ARM CHI
时间轴
2025-10-31
init
参考文档:

CHI总线
是 AMBA 5 中定义的第五代协议,是 ACE 的进化版,专为高性能、多核处理器系统设计,支持更复杂的缓存一致性管理和大规模系统集成,适用于需要高性能和复杂缓存一致性管理的大规模多核系统场景。
文档:
- AMBA 5 CHI Architecture Specification,issue E.b
- Arm CoreLink CI-700 Coherent Interconnect Technical Reference Manual
- CHI(Coherent Hub Interface)是下一代的硬件缓存一致性协议,目标适应不同数量的处理器和外设
- 小系统:嵌入式
- 中等系统:手机
- 大系统:data center
- Cache一致性协议与ACE类似
- 支持分层设计
- 协议层
- 传输层
- 链路层
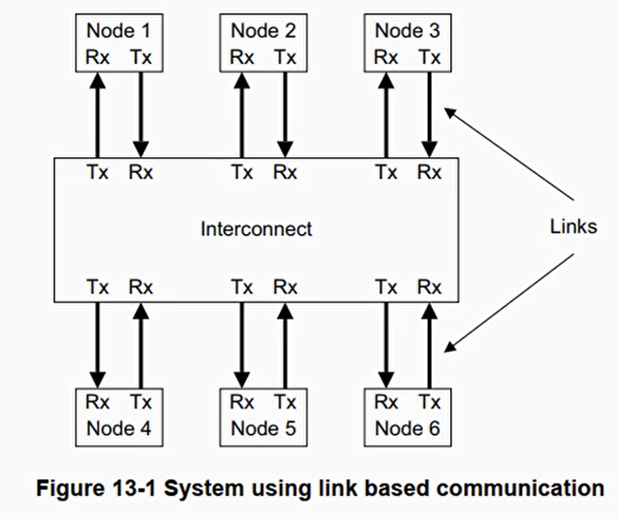
常见的总线连接结构
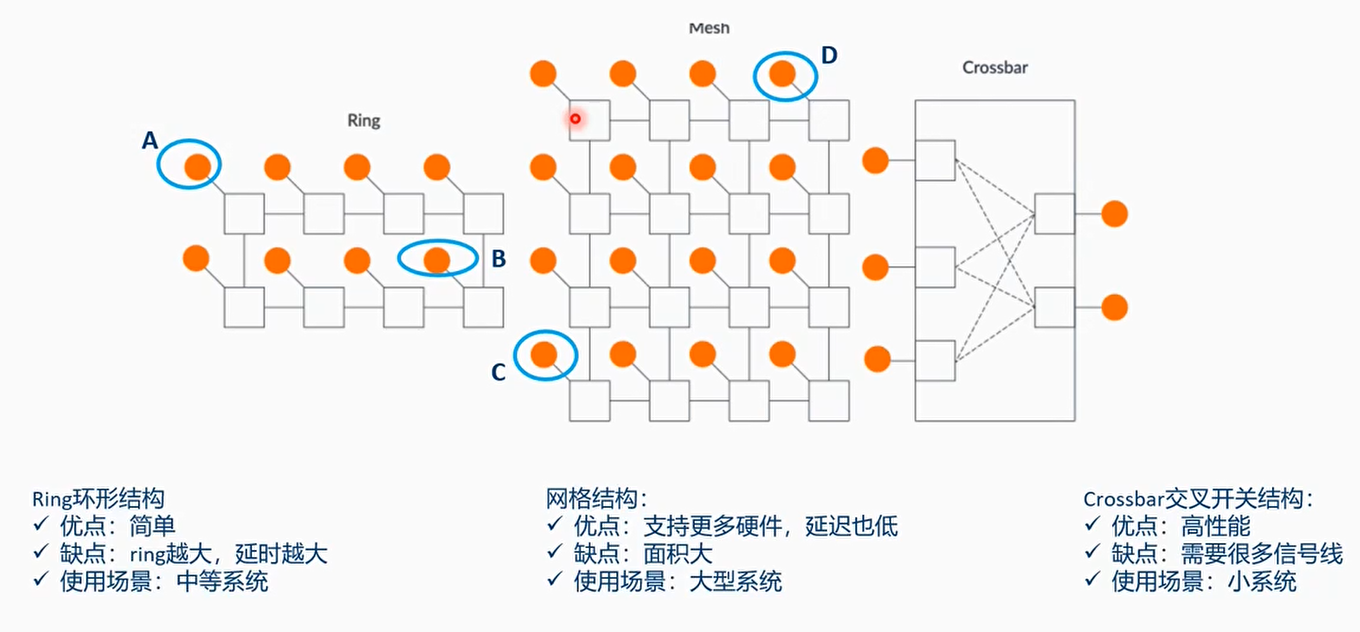
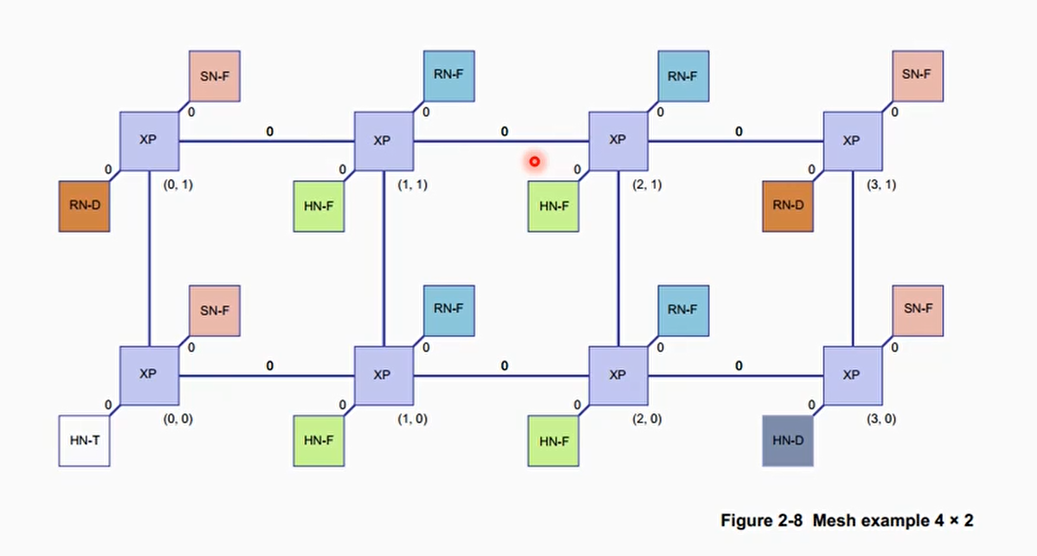
网格(mesh)结构:CI-700或者CMN-600
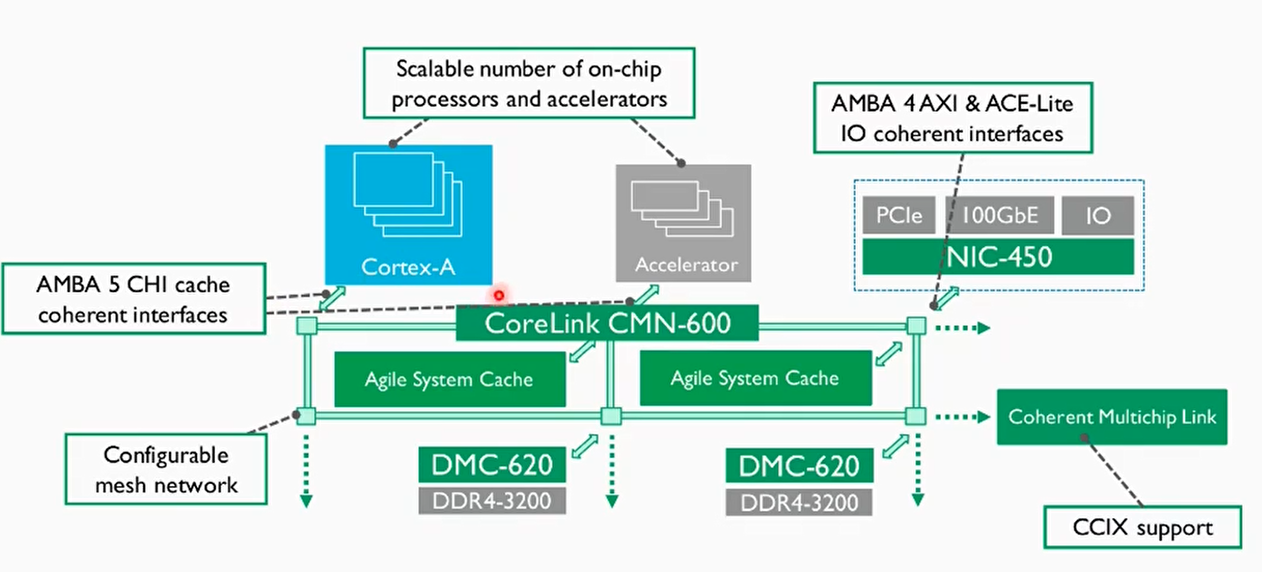
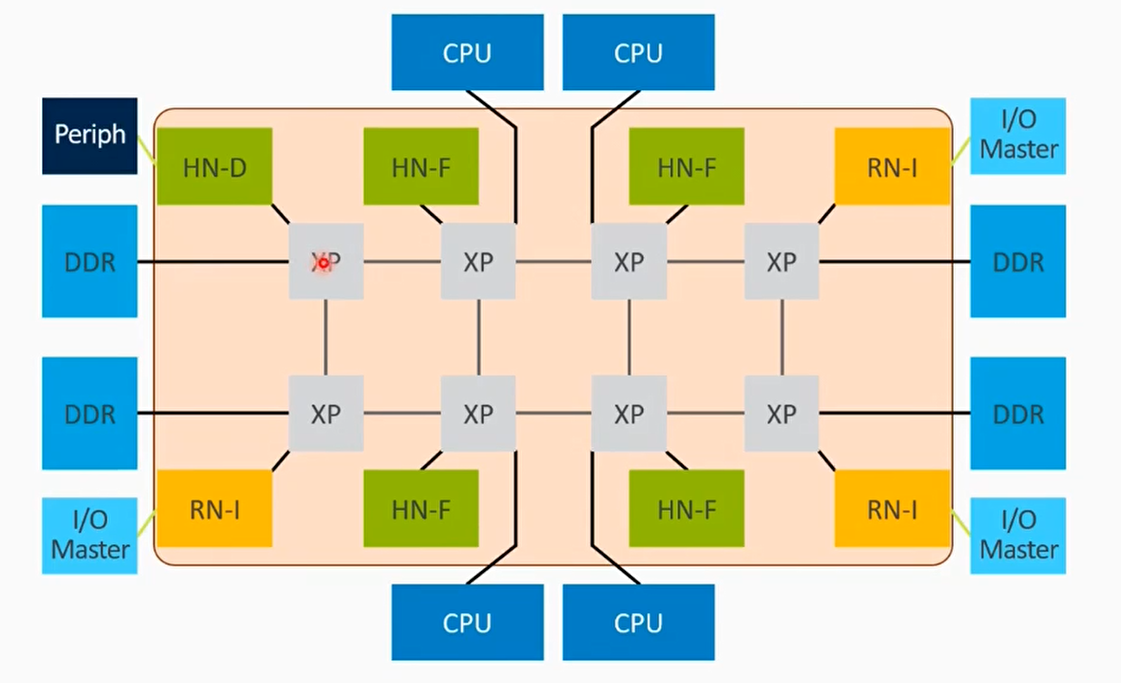
CI-700控制器介绍
-
最大支持 8 个 CPU cluster
-
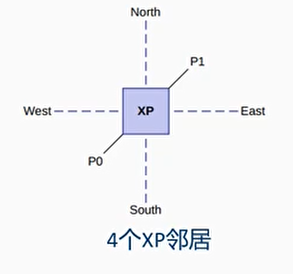
最大支持 12 个 crosspoint(XP):路由或者 switch 的硬件组件
- CI - 700 通过 XP 组成一个网格
- 每个 XP 可以有上下左右 4 个邻居 XP
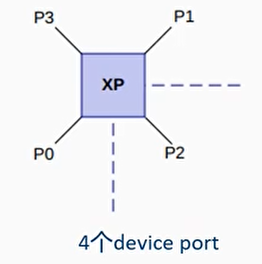
- 每个网格可以支持 4 个 device port
- 每个 device port 可以用来连接缓存一致性的 master(RN - F)或者 slave 设备(SN - F)
-
最大支持 8 个 RN - F 接口,用于连接 CPU cluster,GPU,加速卡,或者其他带 cache 的 master 设备
-
最大支持 8 个 HN - F 和最大 32MB 的 system cache
-
最大支持 8 个 SN 接口
ACE和CHI的区别
- 相同之处:
- 目标:硬件缓存一致性解决方案
- 采用类似cache状态转换
- snoop传输事务的理解很类似
- 不同之处
- ACE 采用 crossbar 结构,CHI 采用网格 mesh 结构
- CHI 采用分层设计:协议层,传输层,链路层
- CHI 采用 Packet-based communication
- CHI 采用 request node,home node,slave node 概念来描述传输事务
- CHI 支持更多的 snoop 传输事务
- CHI 支持 DCT,DMT,DWT 等优化传输性能
- CHI 支持 atomic 操作支持 cache stash
节点
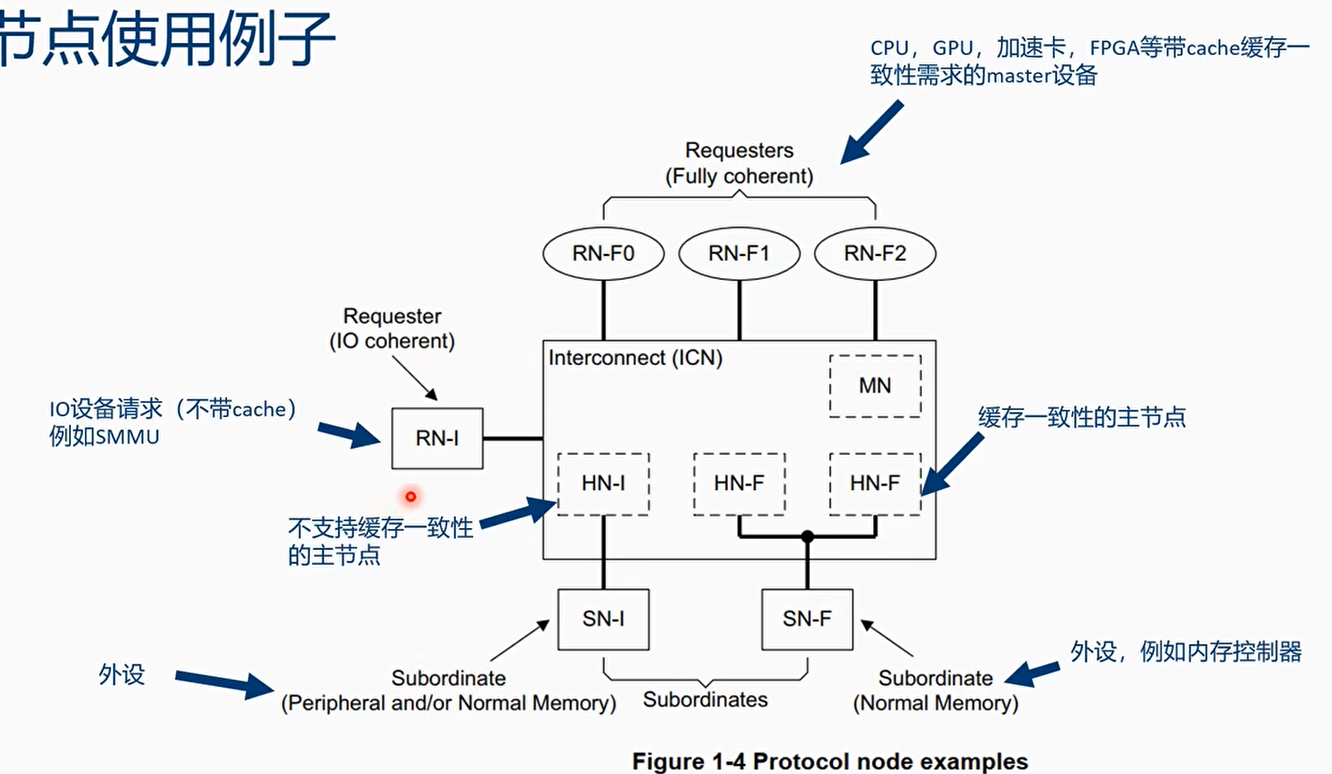
RN(request node):请求节点
- RN - F:缓存一致性的请求节点
- 内置硬件缓存一致性的 cache
- 允许产生所有的传输事务
- 支持所有的 snoop 传输
- RN - D:内置 DVM 的 IO 缓存一致性请求节点(类似 ACE - Lite + DVM)
- 不包括硬件缓存一致性 cache
- 接收 DVM 传输事务
- 可以产生一部分的传输事务
- RN - I:IO 请求节点
- 不包含硬件缓存一致性 cache
- 不接收 DVM 传输事务
- 可以产生一部分传输事务
- 不支持 snoop
HN(home node):在系统总线的主节点,用于接收来自请求节点的传输事务
- HN - F:缓存一致性的主节点
- 接收所有的请求类型
- PoC 的方式管理来自 RN - F 的 snoop 请求
- PoS 的方式管理内存请求的次序
- 包括 directory or snoop filter 来减少冗余的 snoop
- HN - I:不支持缓存一致性的主节点
- 只能处理一部分请求
- 不包括 POC,不能处理 snoopable 请求,
- POS 来处理 IO 请求的次序
SN:从节点
- **SN - F:**使用 normal memory 的从设备,它可以处理 non - snoopable 读写,atomic 请求(exclusive 请求),以及 CMO 请求
- SN - I:类似 SN - F,用于外设或者 normal memory
例子
cache状态机
与ACE相比,新增了UCE和UDP

通道Channel
- CHI定义的channel与ACE完全不一样
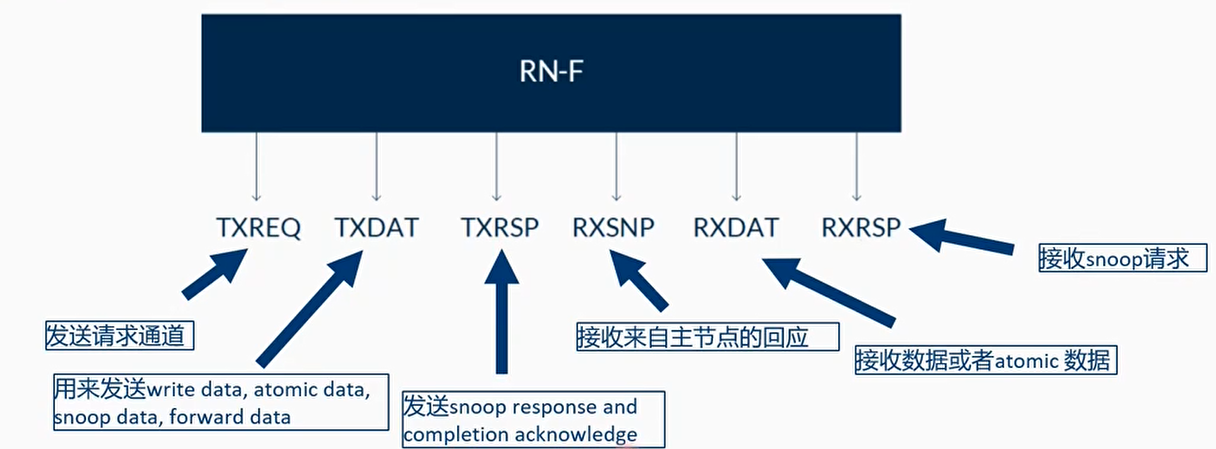
- Channel中的握手协议与AXI/ACE不同
- FLITV信号拉高,表明transmitter准备发送数据包,包已经valid
- LCDRV信号拉高表明receiver发送一个credit给transmitter:你可以发送了
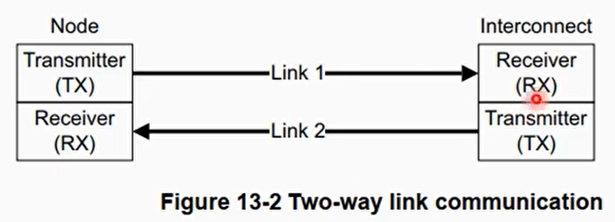
链路层
- 链路层为节点和互连IP之间基于packet-base的通信提供了一种流线型的机制(streamlined mechanism)
- 提供了一种two-way link传输模式
- Transmitter -> Receiver
- Receiver -> Transmitter
包格式-Flits
- Flit = Flow control unIT,是在链路层传输的最小单元。一个packet包含多个Flits
- Protocol Flit:用来传输协议信息的
- Link Flit:用来传输链路维护(link maintenance)信息
- CHI采用消息包(protocol messages)形式来传递信息,包括各种ID,opcodes,内存属性,地址,数据,error response等

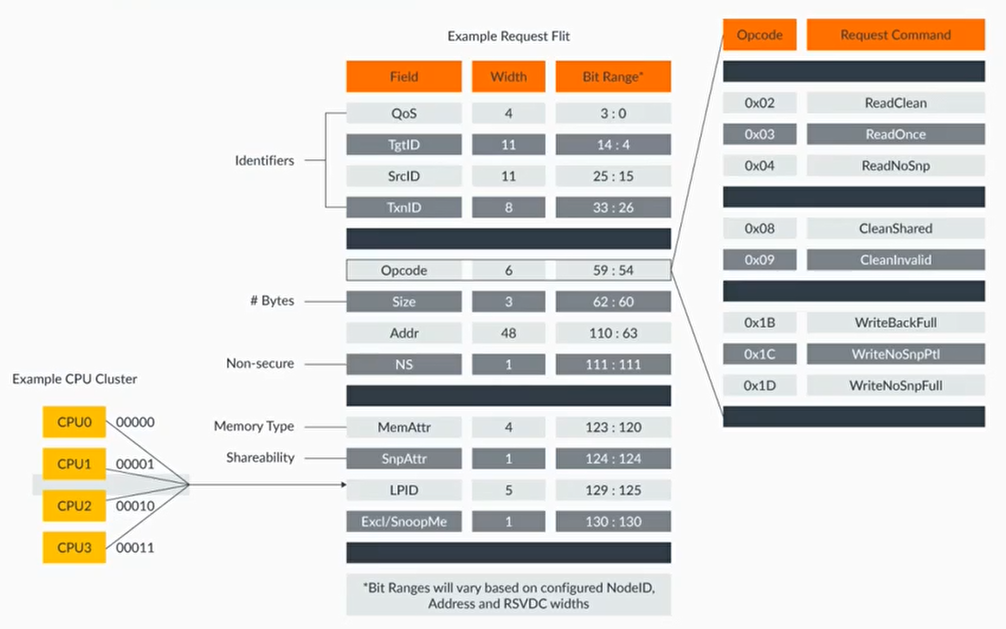
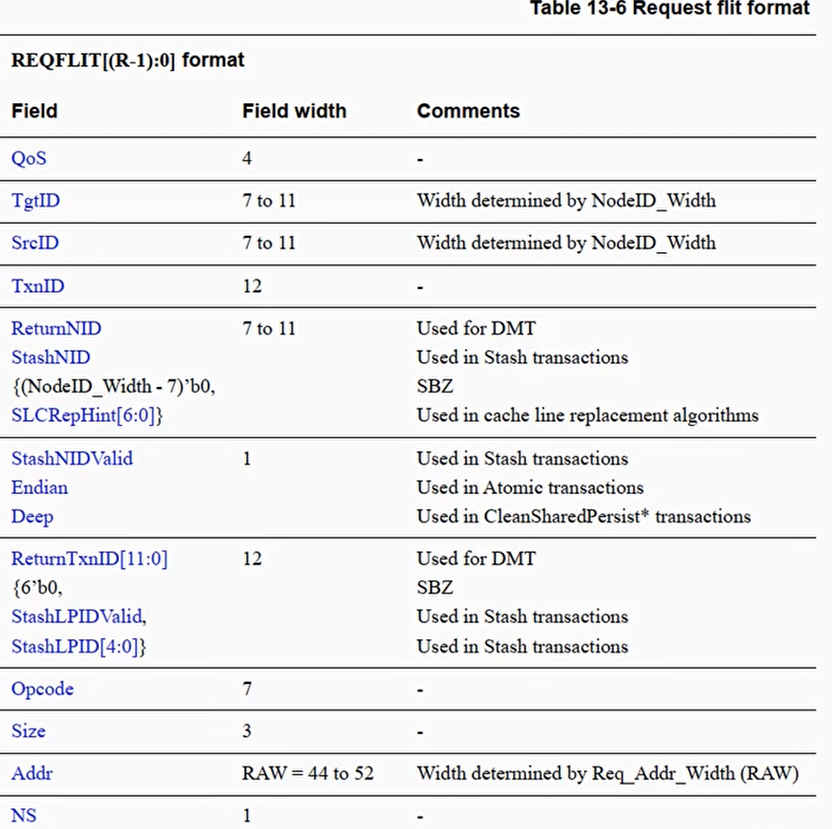
Protocol flit
- CHI定义了4中protocol flit
- Request flit
- Response flit
- Snoop flit
- Data flit
- 每种flit都有自己的格式(format)
ID
CHI 协议里定义了很多的 ID:
- Source ID(SrcID):表明 flit 包的发送节点的 ID
- Target ID(TgtID):表明接收 flit 包的目标节点 ID
- Transaction ID(TxnID):每个传输事务有一个唯一的 ID,可以用于 outstanding request,最大支持 256 个未完成的传输 ID。类似 AXI 中的 transaction ID。
- Request opcode (Opcode):用来指定传输类型
- Data Buffer ID (DBID):用于回应和数据包,允许事务的 Completer 为事务提供自己的标识符
ID号分配和绑定
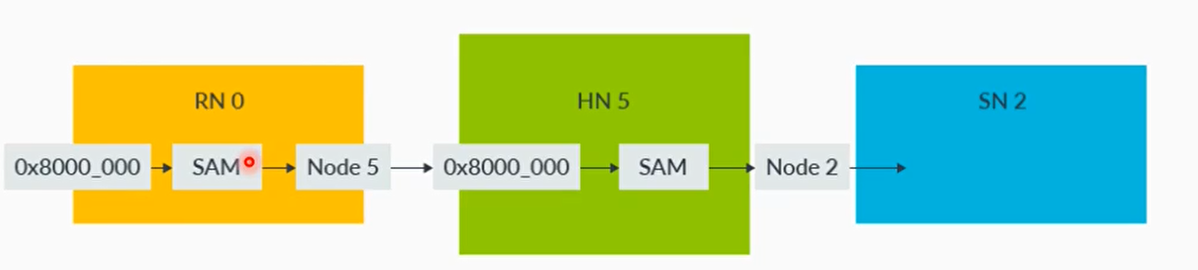
- CHI 使用 System Address Map (SAM) 来把传输事务中的物理地址转换成 target Node ID
- 每个 RN 和 HN 都有个 SAM
- CHI 规范没有约定 SAM 如何实现,包括 SAM 的格式(format and struct)
- CHI 对 SAM 提出的要求:
- 描述全系统的地址空间,所有的 SAM 必须全局一致性,例如地址 0xFF00_0000 必须映射到相同的 HN
- 对于没有映射的地址,必须提供错误的回应机制
Completion acknowledgement
- 类似 ACE 中的 RACK 和 WACK 信号,用来保证 transaction 的次序
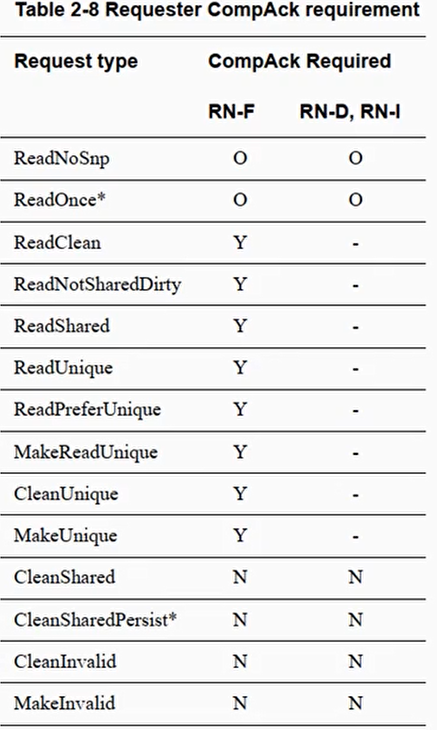
- CompACK 保证:HN - F 在收到完成 CompACK 之后,才能处理其他 snooping 传输事务
- 对于读事务:
- 除了 ReadNoSnp 和 ReadOnce * 事务,其他读事情都需要 CompACK
- RN - F 在收到 Comp, CompData, RespSepData 等信号之后才会发送 CompACK
- HN - F 必须等待 CompACK 之后,才能对同一个地址发送其他请求事务的 snooping
- 对于写事务:
- 只有 WriteUnique 和 WriteNoSnp 事务需要 CompACK
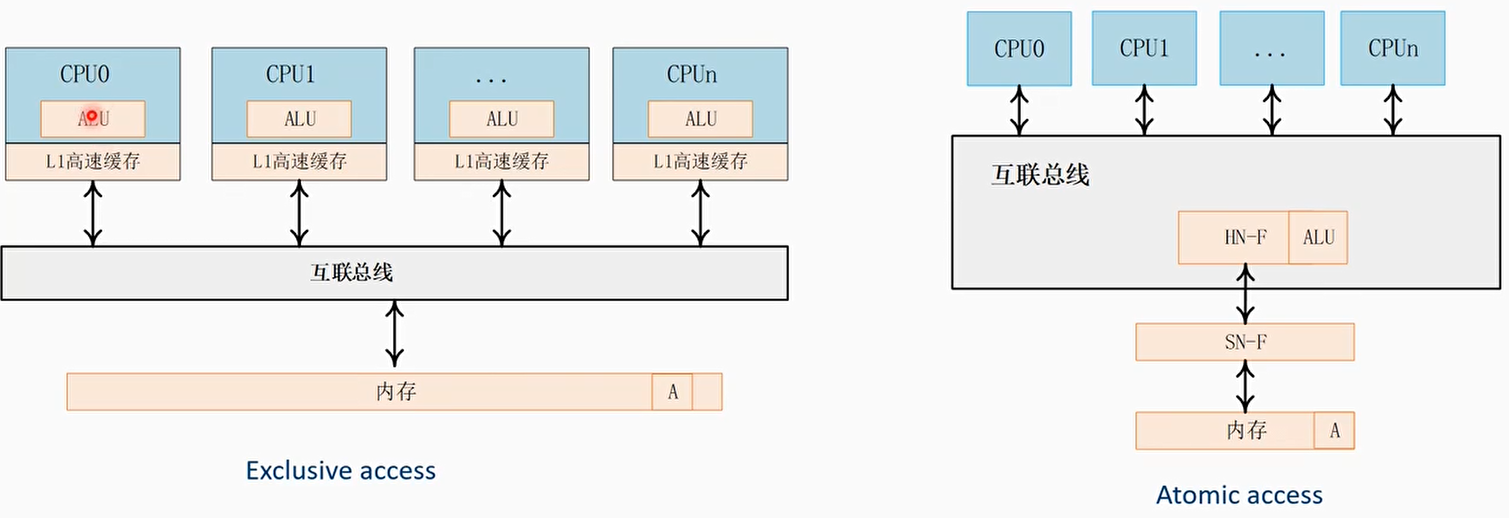
exclusive access
- Exclusive流程与ACE类似
- Exclusive access的流程:
- 执行exclusive load
- 计算
- 执行exclusive store
- 如果有其他master对这个地址写操作,fail
- 如果没有其他master对这个地址写操作,success
- 在RN-F(master)端必须实现一个LP(Logical Processor)monitor
- 在CHI互联总线内部的HN-F节点上必须实现一个PoC(Point of Coherence)monitor
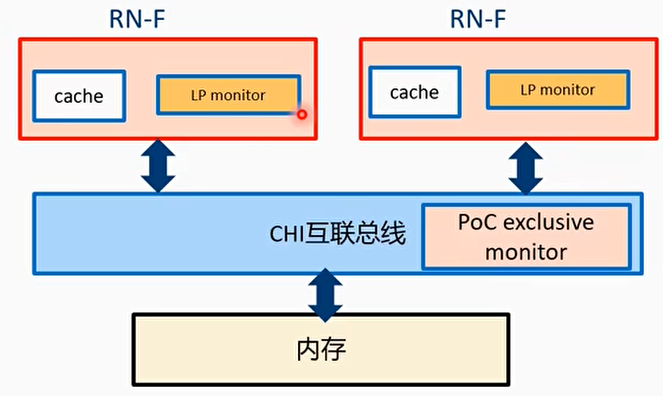
LP monitor 位于 RN - F:
- 每个 RN - F 必须实现一个 exclusive monitor,用来观察和监视 exclusive 访问的那个内存地址。
- 当 CPU 开始一个 exclusive load 的时候,LP monitor 会被设置。
- 当下面情况,LP monitor 会被 reset:
- 如果这个地址被其他 LP 改写了
- 如果 LP 对这个地址执行了另外一个 store 操作
POC monitor 位于 HN - F:
- POC monitor 会记录每一个 LP 执行 exclusive 访问的 snoop 事务。
- monitor 会并行地监视所有 LP 的 exclusive 访问。
- 当 HN - F 收到一个 exclusive load 或者 store 操作,monitor 就会把这个信息注册:某某正在尝试一个 exclusive 访问。
- 当 LP 执行 exclusive store 失败之后,LP 需要重启 exclusive load 和 store 的访问序列。
- 当 HN - F 收到一个 exclusive store 操作:
- 如果在 PoC monitor 里已经注册了这个地址对应的 exclusive 访问记录,并且它还没有被其他 LP 给 reset 掉,那么 exclusive store 会成功,然后其他所有尝试 exclusive 的访问记录会被 reset。
- 如果 LP 执行一个 exclusive 访问,但是在 POC monitor 里没有找到,那么 exclusive store 会失败。
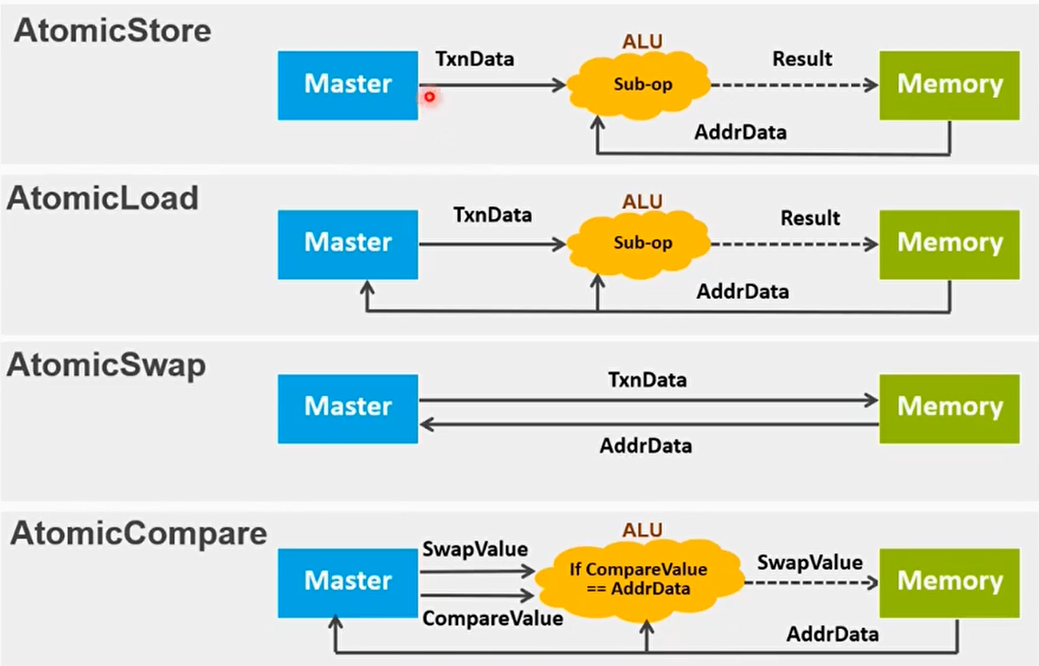
Atomic access
- Atomic访问在CHI.B协议中添加
- Atomic访问允许在靠近数据的地方执行运算和计算
- HN-F或者SN里面有ALU逻辑计算单元
- Atomic访问的好处:
- 更准确和可预测的延时
- 不用和其他requester争用cache,减少了访问内存出现的阻塞和cache颠簸
- 公平性。多个requester同时访问一个内存地址的时候,通过POS或者POC来做仲裁
- Atomic事务有四种
- AtomicStore
- AtomicLoad
- AtomicSwap
- AtomicCompare
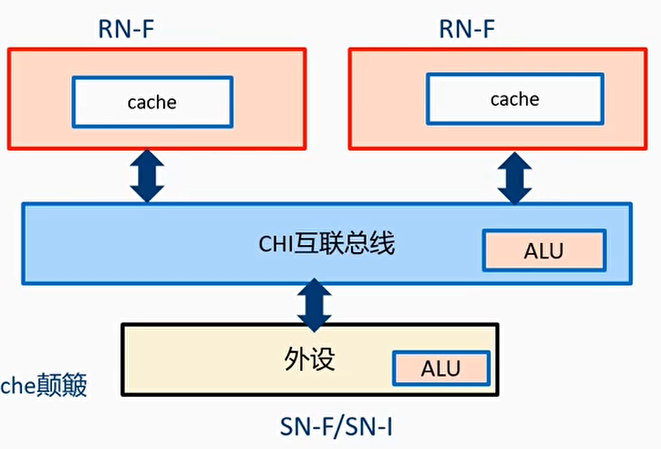
Atomic access和exclusive access对比
Atomic类型

新特性
cache stach
- IO设备直接把数据写入到目标RN-F的cache里
- 类似Intel DDIO技术
- Cache stash支持的事务有4种
- WriteUniquePtlStash
- WriteUniqueFullStash
- WriteUniqueFullStash
- StashOnceShared
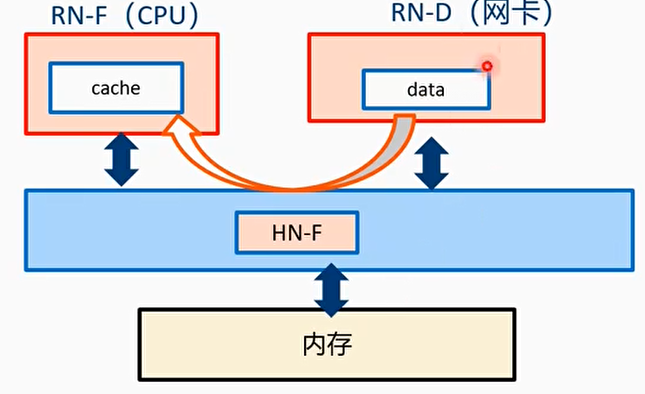
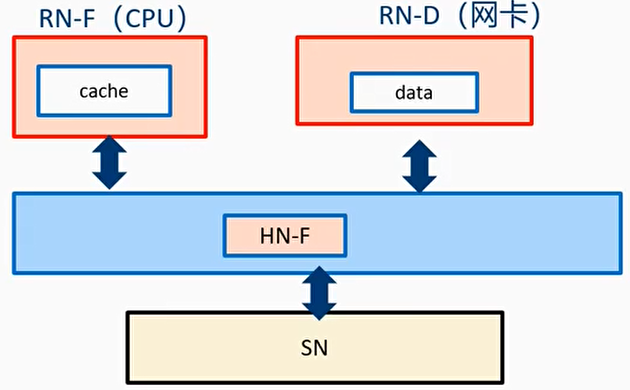
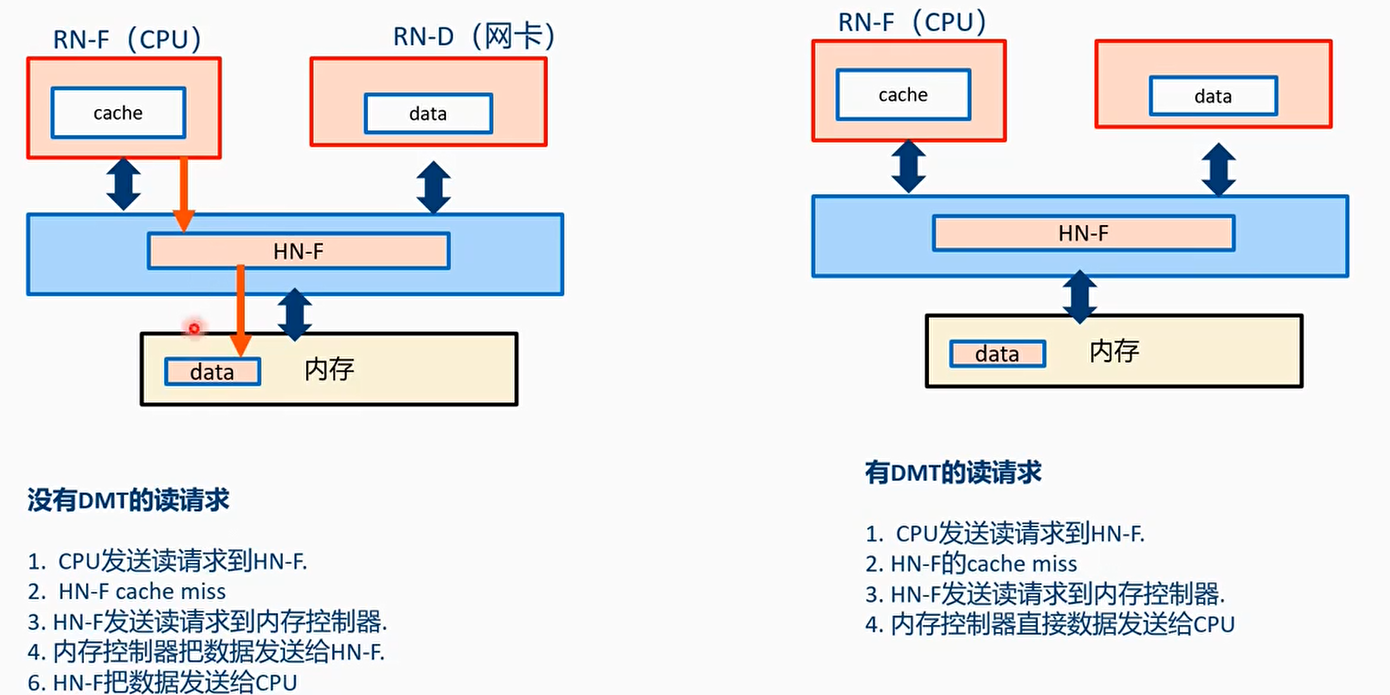
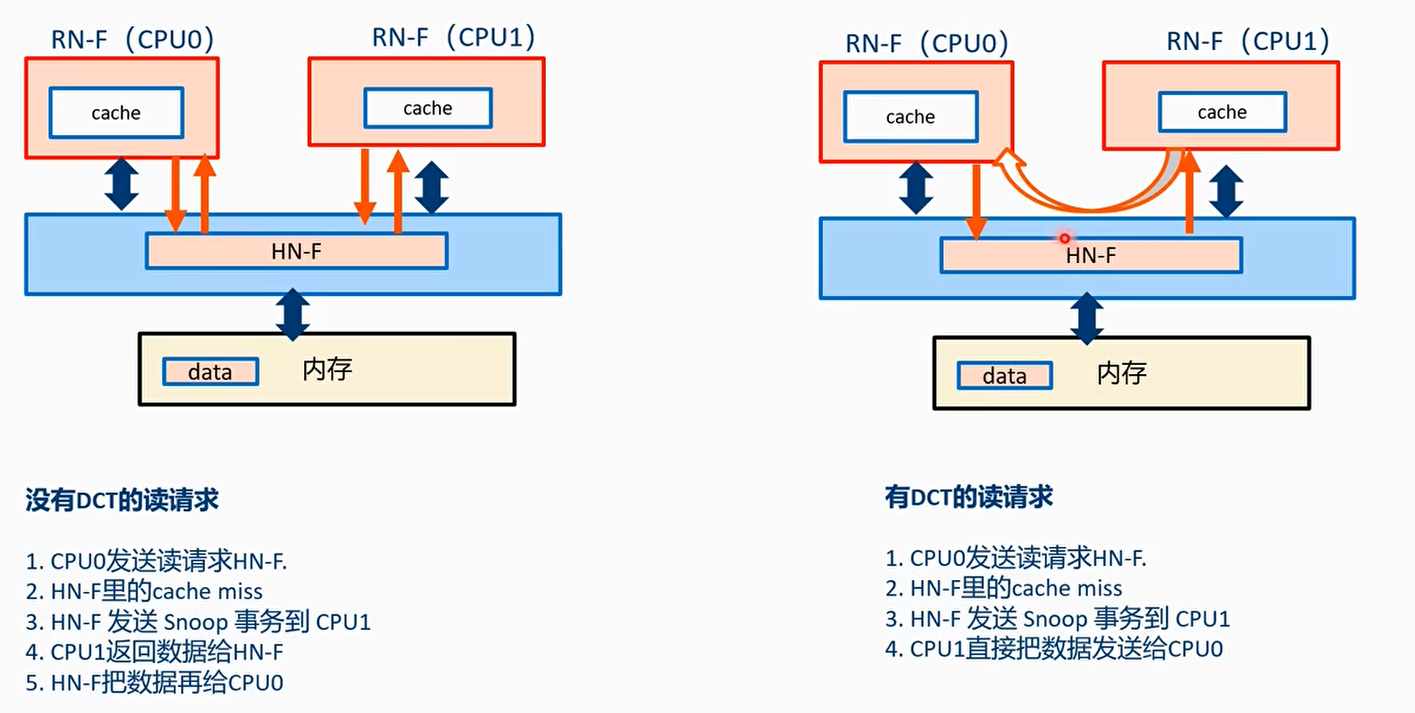
DMT和DCT
- 在CHI.A协议上,读数据和snoop data要先发送给主节点,然后才能发送receiver节点
- 缺点:增加了传输长度,延时

本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 常想一二,不思八九!
评论