register access speed
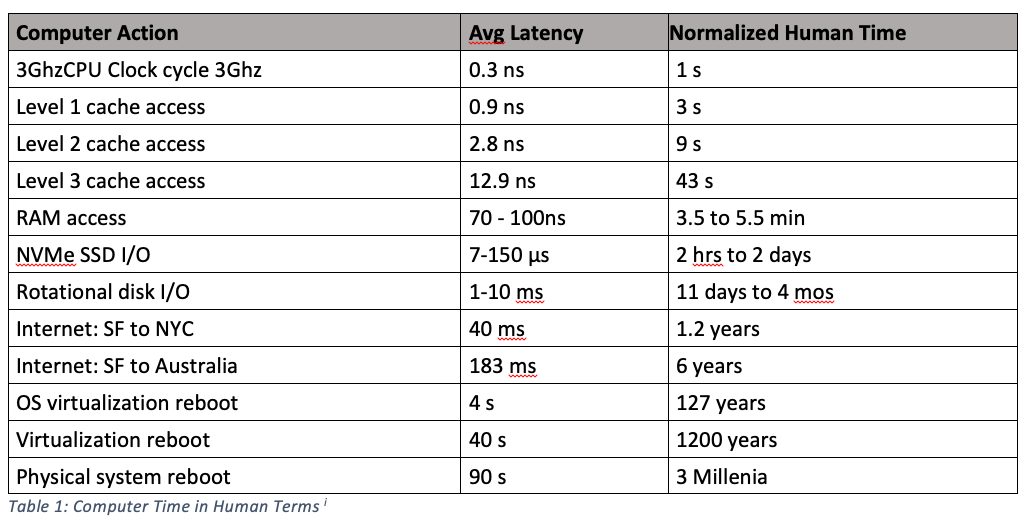
This says that if we liken accessing a register (which can be done at least once per CPU Clock Cycle) to one second, accessing RAM would be like a 3.5 to 5.5 minute wait.
register type
- rn means register “of some type” number n.
The kind of register is specified by a letter. Which register within a given type is specified by a number. There are some exceptions to this. Here is an introductory summary:
| Letter | Type |
|---|---|
| x | 64 bit integer or pointer |
| w | 32 bit or smaller integer |
| d | 64 bit floats (doubles) |
| s | 32 bit floats |
Some register types have been left out.
(Chapter 9.1)(Cortex-A Series Programmer’s Guide for ARMv8-A)
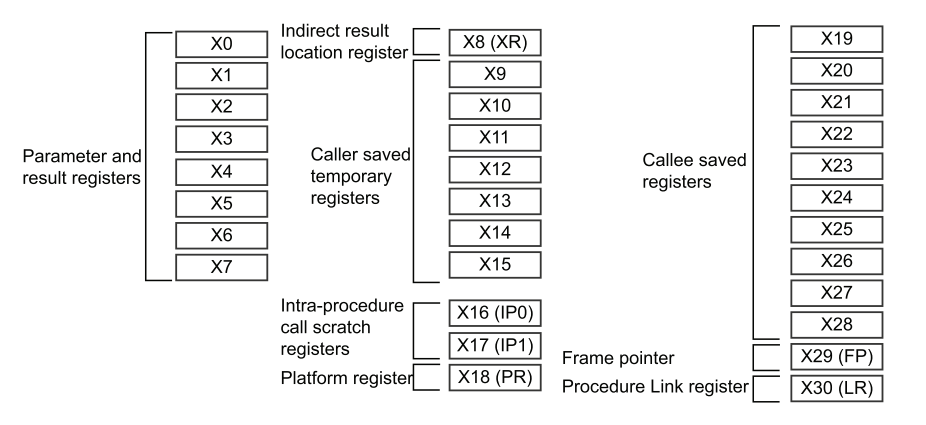
- x29 是栈帧指针(FP)
- x30 是链接寄存器(LR,即返回地址)
- 当函数返回值的类型过大(如超过 64 位,或为大型结构体、联合体),无法通过通用寄存器(X0~X7)直接传递时,调用者会预先分配一块内存作为 “返回结果的存储区域”,并将该区域的地址传递给被调用函数 —— 这块内存的地址就是 “Indirect Result Location”。被调用函数执行完毕后,会将结果写入该地址,而非通过寄存器返回。
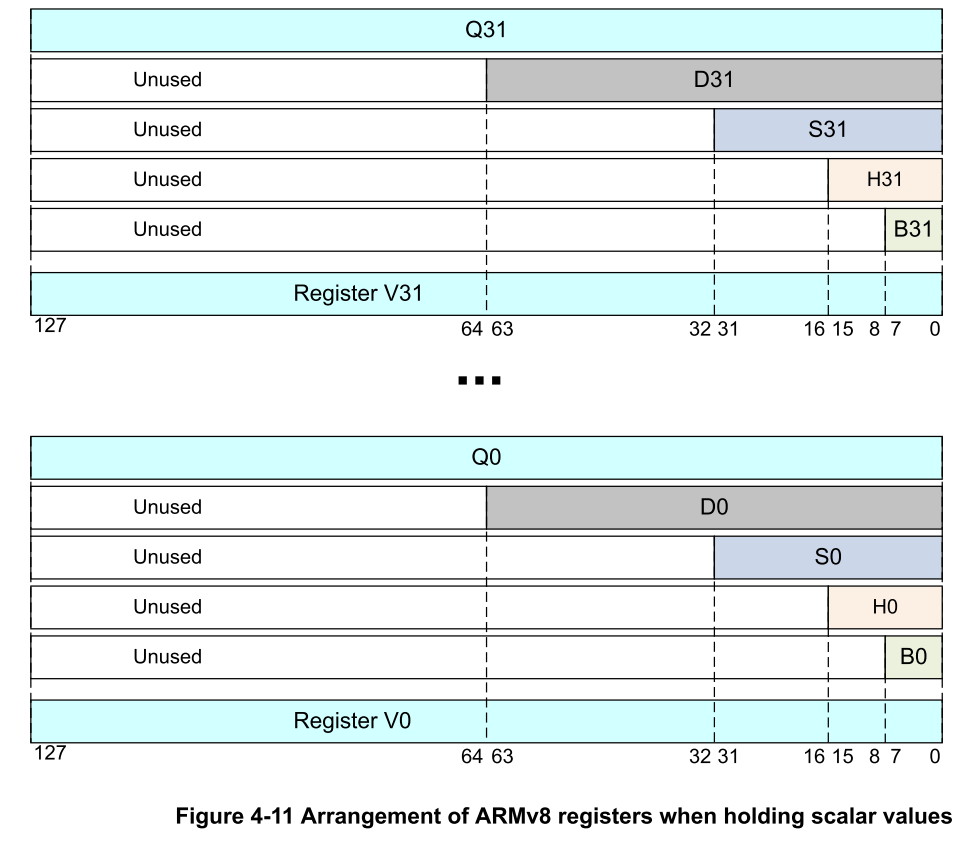
The registers used for floating point types (and vector operations) are coincident:
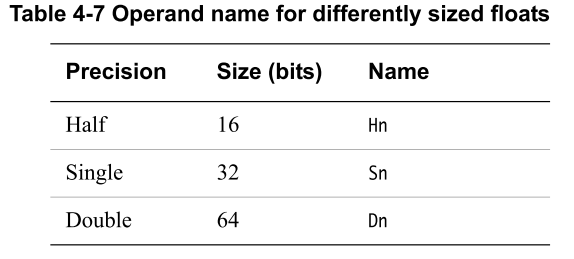
qregisters are a massive 16 bytes wide - quad words.(vn 的别名,主要用于SIMD/Neon 指令中)vregisters are also 16 bytes wide and are synonyms for theqregisters.dregisters fordoubleswhich are 8 bytes wide - double precision. 2 perv.sregisters forfloatswhich are 4 bytes wide - single precision. 4 perv.hregisters forhalf precisions floatswhich are 2 bytes wide. 8 perv.bregisters for byte operations. 16 perv.
register and C type
Integers
| This declares an integer | This IS an integer |
|---|---|
| char | wn |
| short | wn |
| int | wn |
| long | xn |
Pointers
| This declares a pointer | This IS a pointer |
|---|---|
| type * | xn |
All pointers are stored in x registers. X registers are 64 bits long but many operating systems do not support 64 bit address spaces because keeping track of that big of an address space itself would use a lot of space. Instead OS’s typically have 48 to 52 bit address spaces.
Floating Point
| This declares a float | This IS a float |
|---|---|
float |
sn |
double |
dn |
__fp16 (half) |
hn |
vn 是真正的物理寄存器名,推荐使用, 支持最多类型的访问(浮点 + SIMD)
qn 是 vn 的别名,主要用于SIMD/Neon 指令中(Single Instruction - Multiple Data)
instructions
preknowledge
EVERY AARCH64 instruction is 4 bytes wide. Everything the CPU needs to know about what the instruction is and what variation it might be plus what data it will use will be found in those 4 bytes.
- Most (but not all) AARCH64 instructions have three operands. These are read in the following way:
1 | op ra, rb, rc |
means:
1 | ra = rb op rc |
examples:
1 | sub x0, x0, x1 ; means x0 = x0 - x1 |
- [ ]
the [ and ] serve the same purpose of the asterisk in C and C++ indicating “dereference.” It means use what’s inside the brackets as an address for going out to memory.
when a ! is at the end of [] , for example:
1 | stp x21, x30, [sp, -16]! |
Lastly, the exclamation point means that the stack pointer should be changed (i.e. the -16 applied to it) before the value of the stack pointer is used as the address in memory to which the registers will be copied. Again, this is a predecrement.
it means:
sp = sp - 16(栈指针向下移动 16 字节)- 把
x29存入[sp],把x30存入[sp + 8]
对应:
1 | ldp x29, x30, [sp], 16 |
it means:
- 从
[sp]读取 8 字节给x29,从[sp + 8]读取 8 字节给x30 sp = sp + 16(释放栈帧空间)
The stack pointer in ARM V8 can only be manipulated in multiples of 16.
The stack pointer in ARM V8 can only be manipulated in multiples of 16.
The stack pointer in ARM V8 can only be manipulated in multiples of 16.
x29 是栈帧寄存器,但不是必须保存的
memory access
ldr
load register
1 | ldr x0, [sp] // load 8 bytes from address specified by sp |
When misaligned accesses to RAM are made, the processor must slow down and access each byte individually. This is a big performance hit. Properly aligned access is critical to performance.
str
store register
1 | str x0, [sp] // store 8 bytes to address specified by sp |
Casting between integer types is in some cases accomplished by
andingwith255and65535(forcharandshort) or :Whenever a narrower portion of a register is written to, the remainder of the register is zero’d out. That is:
ldrboverwrites the least significant byte of anxregister and zeros out the upper 7 bytes.
ldp
load pair, same as ldr but load a pair of value
stp
store pair, same as str but load a pair of value
offsets
1 | 1) LDR Xt, [Xn|SP{, #pimm}] ; 64-bit general registers |
simmcan be in the range of -256 to 255 (10 byte signed value).pimmcan be in the range of 0 to 32760 in multiples of 8.
three patterns
- 普通偏移模式
1 | LDR Xt, [Xn, #pimm] |
从
Xn + pimm的地址加载数据到Xt;地址寄存器Xn不变;
pimm是一个 正的立即数(positive immediate),必须是 8 的倍数,最大为 32760。
- 后变基模式
1 | LDR Xt, [Xn], #simm |
先用
Xn的原始值作为地址加载数据到Xt,然后再用simm更新Xn;地址寄存器Xn读取内存后改变;
- 前变基模式
1 | LDR Xt, [Xn, #simm]! |
先
Xn = Xn + simm,然后将Xn作为地址加载数据到Xt,地址寄存器Xn读取内存前改变;
pseudo instruction
1 | ldr x1, =label |
the assembler puts the address of the label into a special region of memory called a “literal pool.” What matters is this region of memory is placed immediately after (therefore nearby) your code.
Then, the assembler computes the difference between the address of the current instruction (the
ldritself) and the address of the data in the literal pool made from the labeled data.The assembler generates a different
ldrinstruction which uses the difference (or offset) of the data relative to the program counter (pc). Thepcis non-other the address of the current instruction.Because the literal pool for your code is located nearby your code, the offset from the current instruction to the data in the pool is a relatively small number. Small enough, to fit inside a four byte
ldrinstruction.
1 | ldr x1, [pc, offset to in literal pool] |
A downside of this approach is that the literal pool, from which the address is loaded, resides in RAM. This means each of these
ldrpseudo instructions incurs a memory reference.
literal pool
compare
1 | ldr x1, =q |
aarch64
1 | main // expose main to linker |
disasembling the binary machine code:
1 | 0000000000007a0 <main>: |
and
1 | 000000000011010 <q>: |
It says
000000000011010 <q>:. This means that what comes next is the data corresponding to what is labeledqin our source code. Notice the relocatable address of11010. We will explain “relocatable address” below.Now, look at the disassembled code on the line beginning with
7b8. It readsldr x1, 11010. So the disassembled executable is saying “go to address 11010 and fetch its contents” which are our1122334455667788.
| Instruction | Meaning |
|---|---|
| ldr r, =label | Load the address of the label into r |
| ldr r, label | Load the value found at the label into r |
relocation of address when executing
None of the addresses we have seen so far are the final addresses that will be used once the program is actually running. All addresses will be relocated.
One reason for this is a guard against malware. A technique called Address Space Layout Randomization (ASLR) prevents malware writers from being able to know ahead where to modify your executable in order to accomplish their nefarious purposes.
64 bit ARM Linux kernels allocate 39, 42 or 48 bits for the size of a process’s virtual address space. Notice 42 and 48 bit values require 6 bytes to hold them. A virtual address space is all of the addresses a process can generate / use. Further, all addresses used by processes are virtual addresses.
using this can avoid literal pool
1 | adrp x0, s |
examples
loading (storing) various sizes of integers
| Instruction | Meaning |
|---|---|
ldr x0, [x1] |
Fetches a 64 bit value from the address specified by x1 and places it in x0 |
ldr w0, [x1] |
Fetches a 32 bit value from the address specified by x1 and places it in w0 |
ldrh w0, [x1] |
Fetches a 16 bit value from the address specified by x1 and places it in x0 |
ldrb w0, [x1] |
Fetches an 8 bit value from the address specified by x1 and places it in x0 |
- Pointers and longs use
xregisters. - All other integer sizes use
wregisters where the instruction itself specifies the size.
array indexing
1 | long Sum(long * values, long length) |
Notice we’re using the index variable i for nothing more than traipsing through the array. This is fantastically inefficient (in this case).
1 | long Sum(long * values, long length) |
Notice we don’t use an index variable any longer. Instead, we use the pointer itself for both the dereferencing and to tell us when to stop the loop.
1 | Sum |
faster memory copy
Suppose you needed to copy 16 bytes of memory from one place to another. You might do it like this:
1 | void SillyCopy16(uint8_t * dest, uint8_t * src) |
This is especially silly as why would you go through 16 loops when you could have simply:
1 | void SillyCopy16(uint64_t * dest, uint64_t * src) |
in aarch64
1 | SillyCopy16: // 1 |
using ldp
1 | SillyCopy16: |
using q register
1 | SillyCopy16: |
indexing through an array of struct
1 |
|
Line 11 tells us that somewhere else, there is a function called FindOldestPerson. That function must have a .global specifying the same name so that the linker can reconcile the reference to FindOldestPerson.
gcc with -O2 or -O3 optimization rendered OriginalFindOldestPerson() into 18 lines of assembly language.
1 | FindOldestPerson // 1 |
control flow
cmp
compare
discards the result of the subtraction but keeps a record of whether or not the result was less than, equal to or greater than zero. It sets the condition bits
br
Branch to Register
1 | br <register> |
无条件跳转,类似于
1 | goto *(ptr) |
ble
Branch less or equal
bl
Branch with Link
跳转到一个函数(子程序)地址,并且保存返回地址到 x30 寄存器中(也叫 lr,Link Register)
cbz
Compare and Branch if Zero
1 | cbz <register>, <label> |
如果 <register> 中的值为 0,就跳转到 <label>。
否则继续执行下一条指令。
csel
Conditional Select
1 | csel <dest>, <src1>, <src2>, <condition> |
如果满足 <condition>,则将 <src1> 的值赋给 <dest>;
否则将 <src2> 的值赋给 <dest>。
examples:
1 | cmp w2, w5 |
这是无分支的条件赋值,比 if-else 更高效。
this is equal to
1 | w2 = (w2 > w5) ? w2 : w5; |
shift Opertations
lsl
Logical Shift Left
The LSL instruction performs multiplication by a power of 2.
lsr
Logical Shift Right
The LSR instruction performs division by a power of 2.
asr
Arithmetic Shift Right
The ASR instruction performs division by a power of 2, preserving the sign bit.
ror
rotate right
The ROR instruction performs a bitwise rotation, wrapping the bits rotated from the LSB into the MSB.
即:ROR 指令执行按位右旋转操作:从最低有效位(LSB)被旋转出来的位,会重新被放入到最高有效位(MSB)的位置中。
bit manipulation
mvn
mvn (Move Not) 作用是 将操作数按位取反(bitwise NOT)后,放入目标寄存器。
orr
orr (bitwise inclusive OR) 对两个操作数执行 按位或(bitwise OR) 运算,然后将结果写入目标寄存器
bfi
bfi (Bit Field Insert) 即“位字段插入”。
1 | bfi <Xd>, <Xn>, #<lsb>, #<width> |
<Xd>:目标寄存器(结果写到这里)<Xn>:源寄存器(从这里取低位的值)<lsb>:目标寄存器中开始插入的起始位(least significant bit 起始位)<width>:要插入多少位(宽度)
假设:
Xd = 0b1111 0000,Xn = 0b1011 (只用低 4 位),lsb=1,width=3
执行:
1 | bfi Xd, Xn, #1, #3 |
结果:
将 Xn 的低 3 位 011 插入 Xd 的位 1~3 上,替换原值
结果是 Xd = 1111 0110
ubfm
ubfm = Unsigned BitField Move
基本格式:
1 | ubfm <dst>, <src>, #lsb, #msb |
<dst>:目标寄存器
<src>:源寄存器
lsb:起始位(low bit index)
msb:结束位(high bit index)
这条指令从 src 中 提取一个无符号位字段(即一段连续的比特位),把它放到 dst 的低位(bit 0 开始),其他位清零或忽略
也就是说:
- 从 src 的第 lsb 位开始,取到 msb 位
- 将这段 bit 字段提取出来
- 右对齐放到 dst 的低位(bit 0)其他位全部清零
实例:
1 | ubfm w1, w2, #8, #15 |
- 从 w2 中提取 bit 8 到 bit 15(共 8 位)
- 把它放到 w1 的 bit 0~7
ubfiz
ubfiz (Unsigned Bit Field Insert Zeroed) 将一个无符号数的低位字段插入到另一个寄存器的指定位置,但目标寄存器在插入之前会被清零。
它其实是 ubfm(Unsigned Bit Field Move)的一个特化形式,和 UBFM 的语义类似。
指令格式:
1 | ubfiz <dst>, <src>, #lsb, #width |
简单来讲就是:ubfiz = 把 src 的低 width 位 插入到 dst 的 bit lsb 开始的位置,其余位置全部清零。
其中:
<src>:来源寄存器(如 w1)
<dst>:目标寄存器(如 w2),最终结果放在这里
lsb:目标中插入位置的起始 bit 位(从 0 开始)
width:要插入的位数(从 <src> 的最低位开始数)
目标寄存器其他位都会被清零。
举例说明:
1 | ubfiz w1, w1, #3, #5 |
含义如下:
- 从 w1 的 最低 5 位(bit 0 到 bit 4)提取出来
- 插入到目标(w1)寄存器的 bit 3 到 bit 7
- w1 的其他所有位(02 和 831)清零
other
adr
Address
adrp
Address of page
1 | .rodata |
- 作用:把符号
fmt所在的 4KB 对齐页的页地址加载到x0中。 adrp= Address of Page。- 它会忽略符号地址的低 12 位,只保留高位。
- 举例:如果
fmt地址是0x400123,那么adrp x0, fmt会将0x400000加载到x0。 adrp x0, fmt会将fmt地址向下取整到最近的 4KB 边界(即清除低 12 位)
为什么不直接用
ldr x0, =fmt?
- 在 ARM64 下,使用
ldr x0, =fmt可能隐式引入 文字常量池(literal pool),不利于可重定位代码,尤其是在动态链接或 PIE (Position Independent Executable) 环境下。 adrp+add是 推荐的可重定位代码写法(relocatable and PIC-compliant)。- Linux 下的动态链接器(ld.so)支持这种模式更好。
| 指令 | 含义 | 支持的偏移范围 | 常用于 |
|---|---|---|---|
adr |
获取当前指令附近的地址 | ±1MB | 局部跳转、临时变量等 |
adrp |
获取4KB 页对齐的高地址部分 | ±4GB(页对齐偏移) | 获取全局变量地址、字符串、常量表地址等 |
smaddl
Signed Multiply Add Long
两个 32 位整数(有符号) 相乘后,加上一个 64 位整数,结果保存在一个 64 位寄存器中。
1 | smaddl <Xd>, <Wn>, <Wm>, <Xa> |
执行如下操作:
1 | Xd = (int64_t)(int32_t)Wn * (int64_t)(int32_t)Wm + Xa; |
programming
if statement
if
1 | if (a > b) |
in aarch64
1 | // Assume value of a is in x0 |
- If
a > bthenx0 - x1will be greater than zero. - If
a == bthenx0 - x1will be equal to zero. - If
a < bthenx0 - x1will be less than zero.
ble means branch (a jump or goto) if the previous computation shows less than or equal to zero
a rule of thumb
In the higher level language, you want to enter the following code block if the condition is true.
In assembly language, you want to avoid the following code block if the condition is false.
temporary label
The target of the branch instruction is given as 1f. This is an example of a temporary label.
There are a lot of braces used in C and C++. Since labels frequently function as equivalents to { and }, there can be a lot of labels used in assembly language. But label is only a position label, it is not a scope
A temporary label is a label made using just a number. Such labels can appear over and over again (i.e. they can be reused). They are made unique by virtue of their placement relative to where they are being used.
1flooksforward in the code for the next label1.1blooks in thebackward direction for the most recent label1.
if / else
1 | if (a > b) |
There are two branches built into this code!
in aarch64:
1 | // Assume value of a is in x0 |
a complete example
1 | main |
Line 11 is one way of loading the address represented by a label. In this case, the label T corresponds to the address to the first letter of the C string “TRUE”. Line 15 loads the address of the C string containing “FALSE”.
The occurrences of .asciz on line 23 and line 24 are invocations of an assembler directive the creates a C string. Recall that C strings are NULL terminated. The NULL termination is indicated by the z which ends .asciz.
There is a similar directive .ascii that does not NULL terminate the string.
loop
while loop
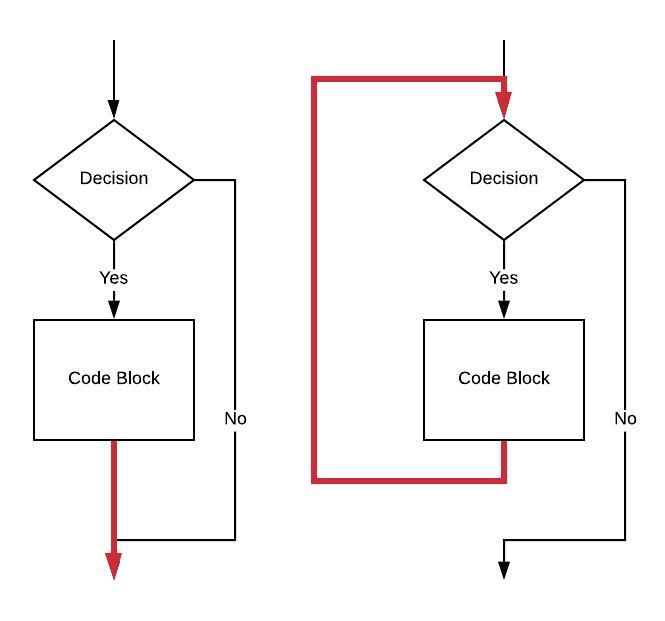
1 | while (a >= b) { |
aarch64:
1 | // Assume value of a is in x0 |
for loop
1 | for (set up; decision; post step) |
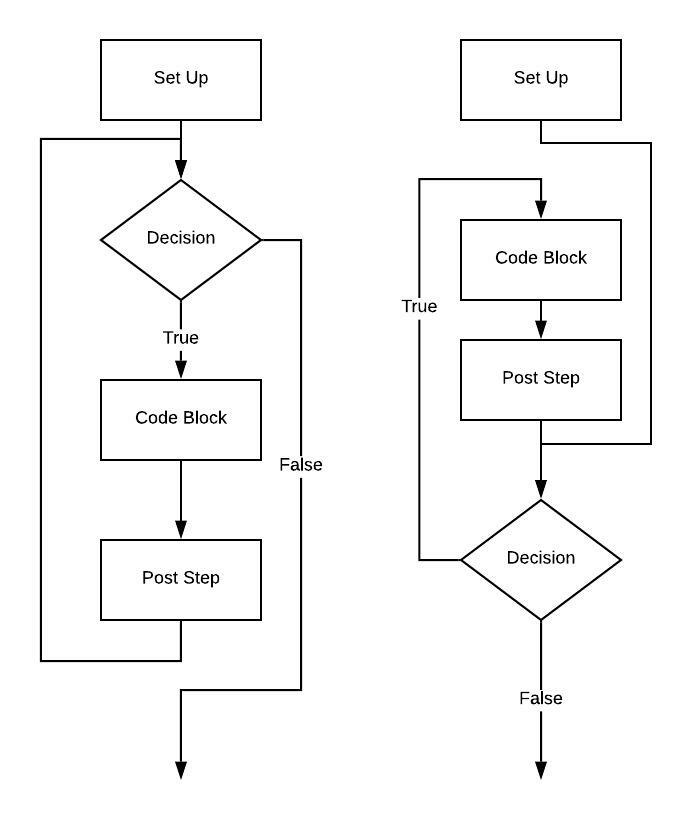
1 | for (long i = 0; i < 10; i++) |
aarch64 (the flow chart on the left)
1 | // Assume i is implemented using x0 |
aarch64 (the flow chart on the right)
1 | // Assume i is implemented using x0 |
continue
1 | for (long i = 0; i < 10; i++) { |
in aarch64
1 | // Assume i is implemented using x0 |
another one
1 | // Assume i is implemented using x0 |
break
The implementation of break is very similar to that of continue.
1 | for (long i = 0; i < 10; i++) { |
aarch64:
1 | // Assume i is implemented using x0 |
structs
alignment
Data members exhibit natural alignment.
That is:
- a
longwill be found at addresses which are a multiple of 8. - an
intwill be found at addresses which are a multiple of 4. - a
shortwill be found at addresses which are even. - a
charcan be found anywhere.
example
1 | struct { |
布局:
| Offset | Width | Member |
|---|---|---|
| 0 | 8byte | a |
| 8 | 2byte | b |
| 10 | 2 | – gap – |
| 12 | 4byte | c |
1 | struct Foo { |
A hex dump will show:
1 | aaaa aaaa aaaa aaaa bbbb 0000 cccc cccc |
Notice the gap filled in which zeros. Note, if this were a local variable, the zeros might be garbage.
change the order:
1 | struct Foo { |
A hex dump will show:
1 | aaaa 00bb cccc cccc |
Notice there is only one byte of gap before the int c starts.
why are the zeros to the left of the b’s?
This ARM processor is running as a little endian machine.
defining structs
1 | struct Foo { |
Here is one way of defining and accessing the struct:
- 硬编码字段偏移量
1 | .rodata |
:lo12:fmt 会被汇编器替换成 fmt 地址的低 12 位。
adrp x0, fmt 会将 fmt 地址向下取整到最近的 4KB 边界(即清除低 12 位),然后加载这个“页基址”到 x0。
例如:
如果 fmt = 0x12345678,那么:adrp x0, fmt 会得到 0x12345000(低 12 位清零)
- another way to define a structs is
使用 .equ 伪指令定义符号常量
1 | main // main 函数声明 |
- the third way:(Linux only)
使用 .struct 和字段标签自动推导偏移
1 | .rodata |
using structs
To summarize using structs:
- All
structshave a base address - The base address corresponds to the beginning of the first data member
- All subsequent data members are offsets relative to the first
- In order to use a
structcorrectly, you must have first calculated the offsets of each data member - Sometimes there will be padding between data members due to the need to align all data members on natural boundaries.
this pointer in c++
- Every non-static method call employs a hidden first parameter. That’s it. That’s the slight of hand. The hidden argument is the this pointer.
1 | TestClass tc; |
看起来我们只传入了一个参数 test_string。但实际上编译器传入了两个参数:
第一个是 this 指针:也就是 tc 的地址,传给寄存器 x0
第二个是 test_string,传给寄存器 x1
在汇编里看到:
1 | adrp x1, _test_string |
const
The meaning and function of
constonlypartiallytranslates to assembly language.
constlocal variables andconstparameters are just like any other data to assembly language.The constant nature of
constlocal variables and parameters is implemented solely in the compiler.constglobals are made constant by the hardware. Attempting to modify a variable protected in this manner will be like poking a dragon. Best not to poke dragons.
switch and jump table
When the C++ optimizer is enabled, it will look at your cases and choose between three different constructs for implementing your
switch.And, it can use any combination of the following! Compiler writers are smart!
- It may emit a long string of
if / elseconstructs. - It may find the right
caseusing a binary search. - Finally, it might use a jump table.
Suppose our cases are largely consecutive. Given that all branch instructions are the same length in bytes, we can do math on the switch variable to somehow derive the address of the case we want.
1 |
|
Notice that the case values are all, in this case, consecutive.
1 | jt: b 0f |
f means forward, b means backward
At address jt there are a sequence of branch statements… jumps if you will. Being in a sequence, this is an example of a jump table. We’ll compute the index into this array of instructions and then branch to it.
1 | lsl x0, x0, 2 |
- Line 2 loads the base address of the “instruction array” starting at address
jt.
complete example
1 |
|
implement falling through
If there is no break falling the code for a case, control will simply fall through to the next case
Here is a snippet from the program linked just above
1 | 0: ldr x0, =ZR |
implementing gaps
The example above present shows 8 consecutive cases. What if there was no code for case 4? In other words, what if case 4 didn’t exit?
Here is the result:
1 | 2: ldr x0, =TW |
other strategies for implementing switch
As indicated above, an optimizer has at least three tools available to it to implement complex switch statements. And, it can combine these tools.
- For example, suppose your cases boil down to two ranges of fairly consecutive values. For example, you have cases 0 to 9 and also cases 50 to 59. You can implement this as two jump tables with an
if / elseto select which one you use.
假设你的 switch 语句中,case 值主要集中在两个小的连续范围内,例如:一组是 case 0 到 case 9,另一组是 case 50 到 case 59,那么可以用 两个跳转表 来处理这两个范围,再用一个 if / else 来决定使用哪一个跳转表。
- Suppose you have a large
switchstatement with widely rangingcasevalues. In this case, you can implement a binary search to narrow down to a small range in which another technique becomes viable to narrow down to a singlecase.
假设你有一个包含很多 case 分支的 switch 语句,而且这些 case 值之间的数值范围差异很大,比如 case 10, case 1000, case 50000…,那么可以先用二分查找法缩小查找范围,把目标值限制在一个较小的范围内,然后在这个范围内再用其他技术(比如跳转表、线性比较等)来确定最终对应哪个 case 分支。
- You might have need to implement hierarchical jump tables(分层跳转表), for example.
“分层跳转表”是一种优化结构,适用于以下情况:
case值非常稀疏、范围极广(例如case 0, case 1000, case 2000...)- 但它们在局部范围内是稠密的(比如
1000~1009,2000~2009)
你可以:
- 先用一个“一级跳转表”根据高位或区段跳转到一个子跳转表(子范围)。
- 再在子跳转表中做具体跳转。
这就构成了一个“分层结构”——像树一样的跳转过程。
strategies for implementing if-else
If you do choose to implement a long chain of if / else statements, consider how frequently a given case might be chosen. Put the most common cases at the top of the if / else sequence.
This is known as making the common case fast.
Making the common case fast is one of the Great Ideas in Computer Science. One, you would do well to remember no matter what language you’re working with.
fucntions
bottom line concept
The bl instruction is stands for Branch with Link. The Link concept is what enables a function (or method) to return to the instruction after the call.
Branch-with-link computes the address of the instruction following it.
It places this address into register
x30and then branches to the label provided. It makes one link of a trail of breadcrumbs to follow to get back following aret.
This is why it is absolutely essential to backup x30 inside your functions if they call other functions themselves.
a example
1 |
|
The program hung and had to be killed with ^C.
Somebody called main() - it’s a function and someone called it with a bl instruction. At the moment main() entered, the address to which it needed to return was sitting in x30.
Then, main() called a function - in this case puts() but which function is called doesn’t matter - it called a function. In doing so, it overwrote the address to which main() needed to return with the address of line 7 in the code. That is where puts() needs to return.
So, when line 7 executes it puts the contents of x30 into the program counter and branches to it.
Here is a fixed version of the code:
1 |
|
In the AARCH64 Linux style calling convention, values are returned in x0 and sometimes also returned in other scratch registers though this is uncommon.(Note that x0 could also be w0 or the first floating point register if the function is returning a float or double.)
If your functions call any other functions, x30 must be backed up on the stack and then restored into x30 before returning.
A function with more than one return value is not supported by C or C++ but they can be written in assembly language where the rules are yours to break.
inline functions
Functions that are declared as inline don’t actually make function calls. Instead, the code from the function is type checked and inserted directly where the “call” is made after adjusting for parameter names.
passing parameters to functions
How parameters are passed to functions can be different from OS to OS. This chapter is written to the standard implemented for Linux.
For the purposes of the present discussion, we assume all parameters are long int and are therefore stored in x registers.
Up to 8 parameters can be passed directly via scratch registers.(These are
x0throughx7) Each parameter can be up to the size of an address, long or double (8 bytes).Scratch means the value of the register can be changed at will without any need to backup or restore their values across function calls.
This means that you cannot count on the contents of the scratch registers maintaining their value if your function makes any function calls.
a example
1 | long func(long p1, long p2) |
is implemented as:
1 | func: add x0, x0, x1 |
If you are the author of both the caller and the callee and both are in assembly language, you can play loosey goosey with how you return values. Specifically, you can return more than one value. But if you do so, you give up the possibility of calling these functions from C or C++.
const
1 | long func(const long p1, const long p2) |
how would the assembly language change?
Answer: no change at all!
const is an instruction to the compiler ordering it to prohibit changing the values of p1 and p2. We’re smart humans and realize that our assembly language makes no attempt to change p1 and p2 so no changes are warranted.
passing pointers
1 | void func(long * p1, long * p2) |
1 | func: ldr x2, [x0] |
The value of x0 on return is, in the general sense, undefined because this is a void function.
passing reference
1 | long func(long & p1, long & p2) |
1 | func: ldr x0, [x0] |
Passing by reference is also an instruction to the compiler to treat pointers a little differently - the differences don’t show up here so there the only change to our pointer passing version is how we return the answer.
more than eight parameters
1 |
|
1 |
|
After executing Line 24, the stack will have:
1 | sp + 0 former contents of frame pointer |
After executing Line 27, the stack will have:
1 | sp + 0 9 |
After executing Line 14, the stack will have:
1 | sp + 0 return address for SillyFunction |
This means that Line 18 fetches p9 from memory and puts its value into x2 (where it becomes the third argument to printf()).
在 AArch64 中,栈空间常常是 以 16 字节为单位对齐分配的,但你可能 只写了其中的一部分数据,剩下的就没有被初始化,于是我们称它为 “garbage”(未定义的内容)。
The stack pointer in ARM V8 can only be manipulated in multiples of 16.
The stack pointer in ARM V8 can only be manipulated in multiples of 16.
The stack pointer in ARM V8 can only be manipulated in multiples of 16.
examples of calling some common C runtime functions
There are, by the way, two broad types of functions within the C runtime.
Some are implemented largely in the C runtime itself.
Others that exist in the C runtime act as wrappers for functions implemented within the OS itself. These are called “system calls”.
For the purposes of calling functions in the C runtime, there is no practical difference between these two types. Note however, there are ways of calling system calls directly using the svc instruction.
“C runtime”(C 运行时)指的是一组在程序运行时提供支持的函数、变量和基础机制,主要用于支持 C 语言标准库和程序的初始化/终止。这套系统通常被称为 C runtime library(C 运行时库),在不同平台中常见的实现有:
- GNU/Linux 下的 glibc
- Windows 下的 MSVCRT
- macOS 下的 libSystem.dylib(包含 libc)
C runtime 做了哪些事?
- 程序初始化
- 在
main()执行之前,C runtime 会设置好堆栈、初始化全局变量、调用构造函数等。 - 典型入口点是
_start→__libc_start_main()→main()。
- 在
- 提供标准库函数
- 如
printf(),malloc(),exit(),fopen()等,这些函数由 C runtime 实现或封装。
- 如
- 管理资源
- 比如内存分配、文件句柄、线程等的生命周期管理。
- 提供系统调用封装
- 比如你调用
write(),它其实是调用了一个 C runtime 提供的 wrapper,最终通过syscall或svc指令访问内核。
- 比如你调用
system calls
Many C runtime functions are just wrappers for system calls. For example if you call open() from the C runtime, the function will perform a few bookkeeping operations and then make the actual system call.
What IS a system call?
The short answer is a system call is a sort-of function call that is serviced by the operating system itself, within its own private region of memory and with access to internal features and data structures.
Our programs run in “userland”. The technical name for userland on the ARM64 processor is EL0 (Exception Level 0).
We can operate within the kernel’s space only through carefully controlled mechanisms - such as system calls. The technical name for where the kernel (or system) generally operates is called EL1.
There are two higher Exception Levels (EL2 and EL3) which are beyond the scope of this book.
Mechanism of making a system call
First, like any function call, parameters need to be set up. The first parameter goes in the first register, etc.
Second, a number associated with the specific system call we wish to make is loaded in a specific register (w8).
Finally, a special instruction svc causes a trap which elevates us out of userland into kernel space. Said differently, svc causes a transition from EL0 to EL1. There, various checks are done and the actual code for the system call is run.
A description of returning from a system call is beyond the scope of this book. Hint: just as there’s a special instruction that escalates from EL0 to EL1, there is a special instruction that does the reverse.
the number associated with a particular system call
reference:
example getpid()
1 |
|
Written in assembly language using C runtime
1 | main |
And finally: calling the system call directly
1 | main |
We chose getpid() because it doesn’t require any parameters. Using the C runtime, we simply bl to it. Calling the system call directly is different in that we must first load x8 with the number that corresponds to getpid() for the AARCH64 architecture.
1 | /* Perry Kivolowitz |
floating point
what are floating points numbers?
reference

IEEE 754
register
There are four highest level ideas relating to floating point operations on AARCH64.
- There is another complete register set for floating point values.
- There are alternative instructions just for floating point values.
- There are exotic instructions that operate on sets of floating point values (SIMD).
- There are instructions to go back and forth to and from the integer registers.
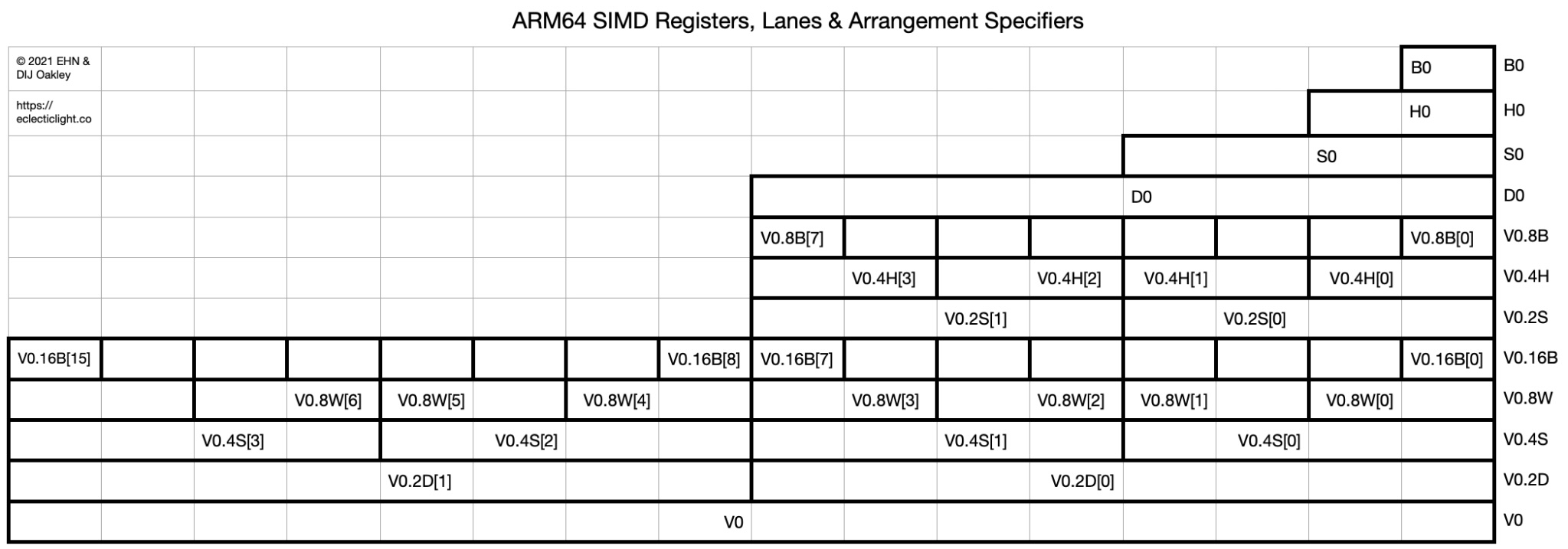
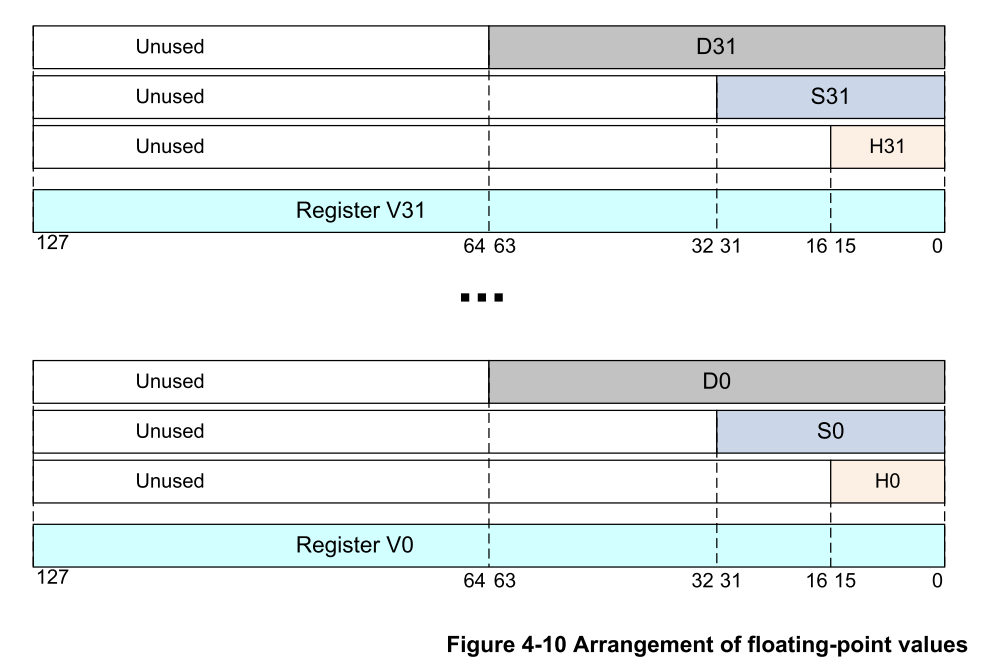
上图展示了 ARM64 架构中 SIMD(Single Instruction, Multiple Data)寄存器 V0 的不同视图与访问方式,包括不同位宽的排列方式(Arrangement Specifiers)与 Lane(通道)索引。
图解说明
这个图以 V0 寄存器为例,展示了 如何用不同的排列方式访问其内容:
| 层级 | 类型 | 说明 |
|---|---|---|
| 最底层 | V0 |
整个 128-bit 的 V0 寄存器 |
| 向上 | V0.2D, V0.4S, V0.8H, V0.16B |
以不同大小的数据视图访问 V0: - D = 64-bit(2 × 64bit) - S = 32-bit(4 × 32bit) - H = 16-bit(8 × 16bit) - B = 8-bit(16 × 8bit) |
| 再上 | V0.2D[0], V0.4S[0] 等 |
每个 lane 的索引,比如: - V0.4S[2] 表示第 3 个 32-bit 单元- V0.16B[15] 表示第 16 个 8-bit 字节 |
| 最上层 | B0, H0, S0, D0 |
是对 V0 的 alias,按位宽访问(只访问最低位的数据) |
truncation towards zero
truncate(截断)
In C and C++, truncation is what we get from:
1 | integer_variable = int(floating_variable); // C++ |
The instruction is fcvtz - convert towards zero. Then, the choice as to whether to produce a signed or unsigned result is defined by the final letterL u or s.
| Mnemonic | Meaning |
|---|---|
| fcvtzu | Truncate (always towards 0) producing an unsigned int |
| fcvtzs | Truncate (always towards 0) producing a signed int |
fcvtzu: Float Convert to Unsigned integer, with truncation toward zerofcvtzs: Float Convert to Signed integer, with truncation toward zero
this instruction which completely discards the fractional value is said by the ARM documentation as doing rounding not truncating.
The the choice of source register defined whether you are converting a double or single precision floating point value.
| Source Register | Converts a |
|---|---|
| dX | double to an integer |
| sX | float to an integer |
| Destination Register | Converts a |
|---|---|
| xX | 64 bit integer |
| wX | 32 bit or less integer |
Examples where d is a double and f is a float:
| C++ | Instruction |
|---|---|
int32_t(d) |
fcvtzs w0, d0 |
uint32_t(d) |
fcvtzu w0, d0 |
int64_t(d) |
fcvtzs x0, d0 |
uint64_t(d) |
fcvtzu x0, d0 |
example
1 |
|
Notice all the values were truncated to the whole number that is closer to zero.
Truncation Away From Zero
Truncation away from zero is not as easy. In fact, it cannot be performed with a single instruction.
In C (and C++):
1 | iv = (int(fv) == fv) ? int(fv) : int(fv) + ((fv < 0) ? -1 : 1); |
If the fv is already equal to a whole number, the integer value will be that whole number. Other wise the iv is the whole number further away from zero.
In C++, a more sophisticated version would require
1 | template <typename T> |
floor() always truncates downward (towards more negative).
ceil() always truncates upwards (towards more positive).
1 | RoundAwayFromZero: |
frintp(Round toward +∞)frintm(Round toward -∞)frintz(Round toward 0)frinta(Round to nearest, tie away from 0)frintn(Round to nearest, tie to even)
rounding conversion
rounding(四舍五入)
An instruction which does what we normally think of as rounding is frinta. This is the conversion “to nearest with ties going away.” So, 5.5 goes to 6 as one would expect from “rounding.”
converting an integer to a float point value
In C / C++:
1 | double_var = double(integer_var); // C++ |
Is handled by two instructions:
scvtfconverts a signed integer to a floating point valueucvtfconverts an unsigned integer to a floating point value
The name of the destination register controls which kind of floating point value is made. For example, specifying dX makes a double etc.
floating point literals
Recall that all AARCH64 instructions are 4 bytes long. Recall also that this means that there are constraints on what can be specified as a literal since the literal must be encoded into the 4 byte instruction. If the literal is too large, an assembler error will result.
Given that floating point values are always at least 4 bytes long themselves, using floating point literals is extremely constrained. For example:
1 | fmov d0, 1 // 1 |
Line 1 will pass muster but Line 2 will cause an error.
To load a float, you could translate the value to binary and do as the following:
1 |
|
printf() only knows how to print double precision values. When you specify a float, it will convert it to a double before emitting it.
Translating floats and doubles by hand isn’t a common practice for humans, though compilers are happy to do so.
Instead for us humans, the assembler directives .float and .double are used more frequently to specify float and double values putting them into RAM.
a example:
1 | main |
| 指令 | 全称/缩写 | 作用 | 常见用法示例 |
|---|---|---|---|
.req |
register require(非官方缩写) | 给寄存器起别名 | foo .req x0 表示以后写 foo 就等于 x0 |
.equ |
equate | 定义一个常量符号 | BUF_SIZE .equ 64 表示 BUF_SIZE = 64 |
On Linux, just as w/x0 through w/x7 are scratch registers and used to pass parameters, s/d0 and s/d7 are as well beginning with the 0 register。即:
- 整数参数传递:x0 ~ x7(或 32 位的 w0 ~ w7)用于传递前 8 个整数类参数(int、pointer、long 等)。超过 8 个就通过栈传递。
- 浮点参数传递:d0 ~ d7(64 位 double 类型)或 s0 ~ s7(32 位 float 类型)用于传递前 8 个浮点参数。超过 8 个浮点参数也是通过栈传递。
Fitting 32 bits into a 32 bit bag
1 | ldr s0, =0x3fc00000 // 伪指令!我们以为它直接把 0x3fc00000 加载进 s0 |
编译器不能直接把任意 32 位值硬编码进指令中(因为一条 ARM 指令本身就只有 32 位)。
所以它实际上是:
- 将字面量值 0x3fc00000 写到内存的某个地方(通常靠近当前函数底部)。
- 生成一条 ldr 指令,用 PC-relative load 的方式从这个地址加载该值。这块被称为一个 literal pool,它是一些常量的集合。
We expected line 6 to read:
1 | ldr s0, =0x3fc00000 |
Instead we find:
1 | b+ 0x784 <main+4> ldr s0, 0x7a0 <main+32> |
Scan downward to find 0x7a0:
1 | 0x7a0 <main+32> .inst 0x3fc00000 ; undefined |
| 伪指令 | 实际效果 | GDB 中看到的实际汇编 |
|---|---|---|
ldr s0, =0x3fc00000 |
把常量加载进 s0 寄存器 |
ldr s0, #literal_addrliteral_addr: .inst 0x3fc00000 |
ldr x0, =fmt |
加载字符串指针地址 | ldr x0, #literal_addrliteral_addr: .inst 地址值 |
.inst 0x3fc00000 |
手动插入一个 32 位数据(不一定是有效指令) | 存放常量(不是执行) |
.inst 的含义:
- 全称:
.inst= insert instruction - 用途:直接插入一条 ARM 指令的机器码(通常是 32 位十六进制值)
1 | .inst 0xd65f03c0 // 实际是 ret 指令 |
这个例子中,.inst 后的机器码 0xd65f03c0 是 ret 指令的 32 位编码。也就是说:
1 | ret |
等价于:
1 | .inst 0xd65f03c0 |
在上面的例子中,可以用.inst定义一个地址,从该地址中加载
为什么不用 mov reg, #imm ?
- mov 有立即数编码限制,不能加载任意 32 位值。
- 超过范围时,必须用 ldr 从内存加载。
fmov
The fmov instruction is used to move floating point values in and out of floating point registers and to some degree, moving data between integer and floating point registers.
loading floating point numbers as immediate values
Just as we saw with integer registers, some values can be used as immediate values and some cannot. It comes down to how many bits are necessary to encode the value. Too many bits… not enough room to fit in a 4 byte instruction plus the opcode.
For example, this works:
1 | mov x0, 65535 |
but this does not:
1 | mov x0, 65537 |
The constraints placed on immediate values for fmov are much tighter because floating point numbers are far more complex than integers.
fmov d0, #imm 能否工作,取决于该浮点数是否能在 8 位编码空间内被精确表示:
| 结构 | 位数 | 说明 |
|---|---|---|
| 符号位 | 1 bit | 表示正或负 |
| 指数部分 | 3 bits | 控制大小(乘以 2 的幂) |
| 尾数部分 | 4 bits | 仅能由 1/2、1/4、1/8、1/16 组合构成 |
1 | fmov d0, 1.0 // ✅ OK:整数 1 是 2⁰,指数可编码 |
大浮点不能用 fmov,改用 ldr。
fmov 是“位复制器”,不是“精度转换器”。如果要改数值精度,就必须用 fcvt 系列。
half precision
Support for half precision (16 bit) floating point values does exist but there is no complete agreement on how different compilers support them. Indeed, there are not one but two competing half precision formats out there. These are the IEEE and GOOGLE types. Further still, many open source developers have created their own implementations with potentially clashing naming conventions.
1 | __fp16 Foo(__fp16 g, __fp16 f) { |
compiles to:
1 | fcvt s1, h1 |
Notice each half precision value is converted to single precision. So, from C and C++ working with half precision values can be inefficient.
On the other hand, if you are willing to use intrinsics and one of the SIMD instruction sets offered by ARM, then knock yourself out. Be aware that doing so ties your code to the ARM processor in ways which you might regret later.
bit manipulation
Bit fields are a feature of the C and C++ language which completely hide what is often called “bit bashing”.
the ordering of bits in a bit field is not guaranteed to be the same on different platforms and even between different compilers on the same platform.
位域是一种用来在结构体内 精确控制成员所占二进制位数 的语法,通常用于硬件寄存器、协议头等空间敏感的场景。
语法格式
1 | struct 结构体名 { |
example:
1 | struct BF { |
- a 用 1 位,能表示 0 或 1
- b 用 2 位,能表示 0 ~ 3
- c 用 5 位,能表示 0 ~ 31
三个成员总共占 1 + 2 + 5 = 8 位,即 1 字节
- 虽然每个成员是个位宽,但整体大小通常向整型对齐(这里是 1 字节,因为 8 位正好一字节)。
- 不同编译器对位域对齐和填充细节可能略有差异。
- 访问时可以像普通成员一样:
1 | struct BF bf; |
编译器会自动对位域进行掩码和移位处理。
Consider a data structure for which there will be potentially millions of instances in RAM. Or, perhaps billions of instances on disc. Suppose you need 8 boolean members in every instance. The C++ standard does not define the size of a bool instead leaving it to be implementation dependent. Some implementations equate bool to int, four bytes in length. Some implement bool with a char, or 1 byte in length.
Let’s assume the smallest case and equate a bool with char. Our struct, for which there may be millions or billions of instances requires 8 bool so therefore 8 bytes. Times millions or billions.
Bit fields can come to your aid here by using a single bit per boolean value. In the best case, 8 bytes collapse to 1 byte. In a worse case, 8 x 4 = 32 bytes collapsed into 1.
假设使用最小单位,即每个 bool 是 1 字节:
1 | struct S { |
这个结构体大小为 8 字节(1 字节 × 8 个 bool)。如果有百万个实例,占用的内存就是 8MB,如果有十亿个实例,则是 8GB。对于 4 字节的 bool 实现,则大小直接变成 32 字节,每亿实例就是 3.2GB。
解决方案:使用位域压缩布尔值
用位域,将 8 个布尔值定义为 1 位大小:
1 | struct S { |
8 个 1-bit 成员 合起来正好占 1 字节。
这样 8 字节压缩成 1 字节,节省了大量空间。
In Computer Science there is an eternal tension between space and time. The following is a law:
If you want something to go faster, it will cost more memory.
If you want to save memory, what you’re doing will take more time.
This law shows up here… recall the example of where we wanted to save memory by collapsing 8 bool into 1 byte? To save that memory we will slow down because accessing the right bits takes a couple of instructions where overwriting a bool implemented as an int takes just one instruction.
As for the assembly language that bit field will produce, it depends upon optimization level. Unoptimized, the code produced will be much longer and cumbersome than the “sophisticated” assembly language.
endian
the ARM swing both ways: the litte-endian and the big-endian. But:
The standard toolchain emits little endian code. It is a big task to install the big-endian version of the toolchain.
Here is a quote from Wikipedia:
1 | ARM, C-Sky, and RISC-V have no relevant big-endian deployments, and can be considered little-endian in practice. |
The common Intel processors are also little-endian.
assembly macros
An early innovation in assemblers was the introduction of a macro capability. Given what could be considered a certain amount of tedium in coding in asm, macros provide a simple form of meta programming where a series of statements can be encapsulated by a single macro. Think of a macro as an early form of C++ templated function (kinda but not really).
Here’s an example of an assembly language macro:
1 | .macro LLD_ADDR xreg, label |
This gets expanded to:
1 | adrp x0, fmt@PAGE |
gcc on Linux does not run assembly language files through the C pre-processor if the asm file ends in .s but WILL if the file ends in .S
Genaral Use
AASCIZ
AASCIZ label, string
This macro invokes .asciz with the string set to string and the label set to label. In addition, this macro ensures that the string begins on a 4-byte-aligned boundary.
PUSH_P, PUSH_R, POP_P and POP_R
These macros save some repetitive typing. For example:
1 | PUSH_P x29, x30 |
resolves to:
1 | stp x29, x30, [sp, -16]! |
START_PROC and END_PROC
Place START_PROC after the label introducing a function.
Place END_PROC after the last ret of the function.
These resolve to: .cfi_startproc and .cfi_endproc respectively.
MIN and MAX
Handy more readable macros for determining minima and maxima. Note that the macro performs a cmp which subtracts src_b from src_a (discarding the results) in order to set the flags to be interpreted by the following csel.
Signature:
1 | MIN src_a, src_b, dest |
The smaller of src_a and src_b is put into dest.
Signature:
1 | MAX src_a, src_b, dest |
The larger of src_a and src_b is put into dest.
MOD
MOD macro used above is defined as:
1 | .macro MOD src_a, src_b, dest, scratch |
GLABEL
Mark a label as global, Makes a label available externally.
Signature:
1 | GLABEL label |
An underscore is prepended.
CRT
Calling CRT(C runtime) functions
If you create your own function without an underscore, just call it as usual.
If you need to call a function such as those found in the C runtime library, use this macro in this way:
1 | CRT strlen |
MAIN
Declaring main()
Put MAIN on a line by itself. Notice there is no colon.
errno
The externally defined errno is accessed via a CRT function which isn’t seen when coding in C and C++. The function is named differently on Mac versus Linux. To get the address of errno use:
1 | ERRNO_ADDR |
This macro makes the correct CRT call and leaves the address of errno in x0.
Loads and Stores
GLD_PTR
Loads the address of a label and then dereferences it where, on Apple the label is in the global space and on Linux is a relatively close label.
Signature:
1 | GLD_PTR xreg, label |
When this macro finishes, the specified x register contains what 64 bit value lives at the specified label.
GLD_ADDR
Loads the address of the label into the specified x register. No dereferencing takes place. On Apple machines, the label will be found in the global space.
Signature:
1 | GLD_ADDR xreg, label |
When this macro completes, the address of the label is in the x register.
LLD_ADDR
Similar to GLD_ADDR this macro loads the address of a “local” label.
Signature:
1 | LLD_ADDR xreg, label |
When this macro completes, the address of the label is in the x register.
LLD_DBL
Signature:
1 | LLD_DBL xreg, dreg, label |
When this macro completes, a double that lives at the specified local label will sit in the specified double register.
LLD_FLT
Signature:
1 | LLD_FLT xreg, sreg, label |
When this macro completes, a float that lives at the specified local label will sit in the specified single precision register.
performance
Undoing Stack Pointer Changes
A small tip concerning undoing changes to the stack pointer. You might think that changes to the stack made by str or stp and their cousins must be undone with ldr or ldp and their cousins.
This depends.
If you need to get back the original contents of a register pushed onto the stack, then an ldr or ldp is appropriate. However, if you don’t need to get the original contents of a register back, then it is faster to undo a change to the stack using addition.
Take for example the use of printf(). On Apple Silicon systems, you must send arguments to printf() by pushing them onto the stack. However, when printf() completes, you have no need for the values that you pushed. As shown above, simply add the right (multiple of 16) to the stack pointer. This is faster as the addition makes no reference to RAM (or caches) as the ldr would.
other stuff
let the assembler itself calculate the length for you
1 | main |
atomic operations
Load Linked, Store Condition
1 |
|
LL/SC 是一种乐观并发控制机制。它大致逻辑是:
Load-Linked(LDAXR):加载一个地址的值,并“观察”该地址是否被改动。你可以修改这个值(如加 1)。
Store-Conditional(STLXR):尝试写这个新值,如果在这之间地址内容没有被别人改过,则写入成功;否则失败。成功与否会通过 STLXR 的返回值告诉你(0 表示成功,非 0 表示失败)。
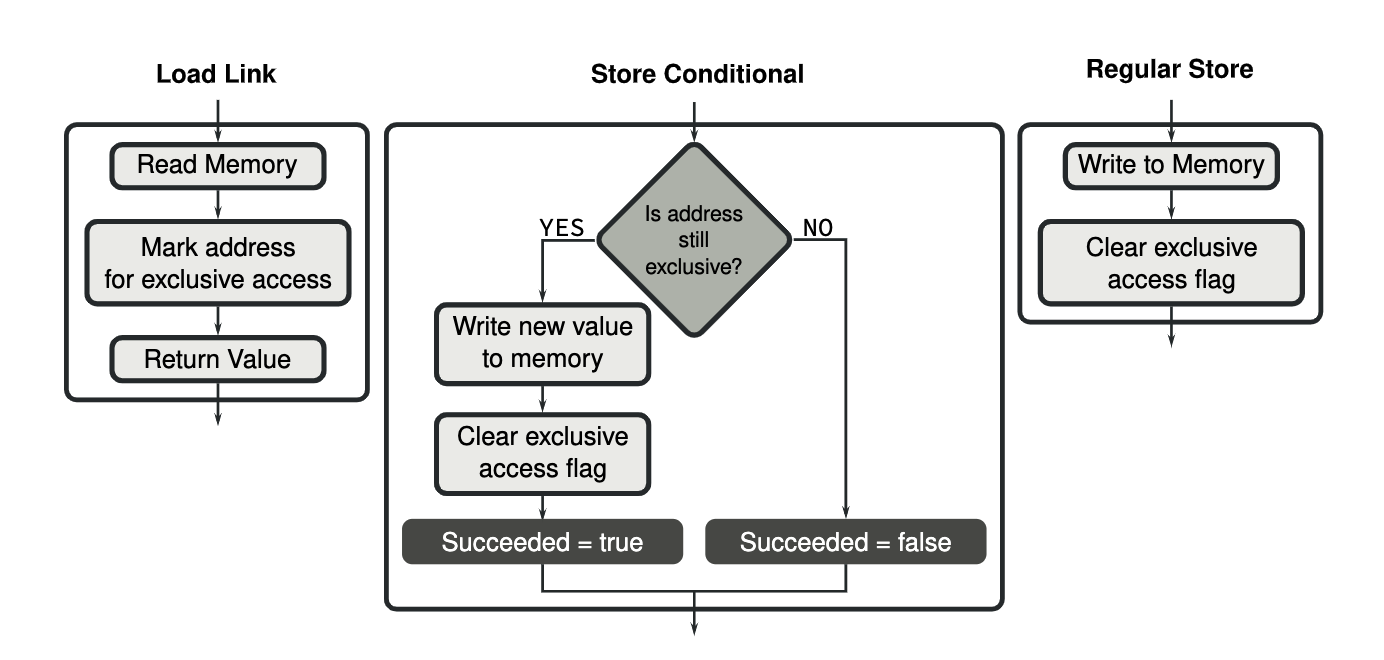
Implementations of operations on atomic variables were improved in the second version of ARMv8, called ARMv8.1. The load linked and store conditional instructions are still available but several new instructions were added which perform certain operations such as addition, subtraction and various bitwise operations in a single atomic instruction.
For example:
1 | mov w1, 1 |
does the same work of atomically adding one to the value in memory pointed to by x0.
spin-lock
Here is the source code to the spin-lock for ARM V8.
Lock
1 | Lock: |
stlxr: 如果 exclusive tag 还有效(没人抢走锁),那么将 w3 的值写入 *x0,并将结果放入 w2(0 表示成功)
- ldaxr dereferencing the lock itself (once again an int32_t) and marks the location of the lock as being hopefully, exclusive.
- Having gotten the value of the lock, its value is inspected and if found to be non-zero, we branch back to attempting to get it again - this is the spin.
- If the contents of the lock is 0, its value in w1 is changed to non-zero. Note, this could be made a bit better if a value of 1 was stored in another w register and simply used directly on line 10.
stlxr w2, w3, [x0]conditionally stores the changed value back to the location of the lock. If the stlxr returns 0, we got the lock. If not, we start over - somebody else got in there ahead of us. Perhaps this happened because we were descheduled. Perhaps we lost the lock to another thread running on a different core.
unlock
1 | Unlock: |
All it does is set to value of the lock to zero. The correct operation of the lock requires that no bad actor simply stomps on the lock by calling Unlock without first owning the lock. Just say no to lock stompers.
dmb ishsets up a data memory barrier across each processor - it makes sure threads running on different cores see the update correctly. This code seemed to work without this line but intuition suggests it could be important. In Lock() the stlxr instruction has an implied data memory barrier.
总结(伪代码角度)
- Lock(x0):
1 | do { |
- Unlock(x0):
1 | *x0 = 0; // unlock |