ARM Memory Management
时间轴
2025-10-24
init
参考文档:

内存管理的基本知识和概念
直接使用物理内存的缺点
- 进程地址空间保护问题。所有的用户进程都可以访问全部的物理内存,所以恶意程序可以修改其他程序的内存数据
- 内存使用效率低。如果即将要运行的进程所需要的内存空间不足,就需要选择一个进程进行整体换出,这种机制导致有大量的数据需要换入和换出,效率非常低下
- 程序运行地址重定位问题
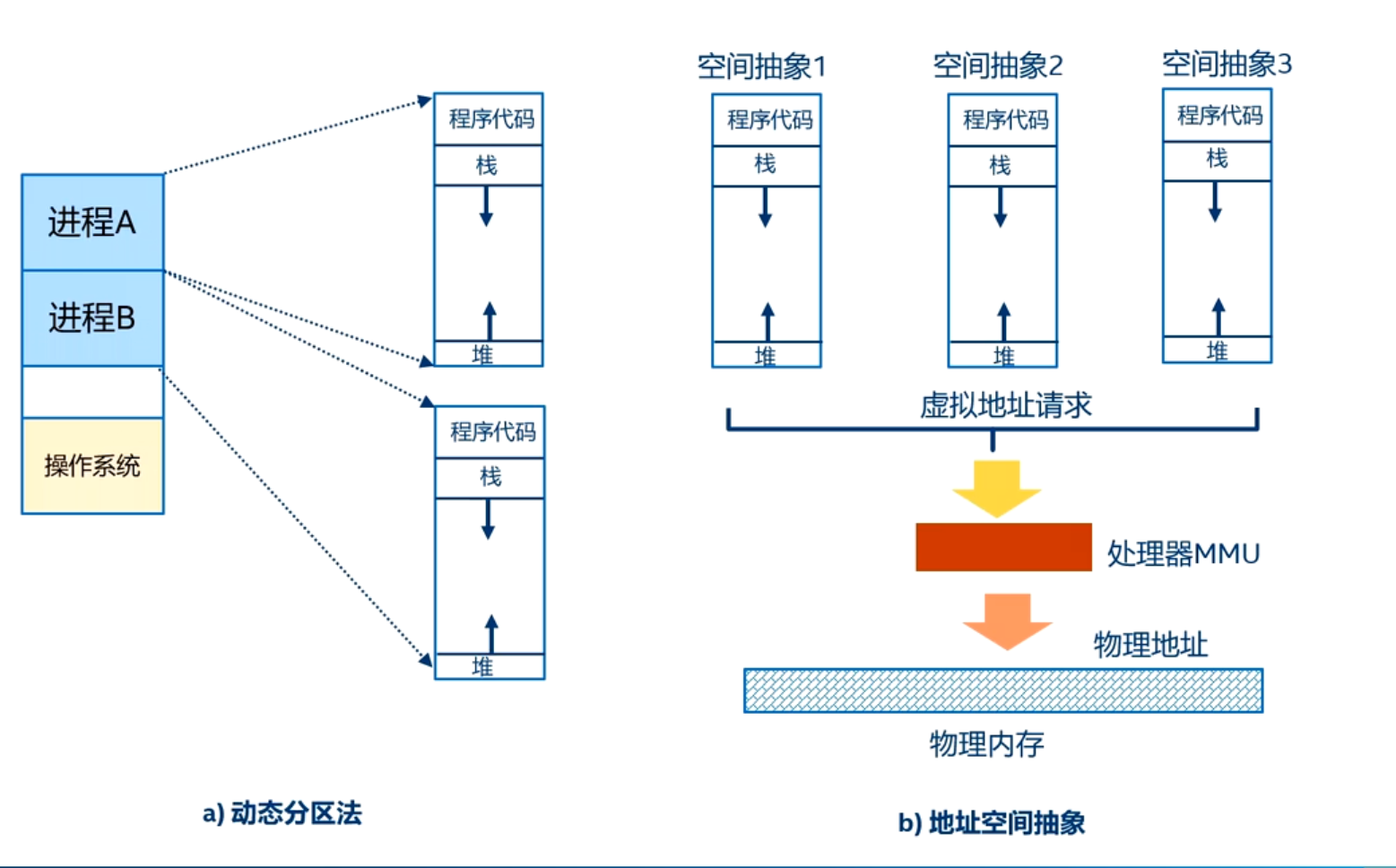
分页机制的基本概念
- 虚拟存储器(Virtual Memory)
- 虚拟地址空间(Virtual Address)
- 物理存储器(Physical Memory)
- 页帧(Page Frame)
- 虚拟页帧号(Virtual Page Frame Number)
- 物理页帧号(Physical Frame Number)
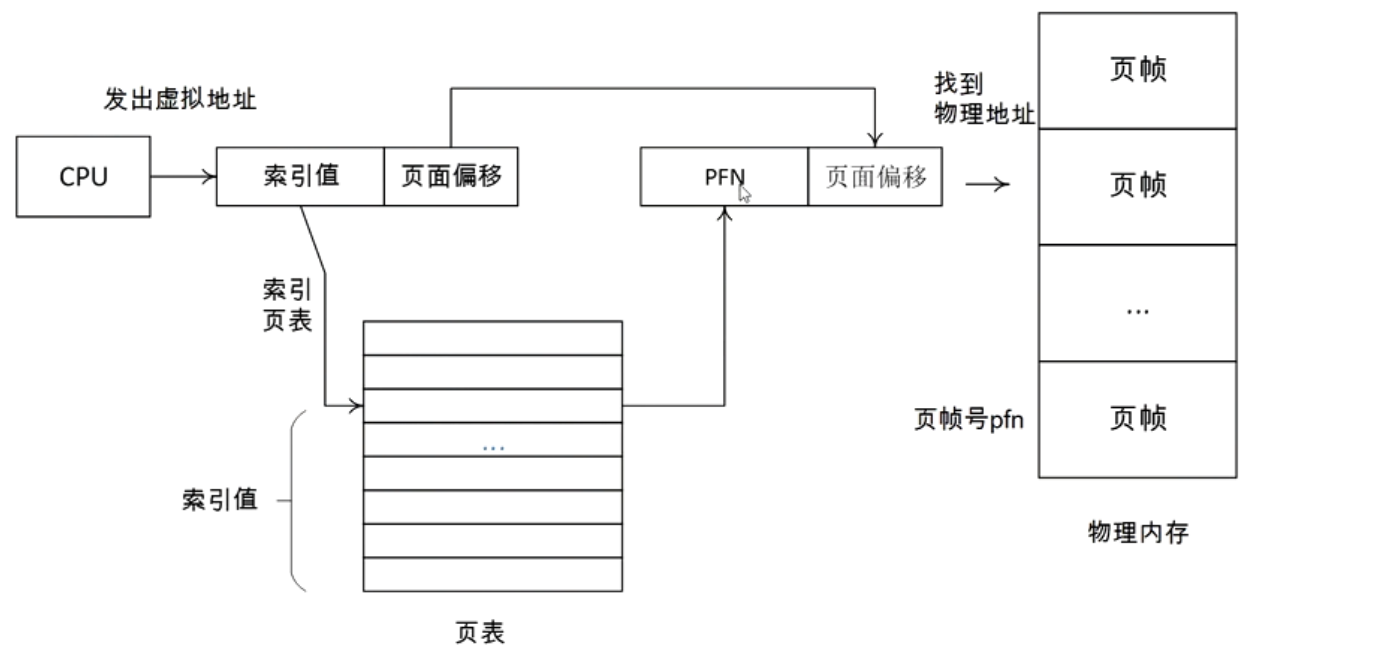
- 页表(Page Table, PT)
- 页表项(Page Table Entry, PTE)
虚拟地址到物理地址映射的过程
一级页表
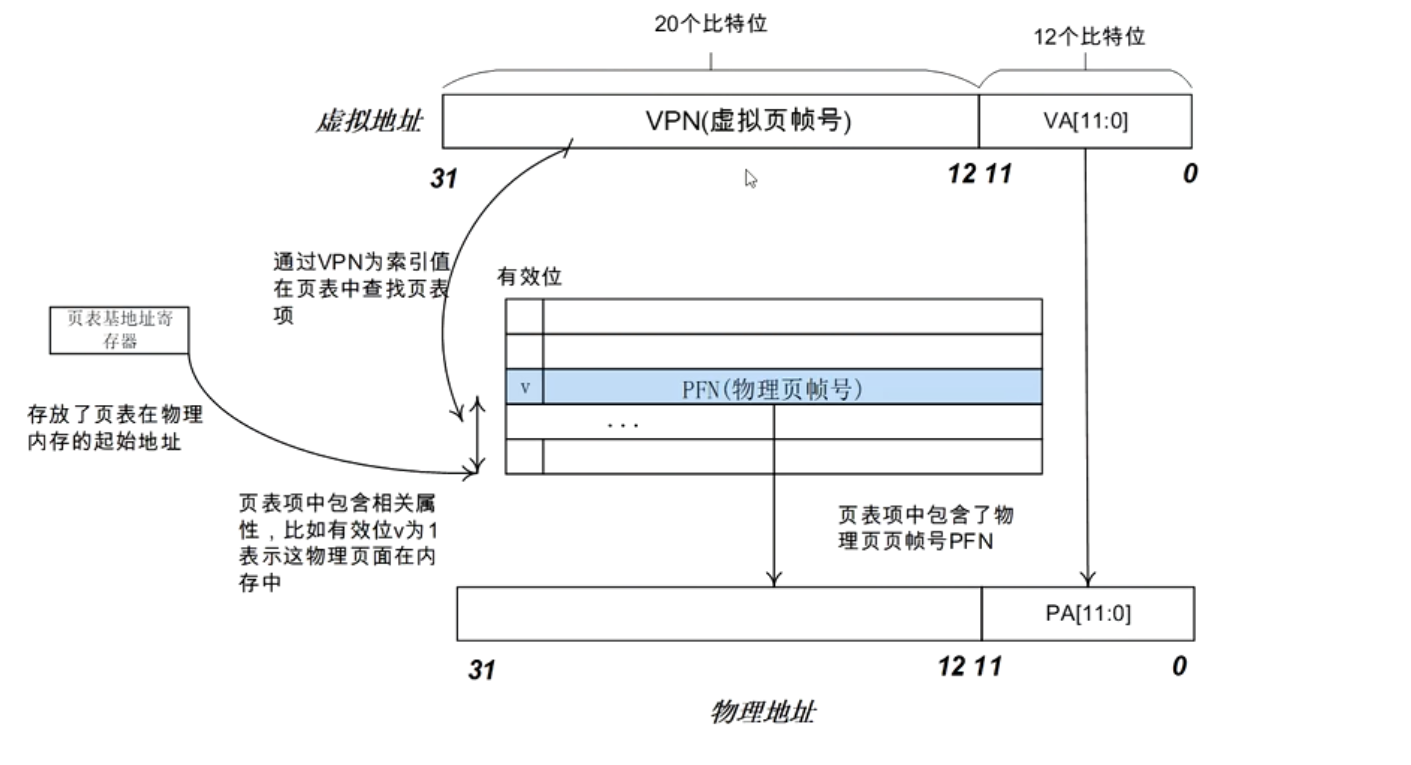
采用一级页表的缺点
- 处理器采用一级页表,虚拟地址空间位宽32位,寻址范围是4GB大小,物理地址空间位宽也是32bit,最大支持4GB物理内存,另外页面大小是4KB。为了能映射整个4GB地址空间,需要4GB/4KB = 1MB个页表项,每个页表项占用4字节,共需要4MB大小的物理内存来存放这张页表
- **每个进程拥有一套属于自己的页表,在进程切换时需要切换页表基地址。**如上述的一级页表,每个进程需要为其分配4MB的连续物理内存来存储页表,这是不能接受的,因为这样太浪费内存了。
- 多级页表:按需一级一级映射,不用一次全部映射所有地址空间
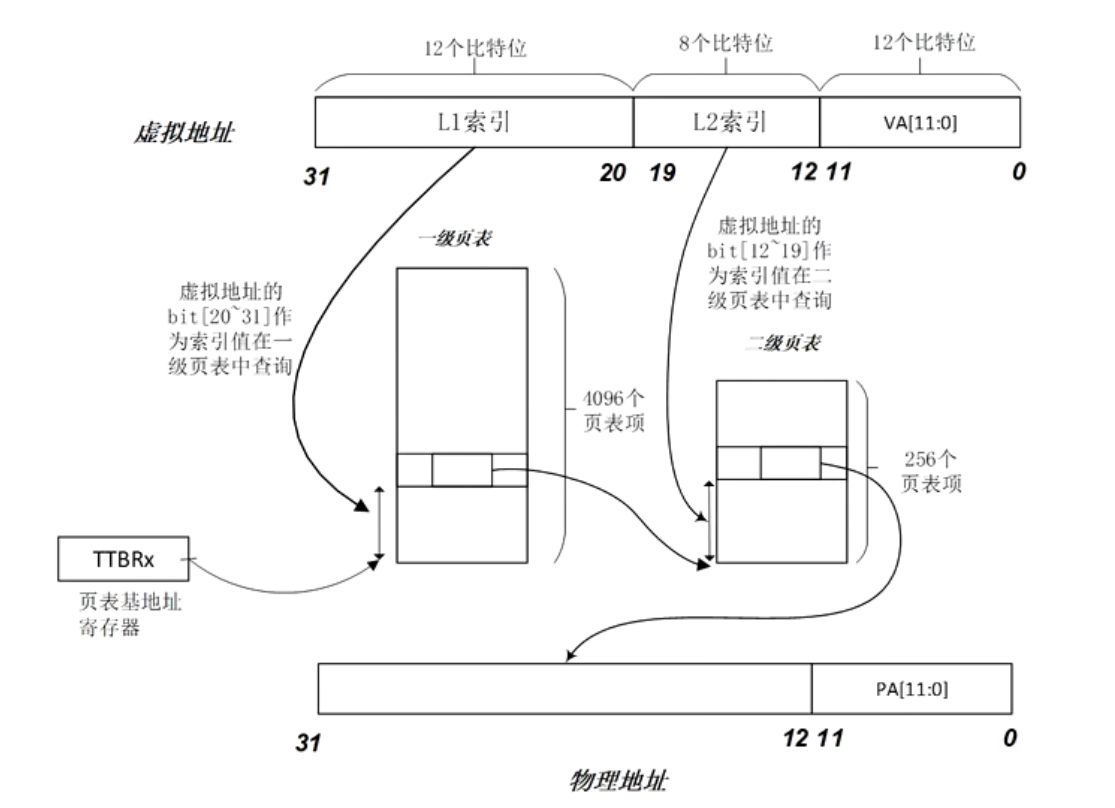
二级页表
VMSA
Virtual Memory System Architecture
- VMSA提供了MMU硬件单元
- 虚拟地址到物理地址的转换
- 访问权限
- 内存属性检查
- MMU硬件单元用来实现VA到PA的转换
- 硬件遍历页表table walking
- TTBR寄存器保存了页表基地址
- TLB保存了最近的转换页表项

没有虚拟化场景的情况下,翻译只有一个阶段,由VA映射到PA
在有虚拟化场景的情况下,翻译需要先转换为IPA

TTBR0_ELx 用于每个进程的地址空间
**TTBR1_ELx **用于内核空间,所有进程共享

ARMv8的页表
aarch64仅仅支持Long Descriptor的页表格式
AArch32支持两种页表格式
- Armv7-A Short Descriptor format
- Armv7-A (LPAE) Long Descriptor format
AArch64支持三种不同的页大小:4KB,16KB,64KB
大粒度page size可以减少页表的体积
地址总线位宽支持48位或者52位
52位宽:ARMv8.2-LVA is implemented and the 64 KB translation granule
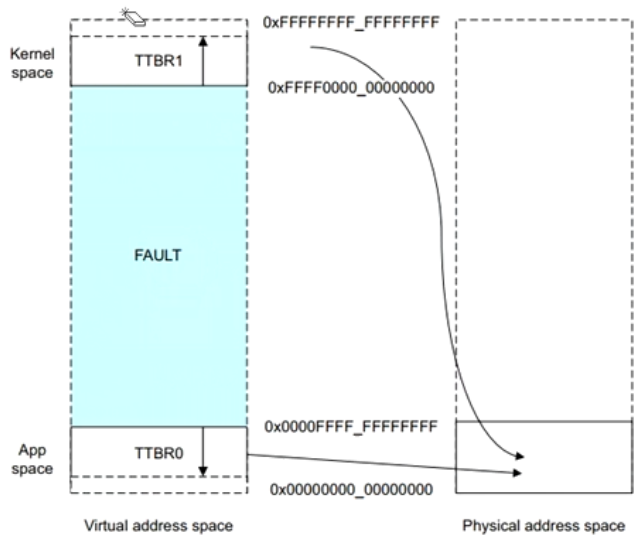
以48位总线位宽为例
虚拟地址VA被划分为两个空间,每个空间最大支持256TB
- 低位虚拟地址空间位于0x0000_0000_0000_0000到0x0000_FFFF_FFFF_FFFF
- 高位的虚拟地址空间位于0xFFFF_0000_0000_0000到0xFFFF_FFFF_FFFF_FFFF

(Fault是非规范区域,CPU不能访问)
四级页表
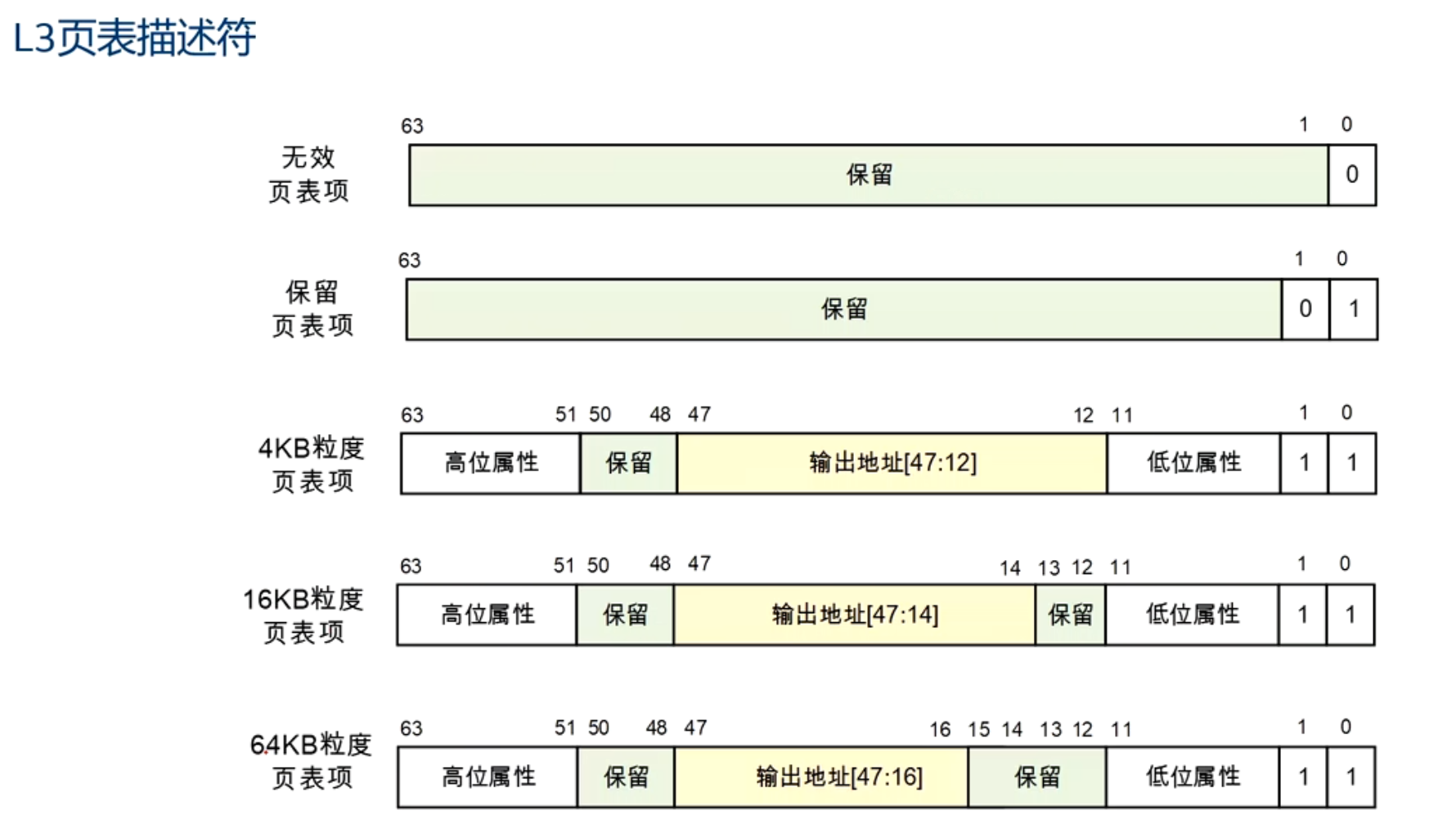
AArch64的页表描述符
下面的都是48位虚拟地址,4KB大小页面
L0~L2的页表描述符

块类型表示描述的是一块非常大的内存

L3页表描述符




| 层级 (Level) | 对应 Linux 抽象 | 描述符可能的类型 |
|---|---|---|
| L0 (可选) | PGD | Table / Fault |
| L1 | PUD | Block (1GB, granule=4K) / Table / Fault |
| L2 | PMD | Block (2MB, granule=4K) / Table / Fault |
| L3 | PTE | Page (4KB, granule=4K) / Fault |
注意:
- Block entry 只能出现在中间层(L1/L2),表示大页映射,映射一大段物理地址空间,相当于最后一级页表了。
- PTE (L3) 不能是 Block,只能是 Page 或 Fault。
- 输出地址是下一级页表的PA即物理地址
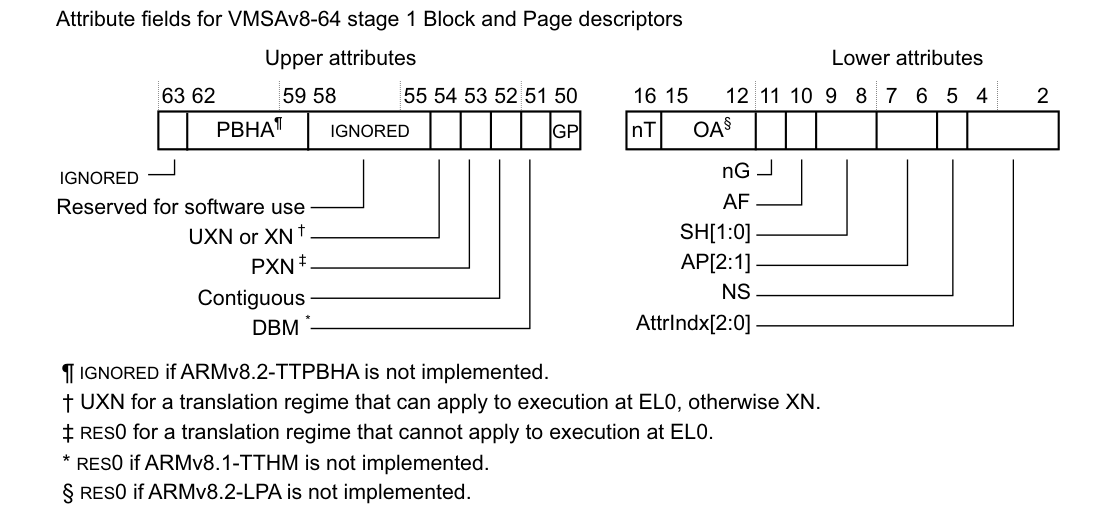
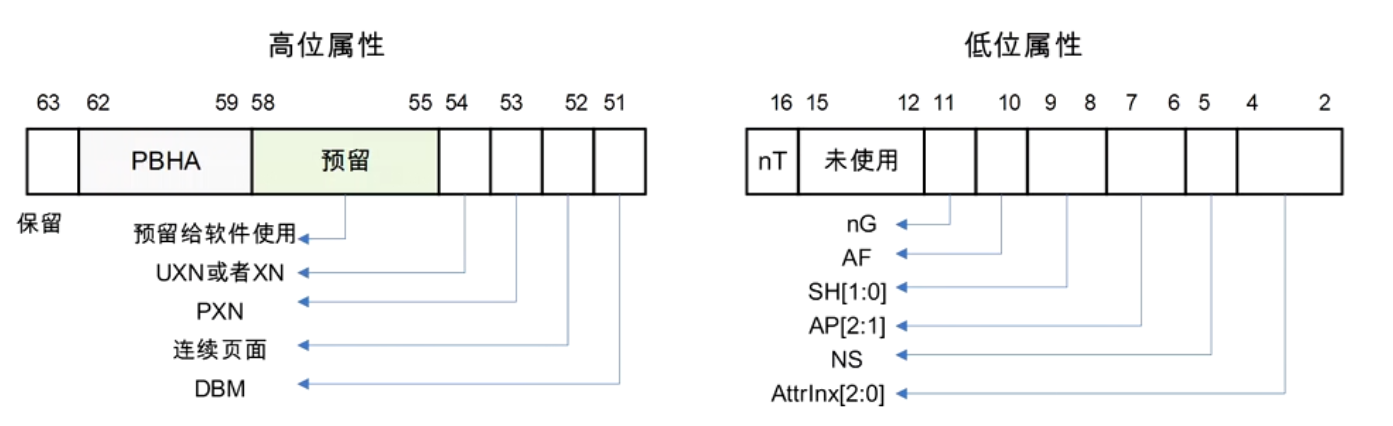
页表属性
只有指向 最终物理页(block/page) 的表项,才需要页表属性
Armv8.6 D5.3.3章
- bit[0] → 是否有效:
0= Invalid (Fault entry)1= 有效 (Valid entry)
- bit[1] → 类型(只在有效时才有意义):
0= Block entry (块映射,大页映射)1= Table entry (指向下一级页表;到最后一级时变成 Page entry)
所以:block和page的页表属性

高位属性和低位属性
只描述Block和Page
Share Domain
Non-shareable
This represents memory accessible only by a single processor or other agent, so memory accesses never need to be synchronized with other processors. This domain is not typically used in SMP systems.
Inner shareable
This represents a shareability domain that can be shared by multiple processors, but not necessarily all of the agents in the system. A system might have multiple Inner Shareable domains. An operation that affects one Inner Shareable domain does not affect other Inner Shareable domains in the system. An example of such a domain might be a quad-core Cortex-A57 cluster.
Outer shareable
An outer shareable (OSH) domain re-order is shared by multiple agents and can consist of one or more inner shareable domains. An operation that affects an outer shareable domain also implicitly affects all inner shareable domains inside it.
However, it does not otherwise behave as an inner shareable operation.
Full system
An operation on the full system (SY) affects all observers in the system.
Contiguous Block entries
- ARMv8利用TLB进行的一个优化:利用一个TLB entry来完成多个连续的page的VA到PA的转换
- 使用Contiguous bit的条件
- 页面对应的VA必须是连续的
- 对于4KB的页面,16个连续的page
- 对于16KB的页面,32或128个连续的page
- 对于64KB的页面,32个连续的page
- 连续的页面必须有相同的属性
- 起始地址必须以页面对齐
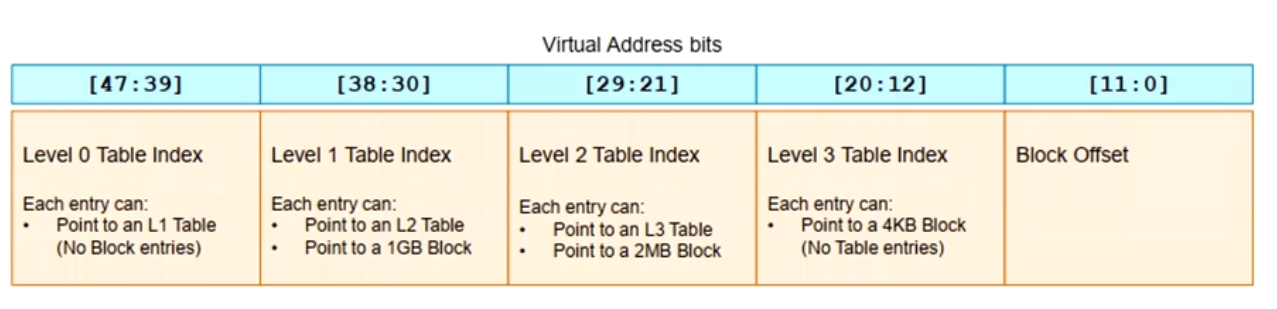
4KB页表
- 4级页表
- 48bit虚拟地址
- 每级页表使用9bit来做索引(512 entries)
16KB页表
4级页表
48bit虚拟地址
L0页表只有两个entry
L1,L2,L3页表使用11bit来做索引(2048 entries)
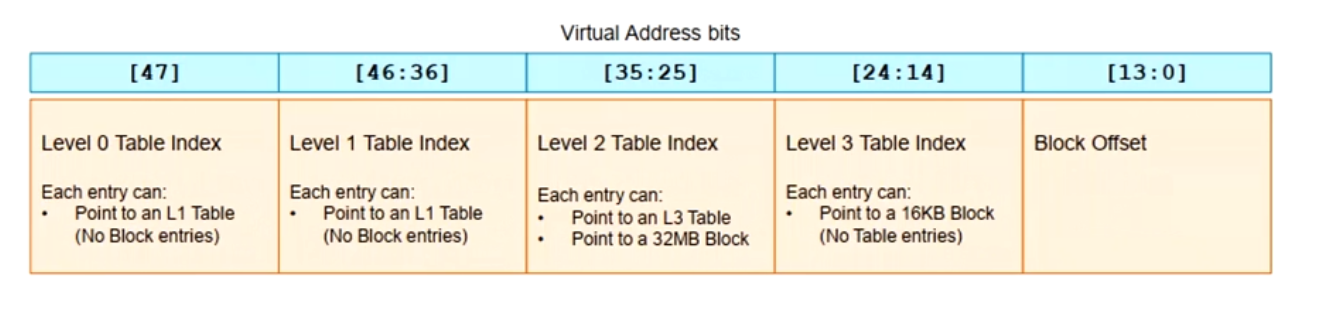
64KB页表
- 3级页表
- 48bit虚拟地址
- L1页表只有64个entry
- L2和L3页表使用13bit
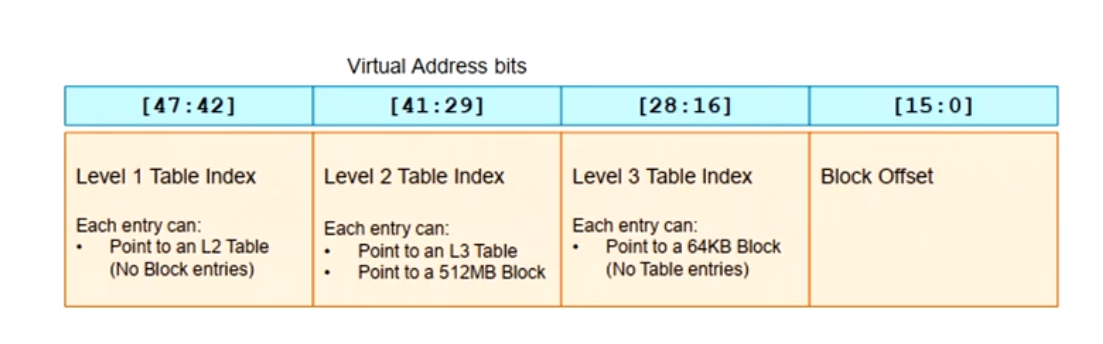
分离的两套页表设计
- 用户空间(EL0)和内核空间(EL1)采用两套分离的页表基地址设计
- 虚拟地址的高16位为1时选择TTBR1_EL1
- 虚拟地址的高16位为0时选择TTBR0_EL0
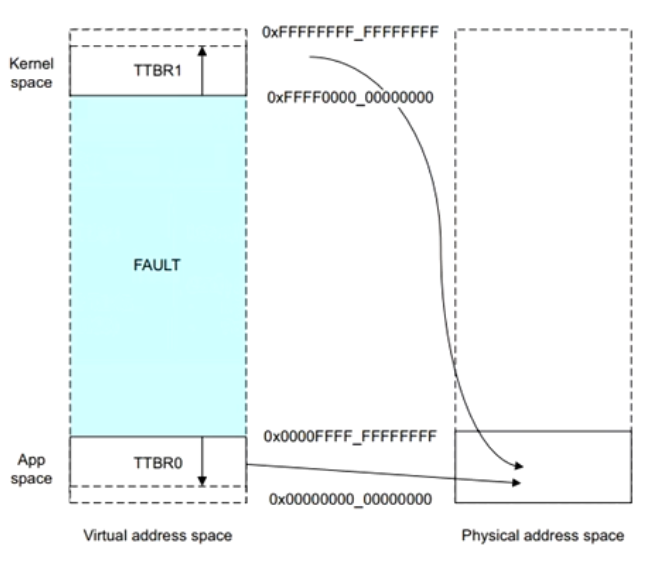
查找地址的例子
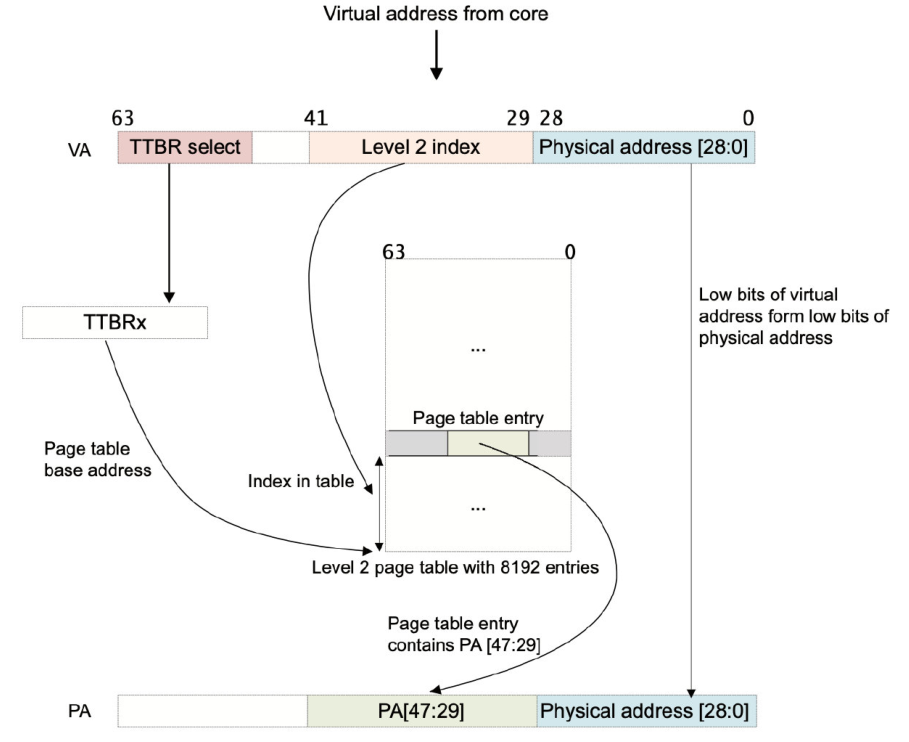
在一个简单的地址转换中,只涉及一个层次的查找。假设我们使用的是一个 64KB 的颗粒,有一个 42 位的虚
拟地址。MMU 映射虚拟地址的方法如下:
- 如果 VA[63:42] = 1,则 TTBR1 用于第一页表的基地址。当 VA[63:42] = 0 时,TTBR0 用于第一页表的
基地址。 - 页表包含 8192 个 64 位页表条目,并使用 VA[41:29] 进行索引。MMU 从表中读取相关的 2 级表格条目。
- MMU 检查页面表条目的有效性,以及是否允许请求的内存访问。假设它有效,则允许内存访问。
- 在图 12-7 中,页表条目指的是 512MB 的页面(它是一个块描述符)。
- Bit[47:29] 取自此页面表条目,并形成物理地址的 Bit[47:29]。
- 由于我们有一个 512MB 的页面,VA 的 Bit[28:0] 被取为 PA[28:0]。请参阅第 12-15 页颗粒大小对映射表
的影响。 - 返回完整的 PA[47:0],以及页面表条目中的其他信息。
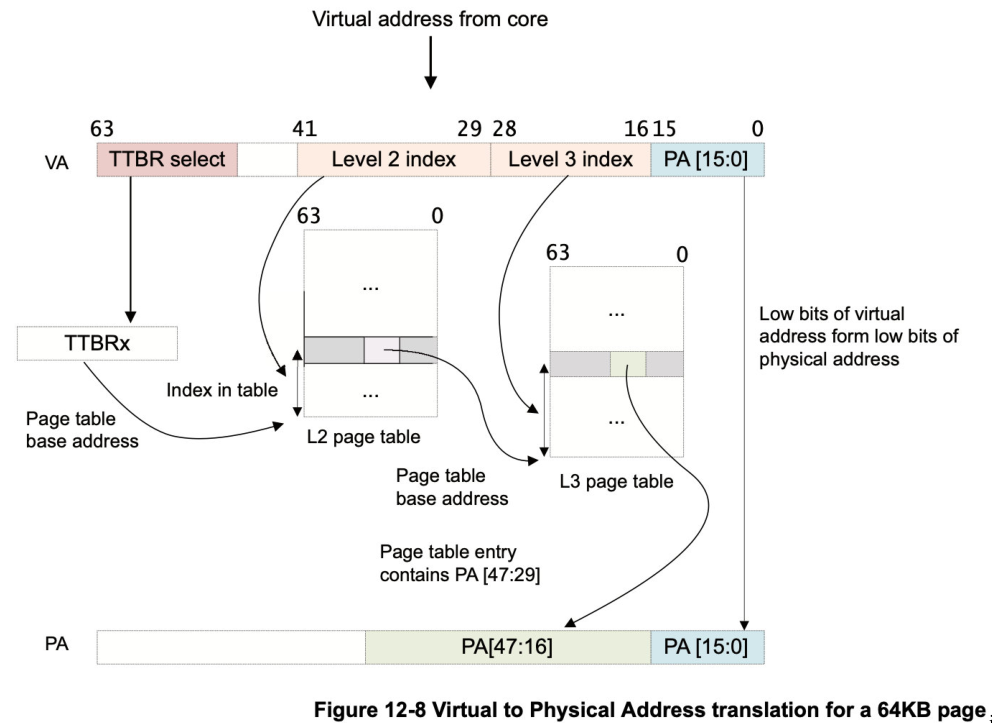
假设了一个 64KB 的颗粒和 42 位的虚拟地址空间。
- 如果 VA[63:42] = 1,则 TTBR1 用于第一页表的基地址。当 VA[63:42] = 0 时,TTBR0 用于第一页表的
基地址。 - 页面表包含 8192 个 64 位页面表条目,并通过 VA[41:29] 进行索引。MMU 从表中读取相关的二级表格
条目。 - MMU 检查二级页面表条目的有效性,以及是否允许请求的内存访问。假设它有效,则允许内存访问
- 在图 12-8 中,二级页表条目是指三级页表的地址(它是一个表描述符)。
- Bit[47:16] 取自二级页表条目,形成三级页表的基地址。
- VA 的 Bit[28:16] 用于索引 3 级页面表条目。MMU 从表格中读取相关的 3 级表格条目。
- MMU 检查三级页面表条目的有效性,以及是否允许请求的内存访问。假设它有效,则允许内存访问。
- 在图 12-8 中,三级页面表条目指的是 64KB 页面(它是一个页面描述符)。
- Bit[47:16] 取自三级页面表条目,用于形成 PA[47:16]。
- 由于我们有一个 64KB 页面,VA[15:0] 被取为 PA[15:0]。
- 返回完整的 PA[47:0],以及页面表条目中的其他信息。
与页表相关的系统寄存器
TCR_EL1
Translation Control Register
配置地址空间大小和页表粒度
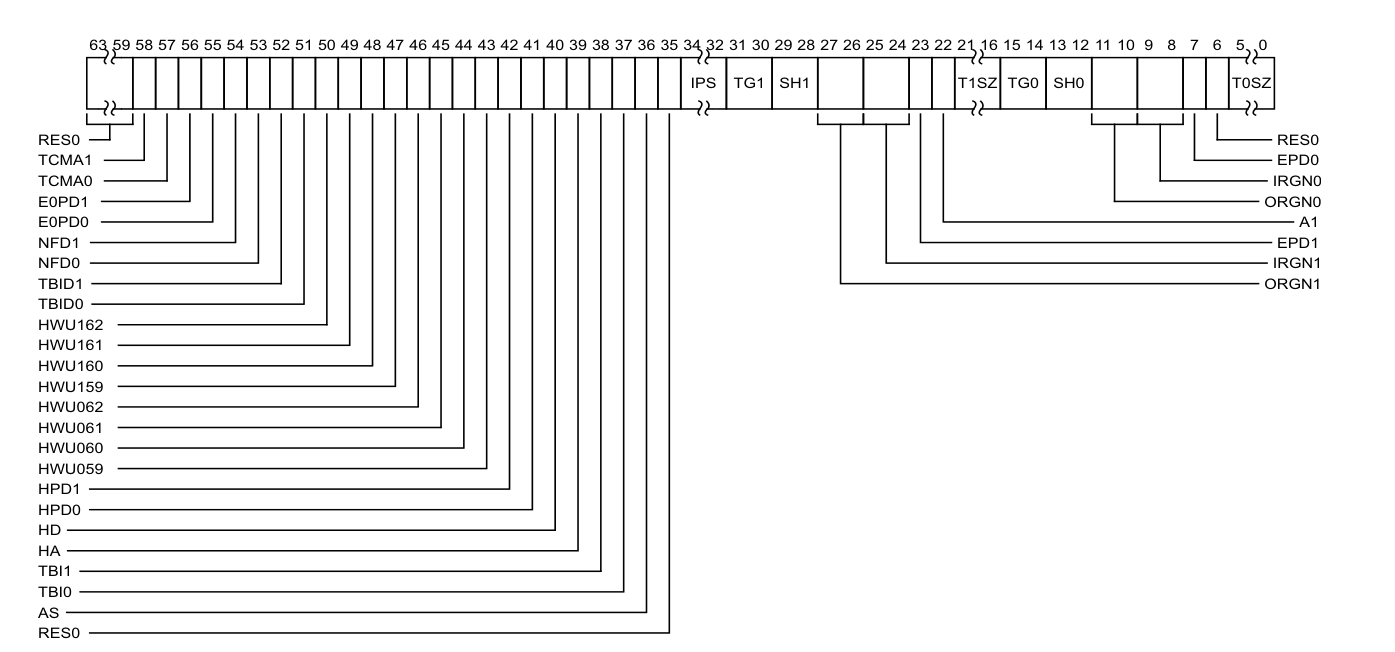
配置地址空间大小和页表粒度

- IPS:Intermediate Physical Address Size,用来配置物理地址大小,例如48bit,256TB大小的物理空间
- TG1和TG0:配置页表粒度的大小,例如4KB,16KB,64KB
- T1SZ:用来配置TTBR_EL1页表能管辖的大小,计算公式为2^(64-T1SZ)个字节
- T0SZ:用来配置TTBR_EL0页表能管辖的大小,计算公式为2^(64-T0SZ)个字节
在 ARM64 中,虚拟地址的高位并不是随便用的,而是受 TCR_EL1.T0SZ / T1SZ 限制。
与Cache相关的字段

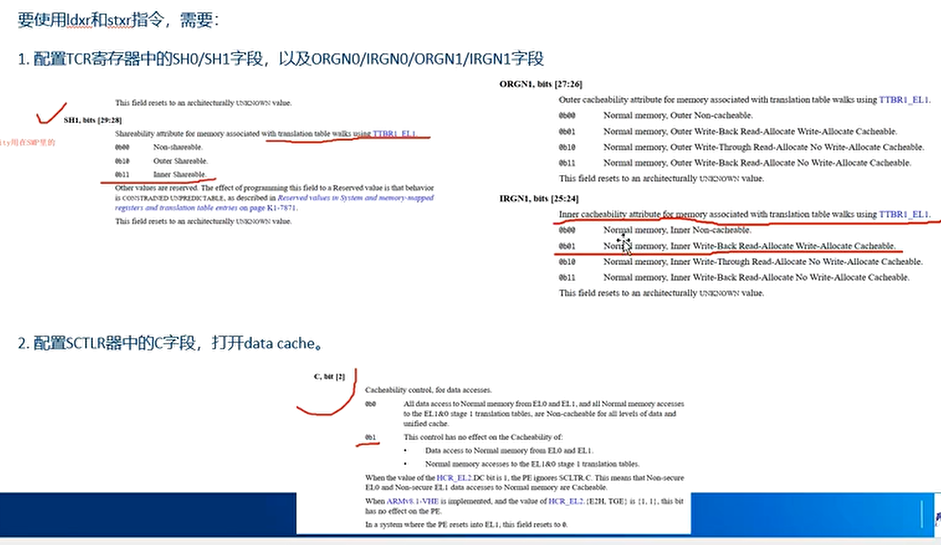
- SH1:设置内存相关的cache属性,这些内存是通过TTBR_EL1页表来访问的。例如Non-shareable, Outer Shareable,Inner Shareable
- SH0:设置内存相关的cache属性,这些内存是通过TTBR_EL0页表来访问的


- ORGN1:设置Outer Shareable的相关属性
- ORGN0: 设置Outer Shareable的相关属性
- IRGN1: 设置Inner Shareable 的相关属性
- IRGN0: 设置Inner Shareable 的相关属性

TCR_EL1 中 SH0/SH1、IRGN0/IRGN1、ORGN0/ORGN1 的字段,它们仅用于未进行地址翻译的内存区域(即当 MMU 被禁用时),或者在某些特殊上下文中作为“默认”属性。一旦 MMU 启用,内存属性完全由页表项 + MAIR_EL1 决定。
SCTLR_EL1
System Control Register (EL1)

- M:打开和关闭MMU
- I:打开指令cache
- C:打开data cache
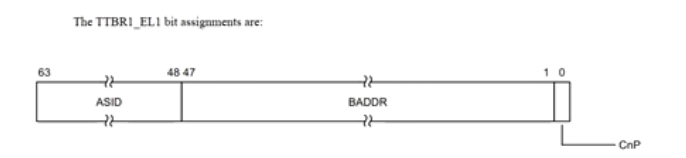
TTBR0_EL1
指向TTBR0页表的基地址,通常用于EL1/EL0的页表映射
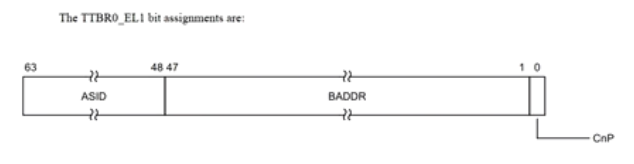
TTBR1_EL1
指向TTBR1页表的基地址,通常用于EL1/EL0的页表映射
MAIR_EL1
Memory Attribute Indirection Register



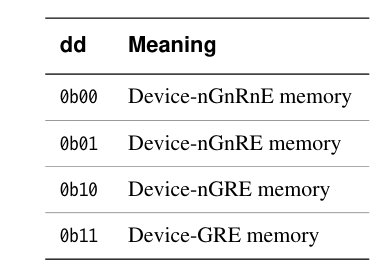
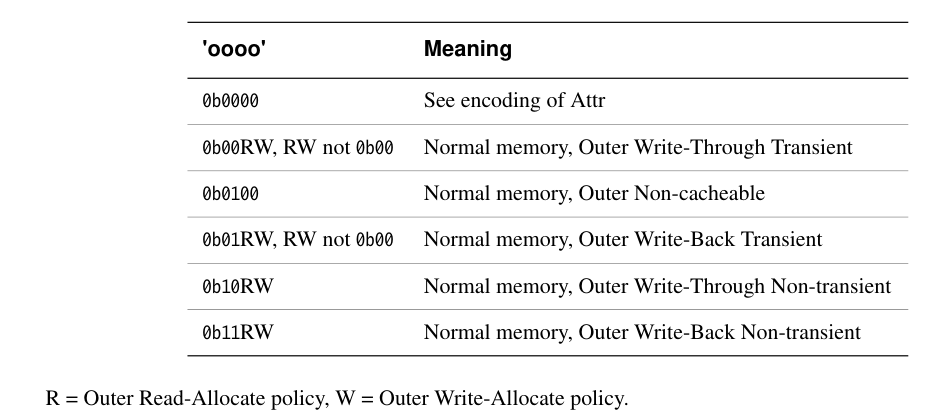
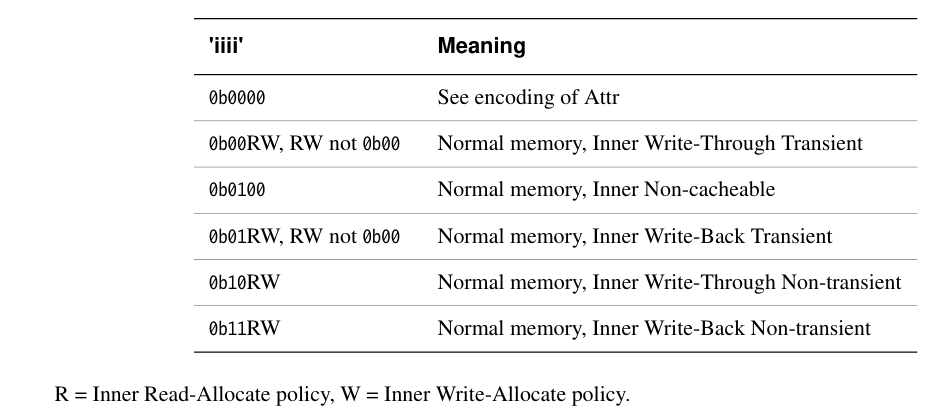
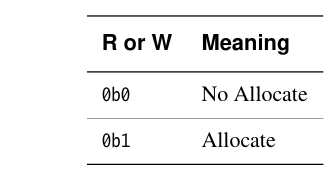
ARM 架构设计者认为:在绝大多数系统中,8 种内存类型已经足够覆盖所有使用场景
1 | // Linux内核中典型的MAIR配置 |
ID_AA64MMFR0_EL1
AArch64 Memory Model Feature Register 0,报告处理器对 页表、地址范围和内存特性的支持情况

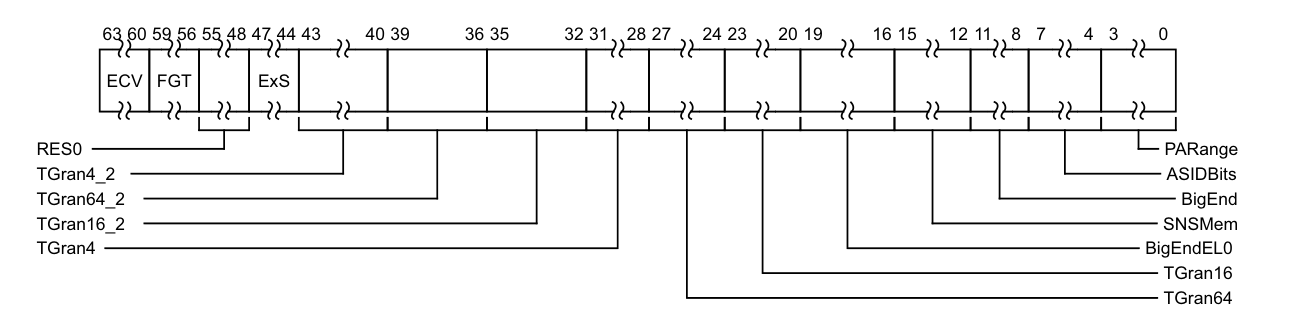
| 字段 | 位 | 含义 |
|---|---|---|
| PARANGE | [3:0] | 支持的物理地址位宽 |
| ASID | [7:4] | 支持的 ASID(Address Space ID)位数 |
| BIGENDEL | [11:8] | 支持 EL1/EL0 大页扩展 |
| SNSMEM | [15:12] | 是否支持安全内存访问 |
| BIGENDEL0 | [19:16] | 支持 EL0 大页扩展 |
| TGRAN16 | [23:20] | 支持 16KB 页 |
| TGRAN64 | [27:24] | 支持 64KB 页 |
| TGRAN4 | [31:28] | 支持 4KB 页 |
CPACR_EL1
Architectural Feature Access Control Register


FPEN 字段(CPACR_EL1[21:20])
FPEN = Floating-point Enable controls,控制 EL0/EL1 对 SVE、Advanced SIMD、浮点寄存器的访问是否被 EL1/EL2 捕获(trapped)。
- 寄存器影响:
- AArch64:
- FPCR、FPSR
- SIMD/Floating-point 寄存器
V0-V31(含 D0-D31 / S0-S31 视图)
- AArch32 / Advanced SIMD:
- FPSCR
- Q0-Q15(含 D0-D31 / S0-S31 视图)
- AArch64:
- 异常报告:
- EL0/EL1 捕获 → EC syndrome =
0x07 - EL2 捕获 → EC syndrome =
0x00(当 EL2 启用且HCR_EL2.TGE = 1)
- EL0/EL1 捕获 → EC syndrome =
| FPEN | 行为描述 |
|---|---|
| 0b00 | EL0 和 EL1 的指令都会被捕获,除非 CPACR_EL1.ZEN 已经捕获它们 |
| 0b01 | 仅 EL0 的指令会被捕获,EL1 不捕获 |
| 0b10 | EL0 和 EL1 的指令都会被捕获(与 0b00 相同) |
| 0b11 | 不捕获任何指令(寄存器可自由访问) |
简单来说:
FPEN 控制了 用户态 (EL0) 或内核态 (EL1) 是否可以直接使用浮点/SIMD/SVE 寄存器。开启MMU前通常要打开
配合 CPACR_EL1.ZEN,可以对不同级别的访问做精细控制。
常用配置:
0b11 → 不捕获,允许所有 EL0/EL1 指令访问 FP/SIMD。
0b00/0b10 → 捕获,通常用于安全或虚拟化场景。

MDSCR_EL1
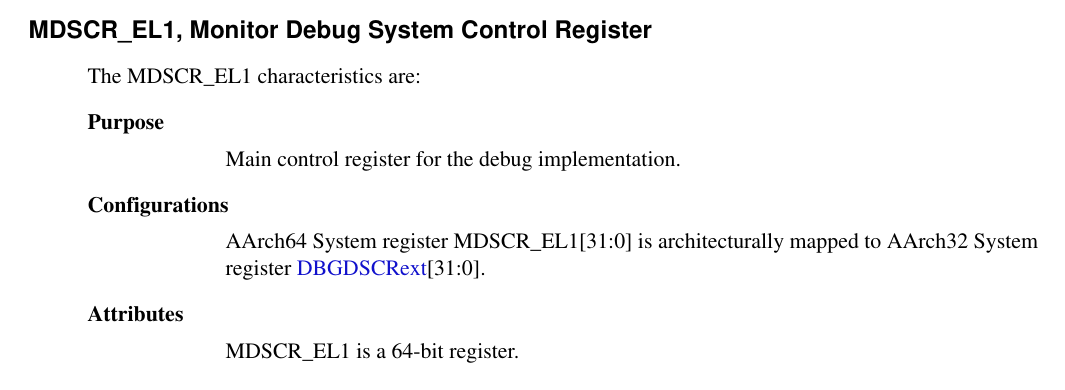
TDCC
TDCC = 0 → 用户态 EL0 可以直接读写 DCC 寄存器。
TDCC = 1 → EL0 访问 DCC 寄存器会被 trap 到 EL1/EL2,常用于 安全/虚拟化/调试控制。
DCC 是 调试通信通道(Debug Communication Channel),它提供了 CPU 与调试器(Debug Host)之间的数据传输接口,打开后才能使用Jtag

开启MMU
1 | // enable_mmu.S |
TBI(Top Byte Ignore)
ARMv8-A 架构里的 TBI(Top Byte Ignore)功能,也叫顶部字节忽略,它允许你把虚拟地址的最高 8 个 bit([63:56])用来存储额外信息,而不会影响内存访问。这个机制也叫 Tagged Pointers(标签指针),是 ARM 提供给编程语言和运行时系统的一个功能。
正常情况下地址必须合法
在 64 位系统中,寄存器是 64 位的,但虚拟地址并不是全 64 位——ARMv8 通常支持 48 位或 52 位虚拟地址。所以虚拟地址最上面的 16 位必须是符号扩展:
| 虚拟地址类型 | 高 16 位必须是 |
|---|---|
| 用户态内存 | 0x0000 |
| 内核高地址 | 0xFFFF |
如果你把 [63:48] 写成任意其他值,CPU 会触发地址异常(Address size fault)。
在 TCR_EL1 中开启 TBI 后(分别有 TBI0 和 TBI1 控制),CPU 会忽略地址的最高 8 位 [63:56],也就是说你可以随便往这 8 位写标记数据,用来存附加信息,不影响内存访问!
注意:内核/用户地址仍然由 VA[55] 决定,为1表示内核地址,为0表示用户地址空间。
在 TCR_EL1 中有两个字段:
TBI0→ 控制 EL0 使用 TTBR0 地址访问 时是否开启指针标签TBI1→ 控制 EL1 使用 TTBR1 地址访问 时是否开启指针标签
内存属性
ARMv8定义的内存属性
ARMv8架构处理器提供两种内存属性
普通内存(Normal Memory)
普通内存是弱一致性的(weakly ordered),没有其他额外约束,提供最高的内存访问性能
设备内存(Device Memory)
处理器访问设备内存会有很多限制,比如不能进行预测访问等。设备内存是严格按照指令顺序来执行的。ARMv8架构定义了多种设备内存的属性
- Device-nGnRnE (不支持聚合操作,不支持指令重排,不支持提前写应答)
- Device-nGnRE (不支持聚合操作,不支持指令重排,支持提前写应答)
- Device-nGRE (不支持聚合操作,支持指令重排,支持提前写应答)
- Device-GRE (支持聚合操作,支持指令重排,支持提前写应答)
Gathering or non Gathering (G or nG)
此属性确定是否可以将多个访问合并到此内存区域的单个总线事务中。
- 如果地址被标记为非聚合 (nG),那么内存总线上对该位置执行的访问次数和大小必须与代码中显式访问的次数和大小完全匹配。
- 如果地址被标记为 Gathering (G),则处理器可以例如将两个字节写入合并为单个半字写入。对于标记为 Gathering 的区域,还可以合并对同一内存位置的多个内存访问。
例如,如果程序读取同一个位置两次,核心只需要执行一次读取,就可以返回两条指令的结果相同。对于从标记为非 Gathering 的区域读取,数据值必须来自终端设备。不能从写缓冲区或其他位置窥探它。
Re-ordering (R or nR)
这决定了对同一设备的访问是否可以相互重新排序。如果地址被标记为非重新排序 (nR),则同一块内的访问始终按程序顺序出现在总线上。这个块的大小是实现定义(IMPLEMENTATION DEFINED)的。如果这个块的大小很大,它可以跨越几个表条目。在这种情况下,对于也标记为 nR 的任何其他访问,都遵守排序规则。
Early Write Acknowledgement (E or nE)
这确定是否允许处理器和正被访问的从设备之间的中间写缓冲区发送写完成的确认。在现代 SoC(系统级芯片)中,处理器(如 CPU)通过互连(Interconnect)访问外设或内存。为了提高性能,互连中通常会包含写缓冲区(Write Buffer),用来暂存尚未真正写入目标设备的数据。
但某些场景下,必须确保数据真的到达了目标设备之后才认为写操作完成(比如写寄存器触发硬件动作),而另一些场景则可以提前确认写入完成以提升吞吐量(比如写普通内存)。
这就引出了 E(Early)和 nE(not Early) 的区别。
如果地址被标记为非早期写确认 (nE),则写响应必须来自外设,即禁止提前确认。写完成信号必须由目标外设本身发出,即数据真正被外设接收后,才通知处理器写操作完成。
如果地址被标记为早期写入确认 (E),则允许互连逻辑中的缓冲区在终端设备实际接收到写入之前发出写入接受信号。这本质上是给外部存储系统的信息允许互连中的写缓冲区在数据尚未真正送达目标外设时,就向处理器发送“写完成”的确认信号。
Linux内核中定义

内存属性并没有存放在页表的页表项中,而是存放在MAIR_ELn寄存器(Memory Attribute Indirection Register)。
页表项中有一个3位的索引值(AttrInx[2:0])来查找MAIR_ELn寄存器。
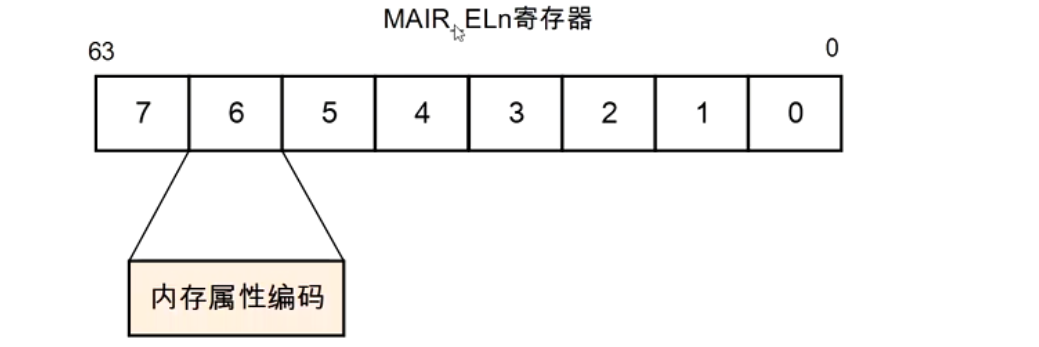
Linux内核中定义的内存属性
- 操作系统(Linux系统)根据armv8的定义的内存属性,以及内存的读写等属性,定义一些列属性
- PAGE_KERNEL:内存最普通的内存页面
- PAGE_KERNEL_RO:内核中只读的普通内存页面
- PAGE_KERNEL_ROX:内核中只读可执行的普通页面
- PAGE_KERNEL_EXEC:内核中可执行的普通页面
- PAGE_KERNEL_EXEC_CONT:内核中可执行的普通页面,并且是物理连续的多个页面

Linux5.0中的创建页表的例子
- 全局目录项 PGD (Page Global Directory)对应arm64的L0页表
- 上级目录项 PUD (Page Upper Directory)对应arm64的L1页表
- 中间目录项 PMD (Page Middle Directory)对应arm64的L2页表
- 页表项(Page Table Entry)对应arm64的L3页表
arch/arm64/mm/mmu.c
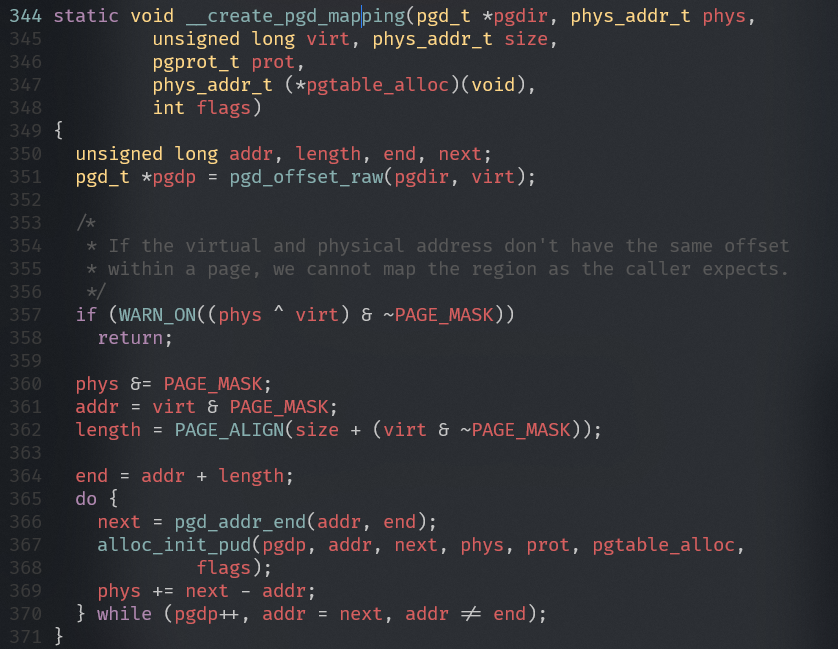
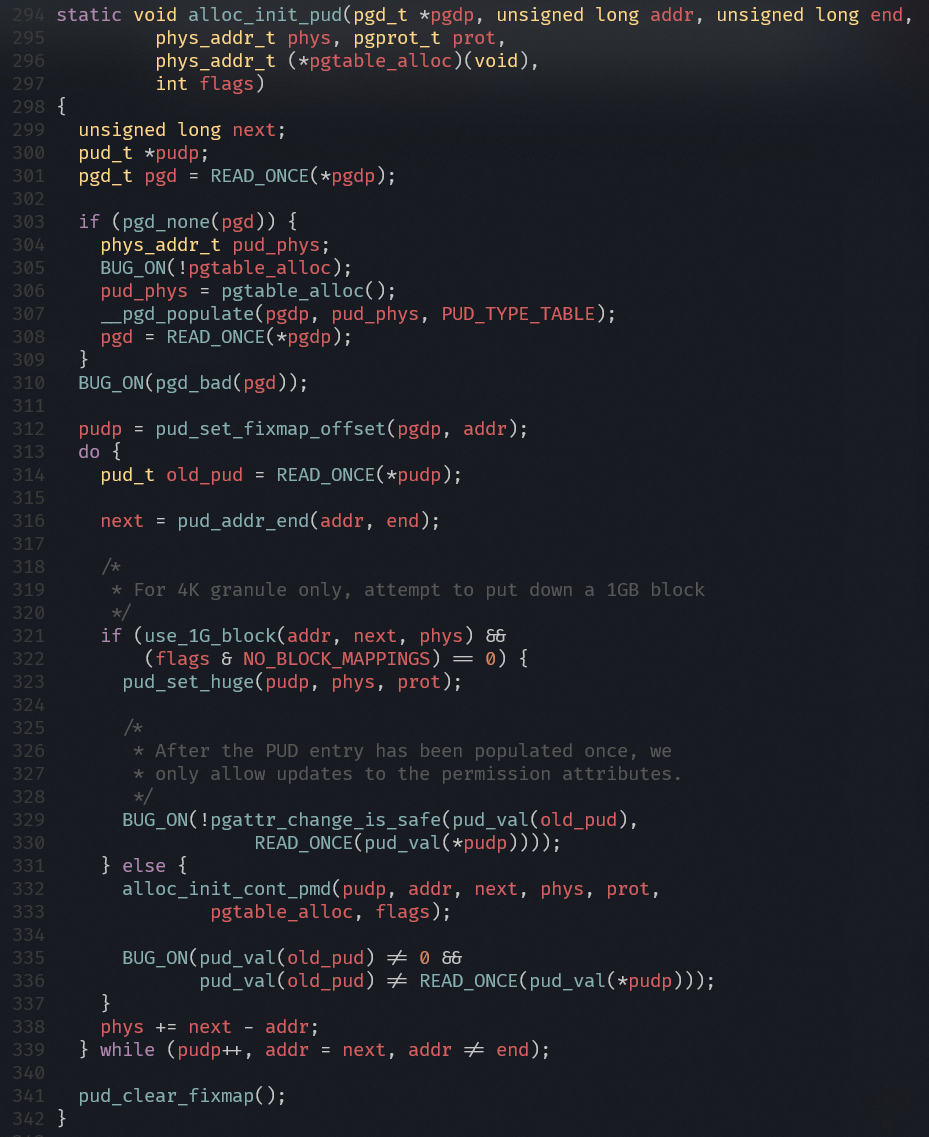
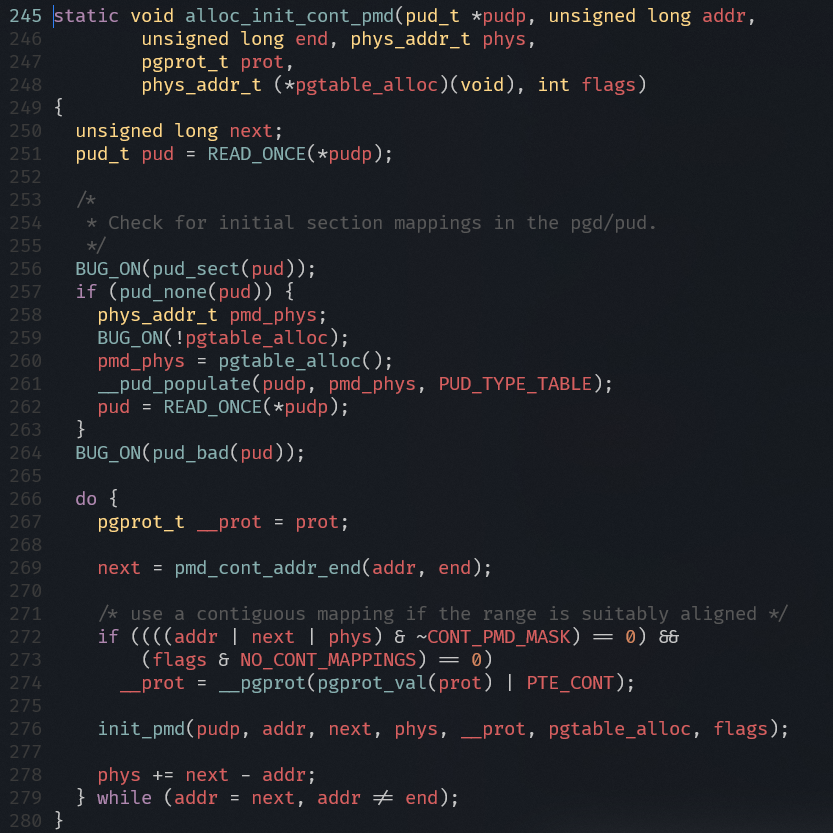
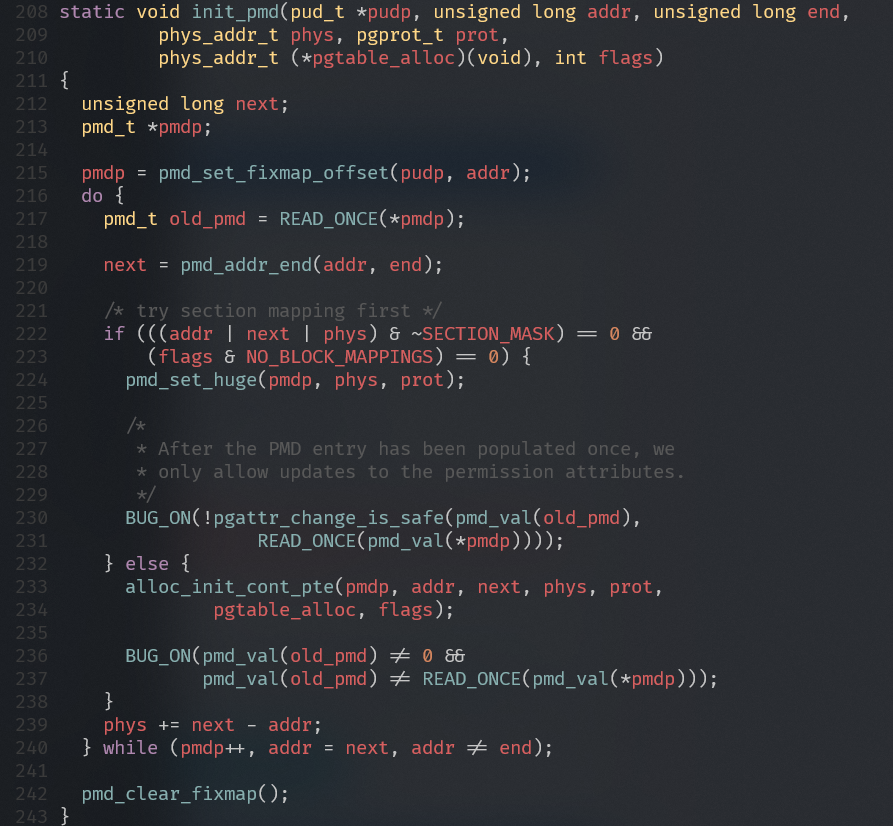
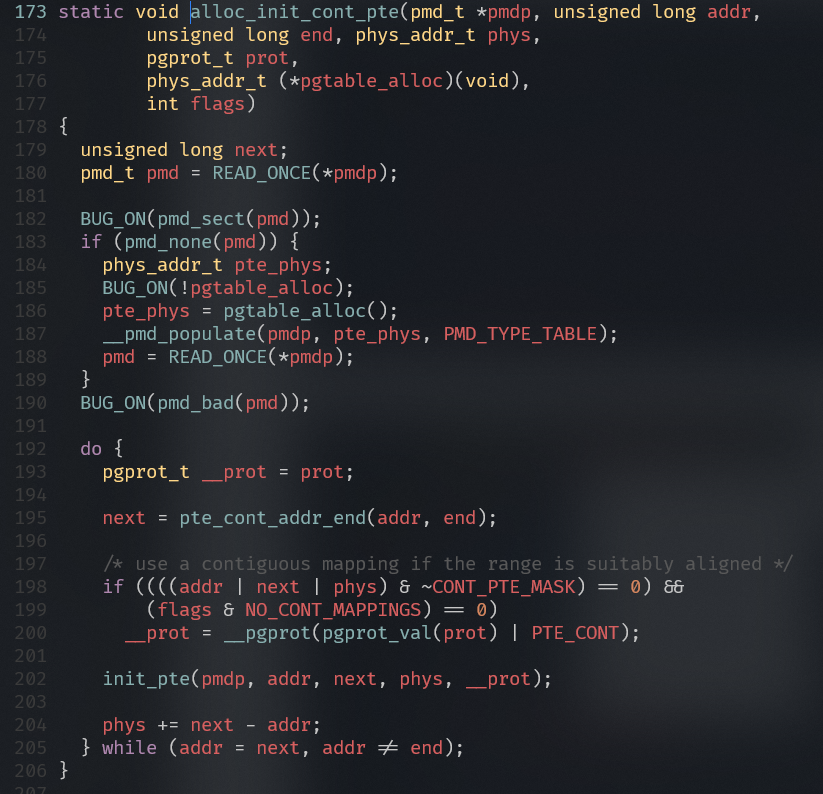
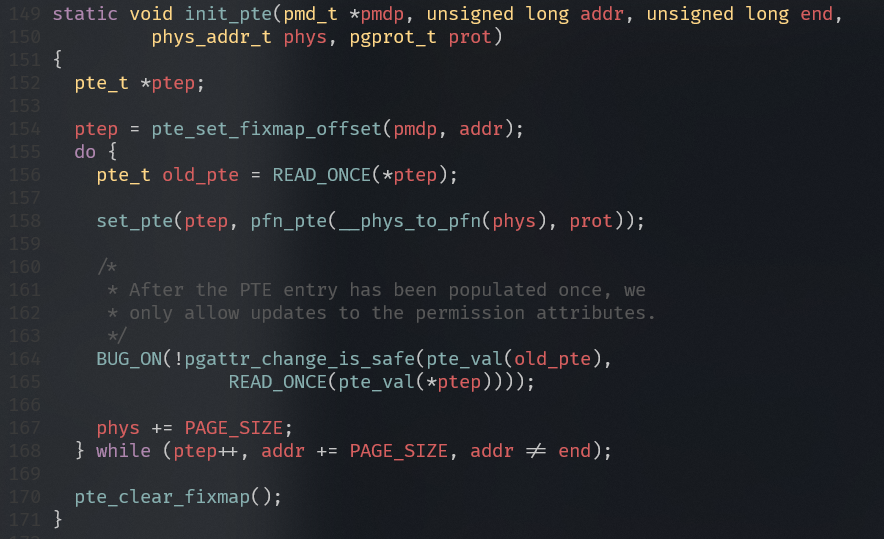
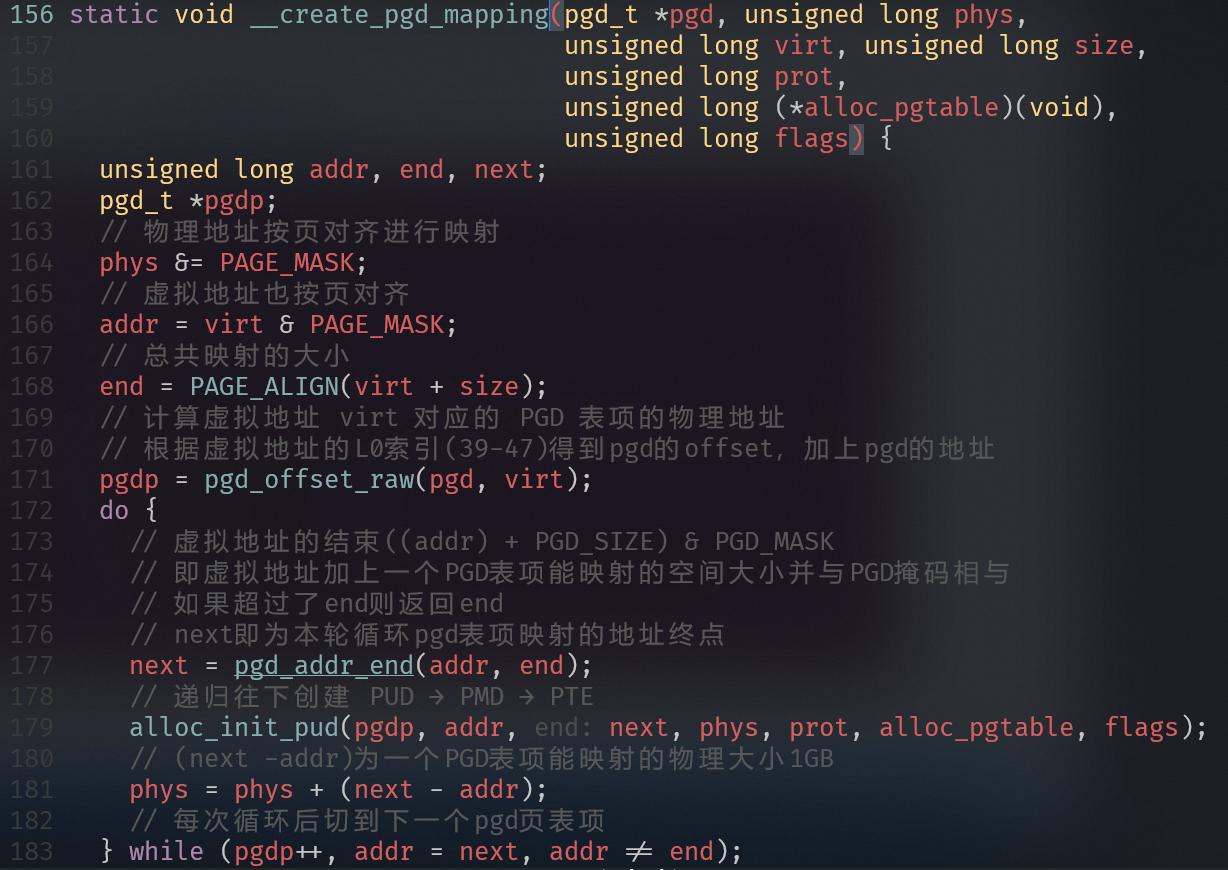
- 通过地址addr查找PGD表项

- 通过addr找到对应pgd的管辖范围的结束地址

- 设置pgd页表项

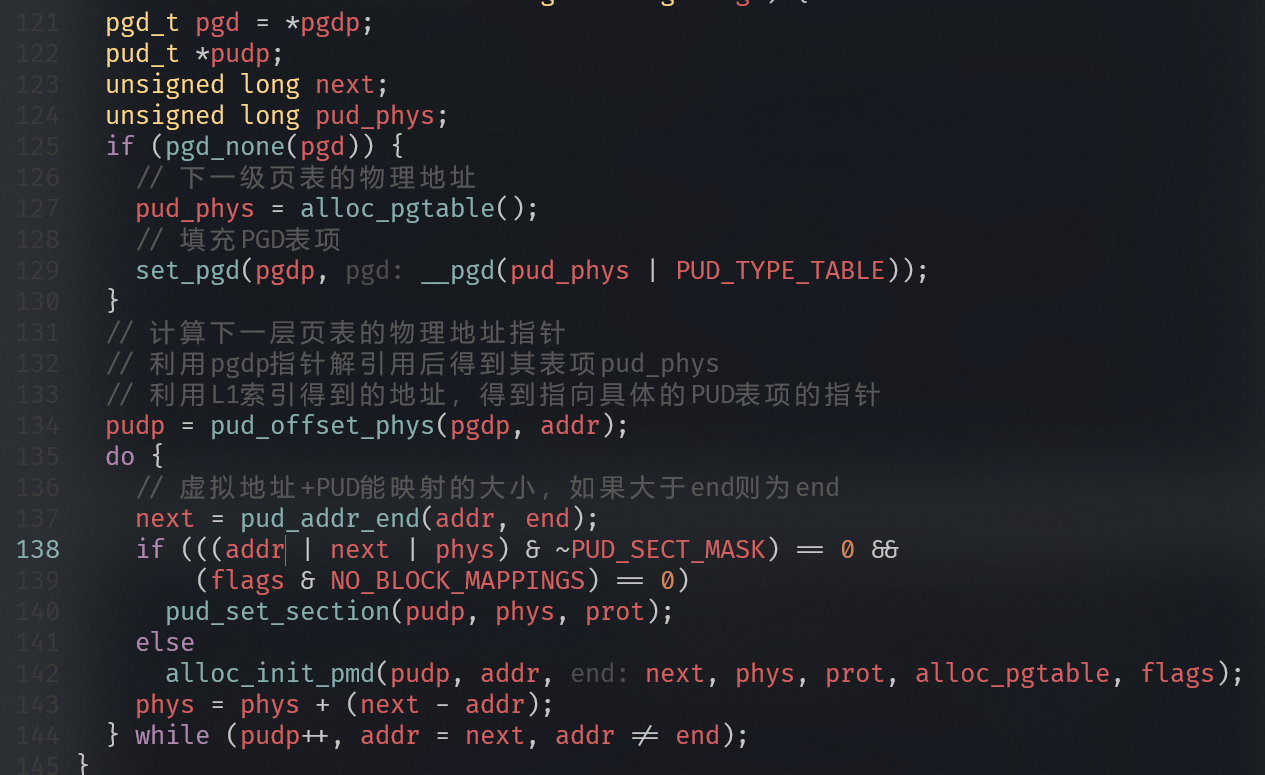
- 通过地址addr查找PUD的表项

实验
实验一:建立恒等映射

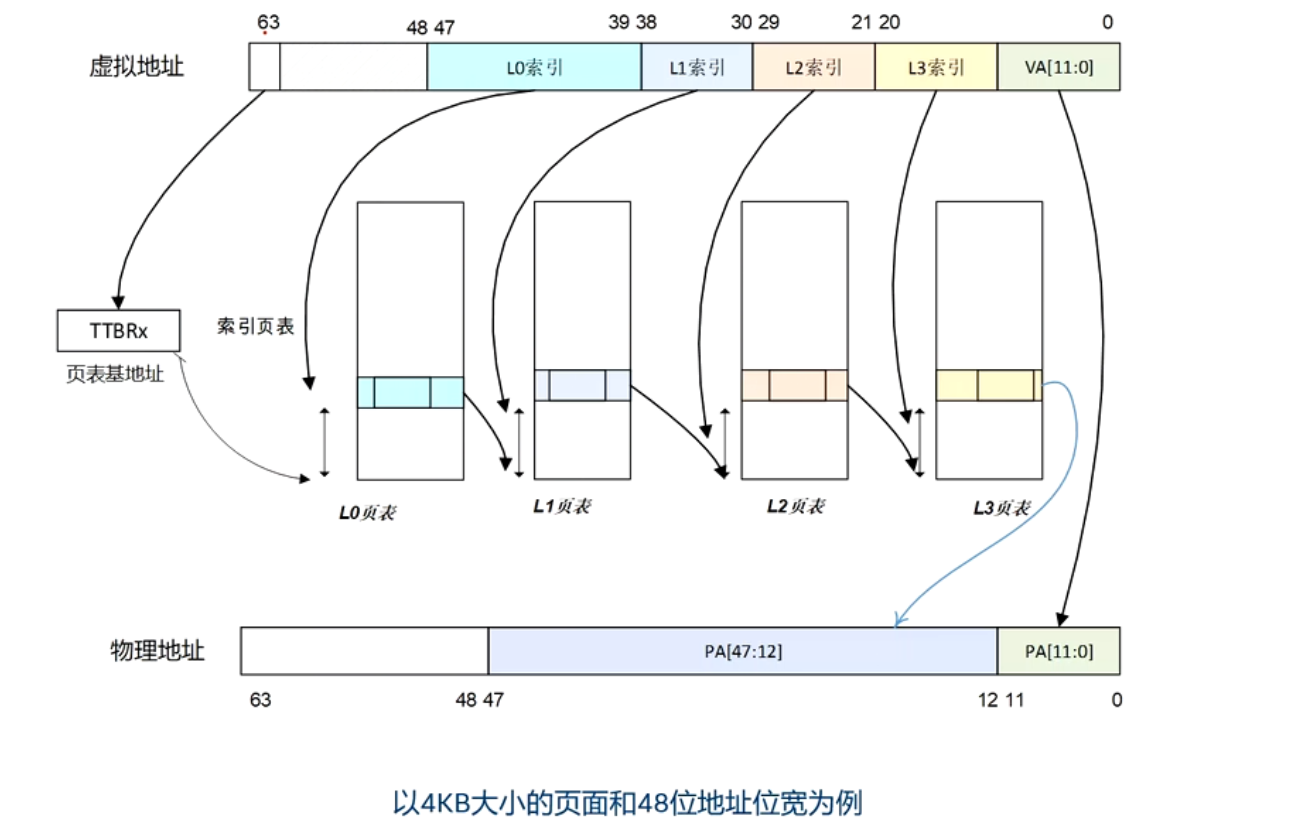
ARM64 使用 4级页表(PGD → PUD → PMD → PTE),每级使用 9 位索引(512 项),页大小为 4KB:
| 层级 | 名称 | 索引位 | 映射范围 | 表项数 | 表大小 |
|---|---|---|---|---|---|
| L0 | PGD | [47:39] | 512 GB | 512 | 4KB |
| L1 | PUD | [38:30] | 1 GB | 512 | 4KB |
| L2 | PMD | [29:21] | 2 MB | 512 | 4KB |
| L3 | PTE | [20:12] | 4 KB | 512 | 4KB |
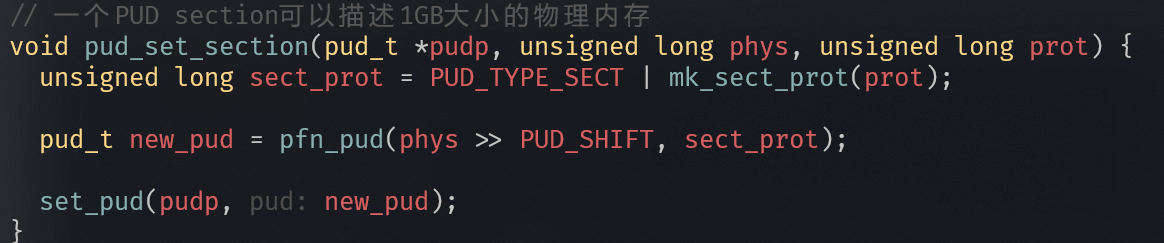
注:若某级页表项标记为 SECTION(块映射),则跳过下一级,直接映射大块内存。
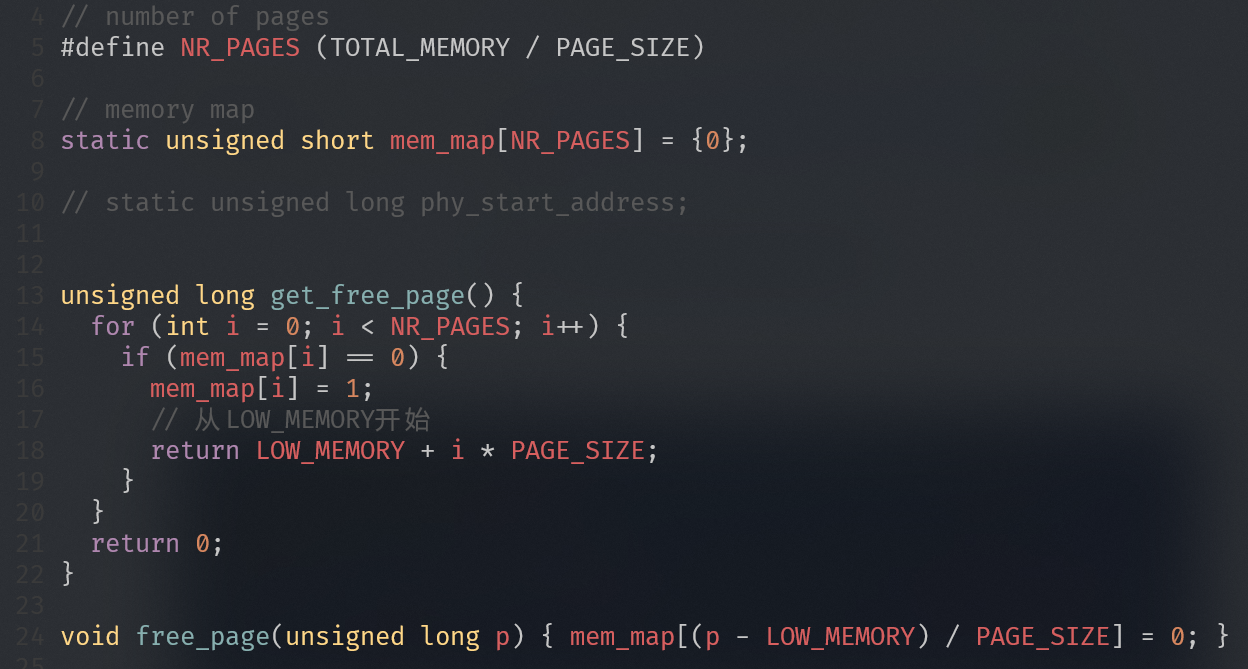

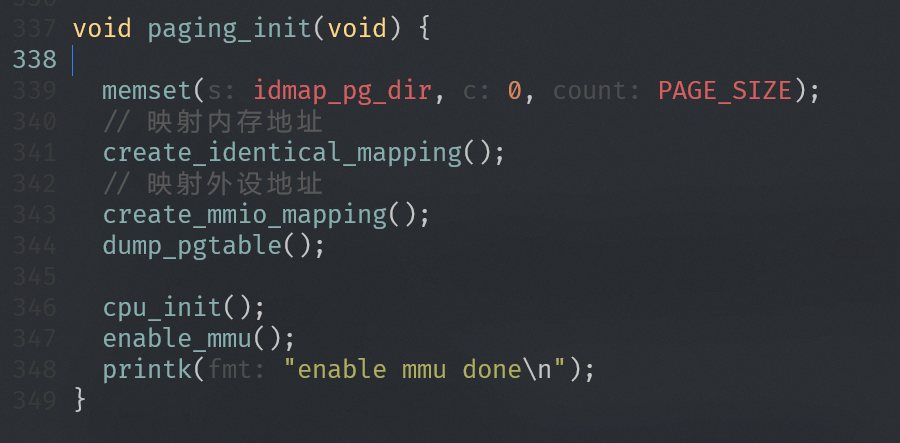

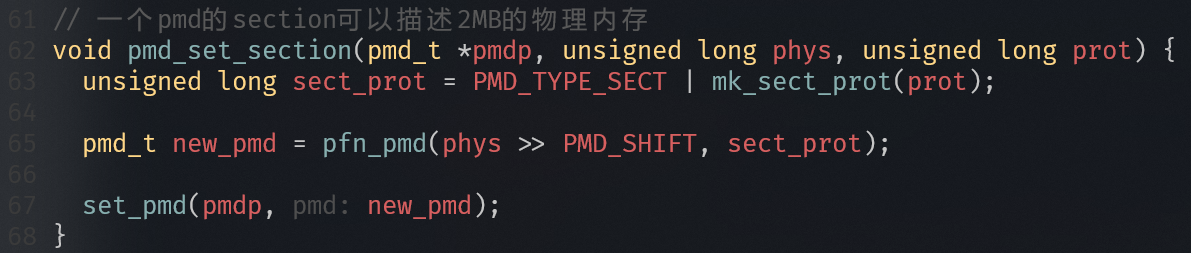
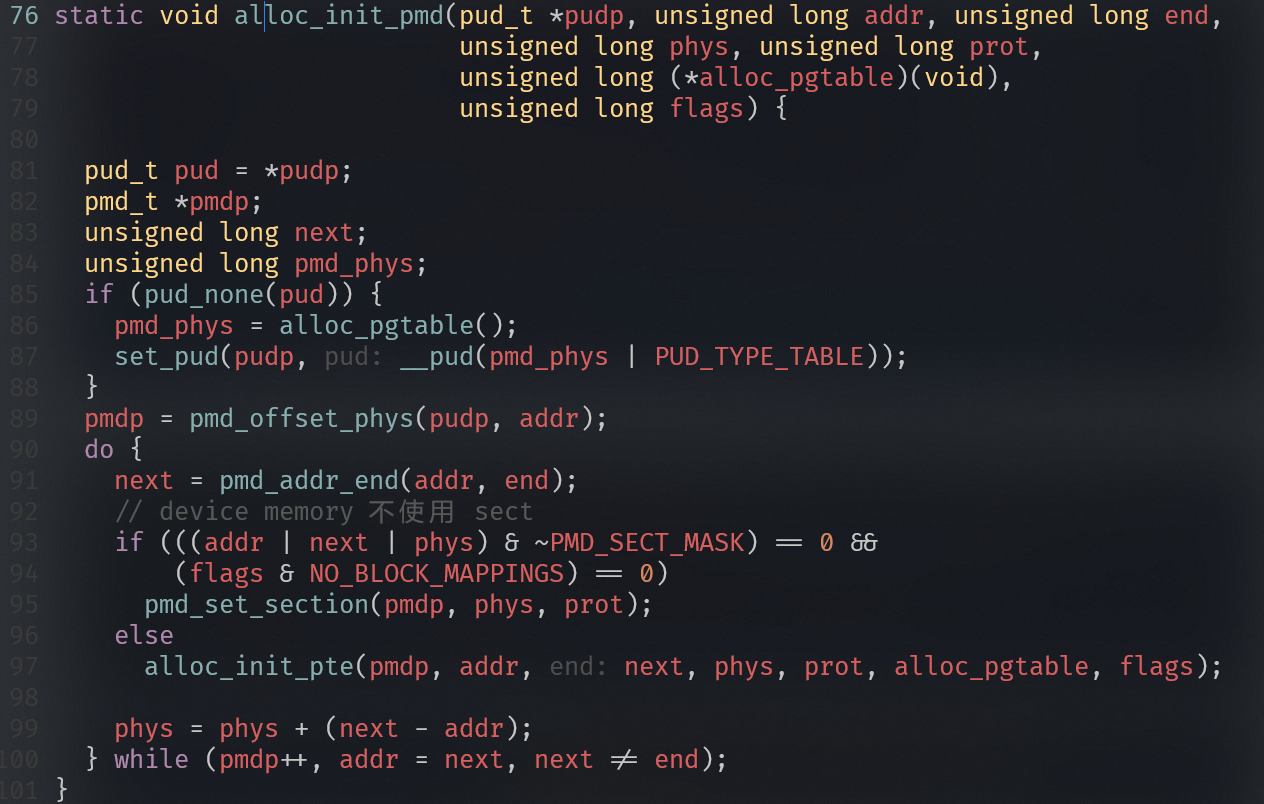
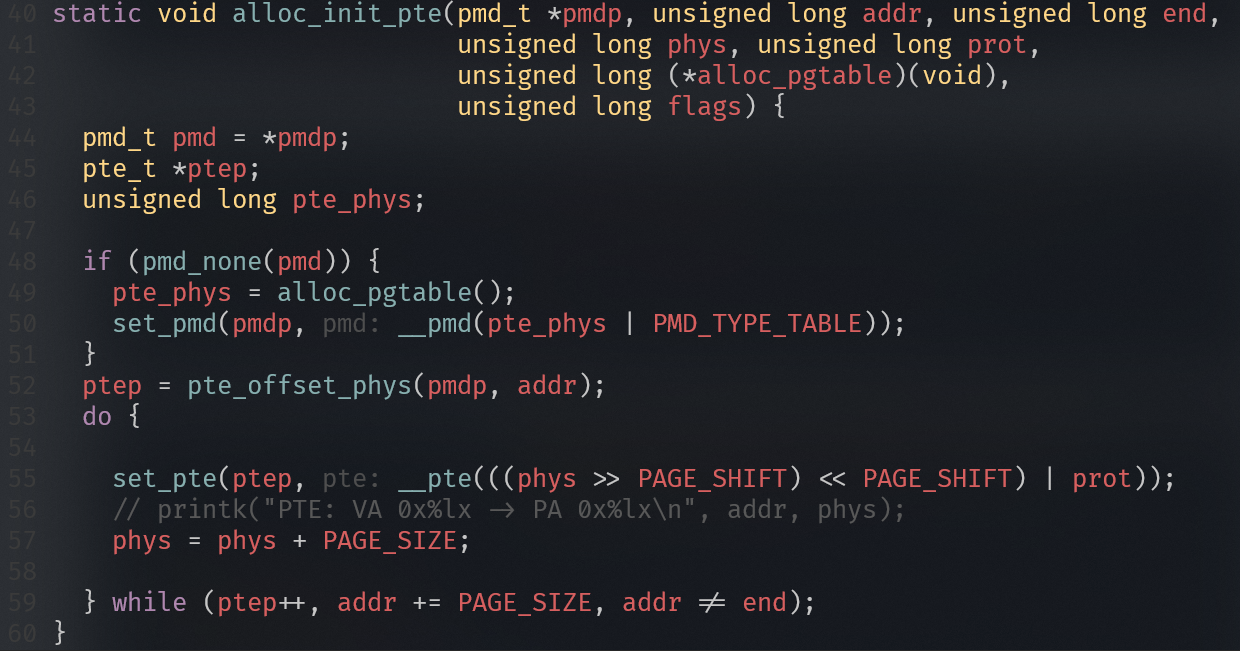
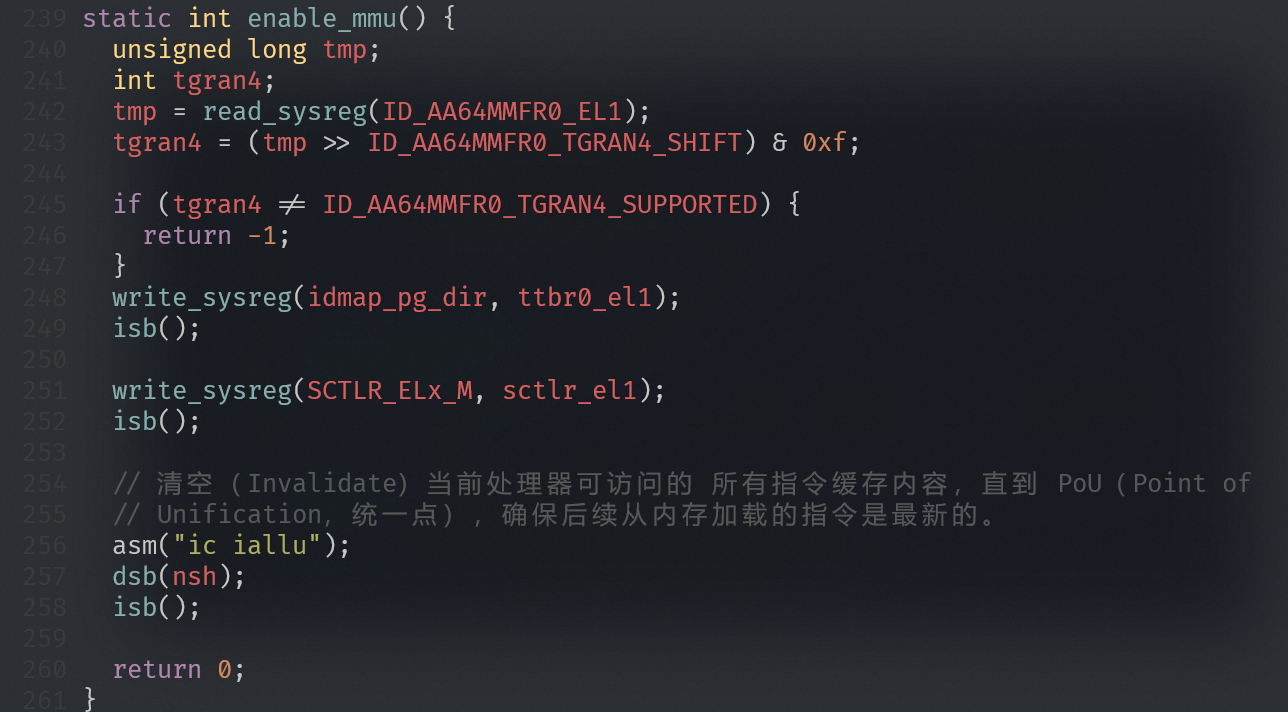
为什么要恒等映射
为了打开MMU不会出问题:
- 在关闭MMU情况下,处理器访问的地址都是物理地址。当MMU打开时,处理器访问地址变为虚拟地址
- 现代处理器都是多级流水线架构,处理器会提前预取多条指令到流水线中。当打开MMU时,处理器已经提前预取了多条指令,并且这些指令是以物理地址来进行预取的。当打开MMU指令执行完成,处理器的MMU功能生效。因此,这里是为了保证处理器在开启MMU前后可以连续取指令。
实验二:为什么MMU跑不起来

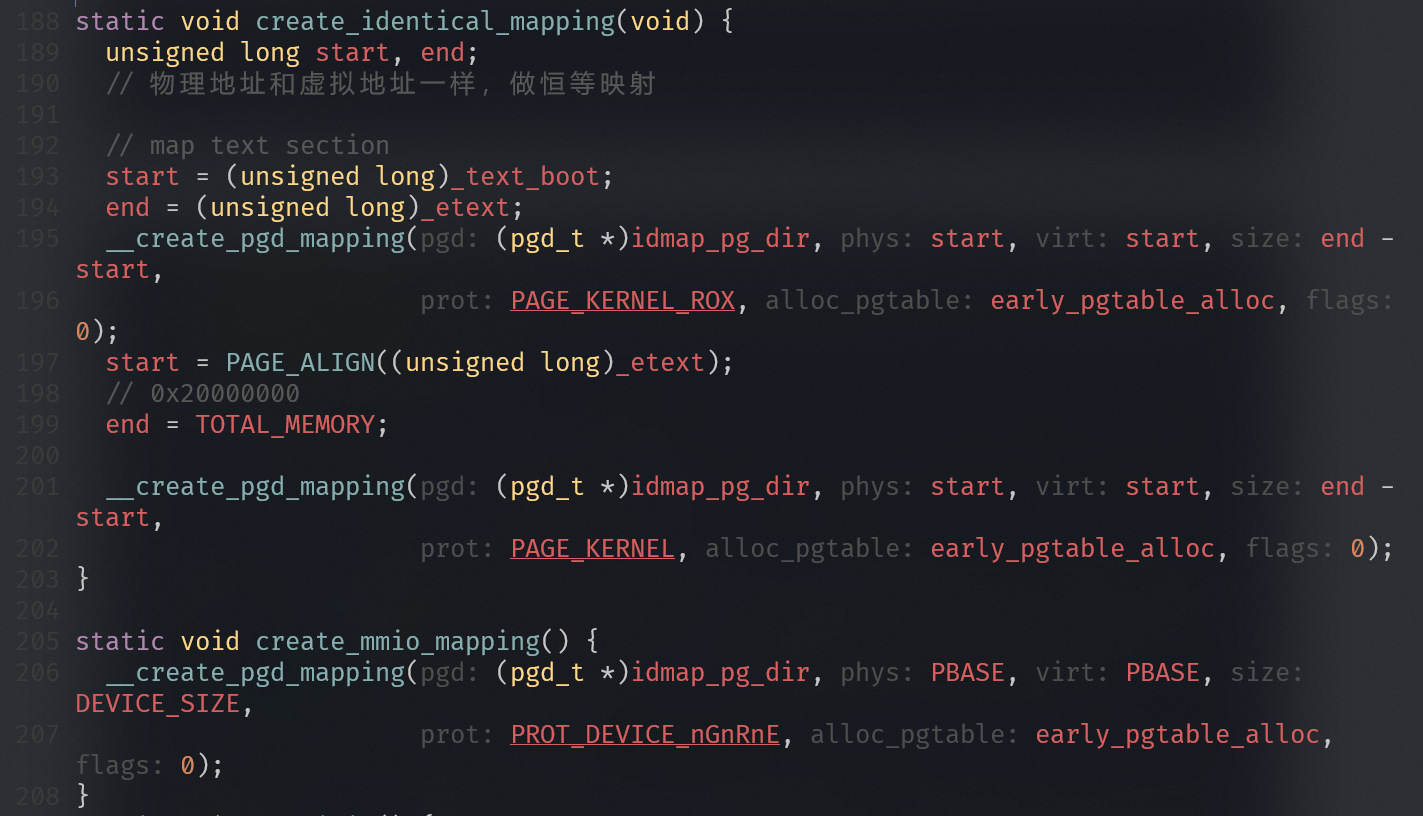
很明显,_text_boot到_etext的内存属性应该映射成PAGE_KERNEL_ROX
从_etext到TOTAL_MEMORY才是映射成PAGE_KERNEL
实验三:实现一个MMU页表dump的功能

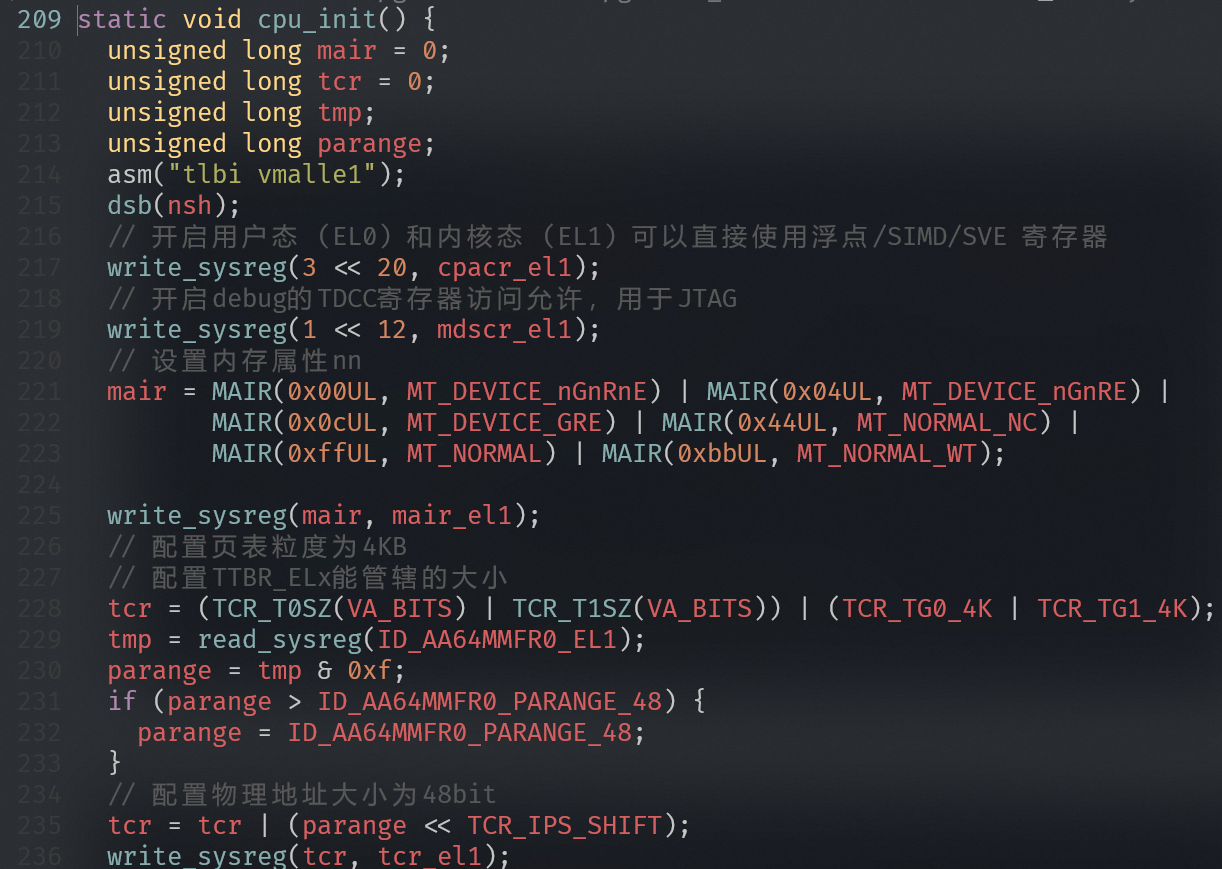
实验四:修改页面属性导致的系统宕机

小明同学做了这个实验,他在链接脚本里text段申请了一个4KB的只读页面,然后实现了一个walk_pgtable()的函数去遍历页表和查找对应的PTE,发现怎么设置都没法让页面设置为可写
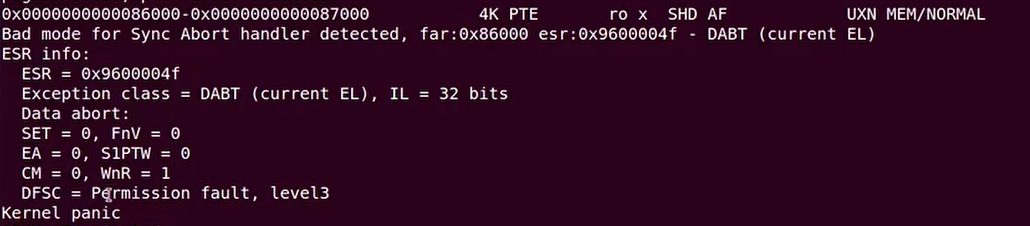


问题出在这里
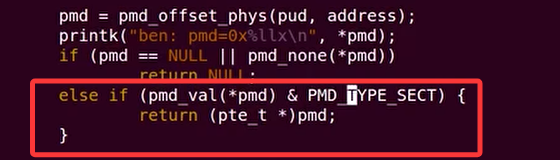
应改成

实验五:验证ldxr和stxr指令
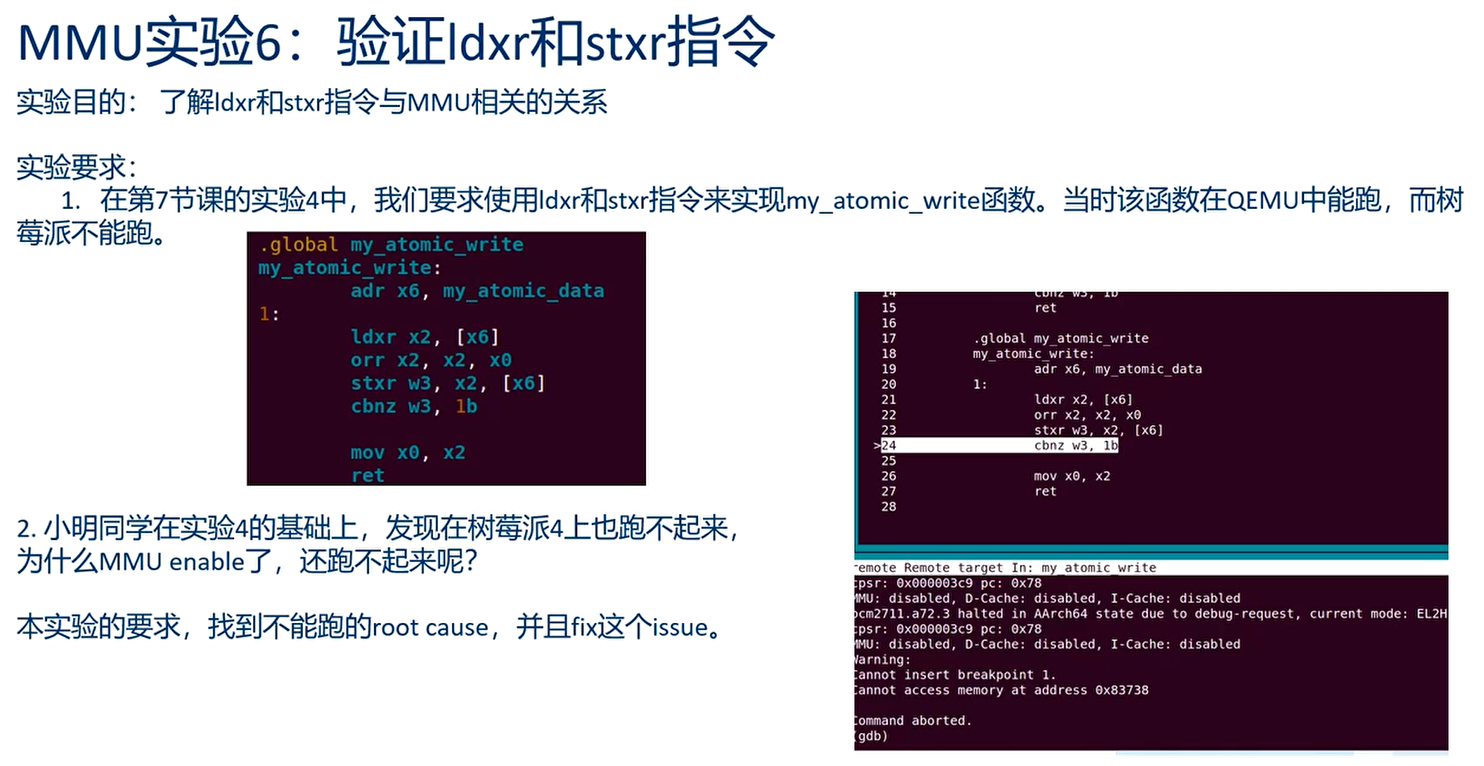

原因是我们没有设置sharable属性


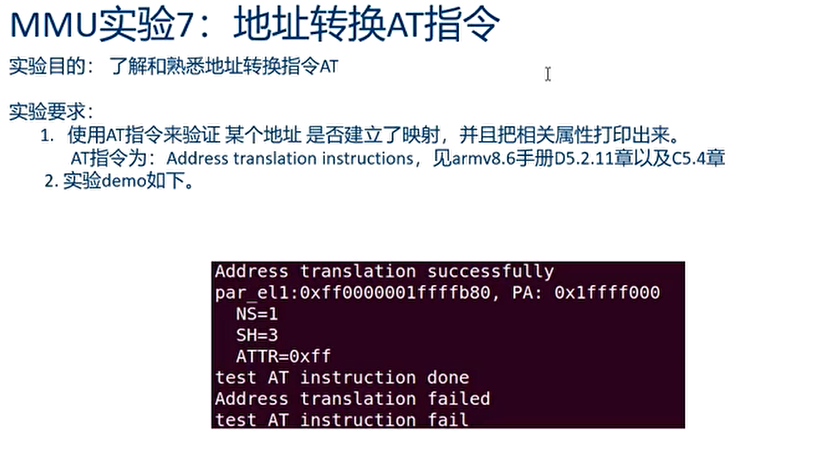
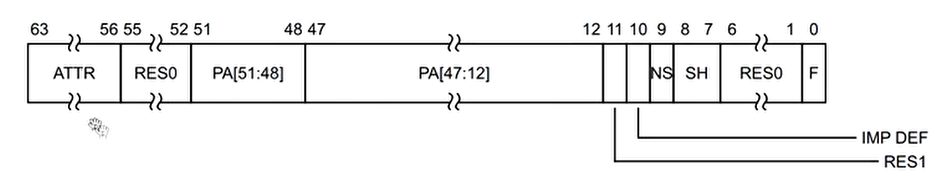
实验六:地址转换AT指令

MMU芯片手册阅读
TODO