ARM SVE/SVE2
时间轴
2025-10-30
init
参考文档:

SVE
Scalable Vecotr Extension
- SVE相关的手册:
- <<ARM Architecture Reference Manual Supplement, The Scalable Vector Extension>>
- <<ARM A64 Instruction Set Architecture ARMv9, for Armv9-A architecture profile>>
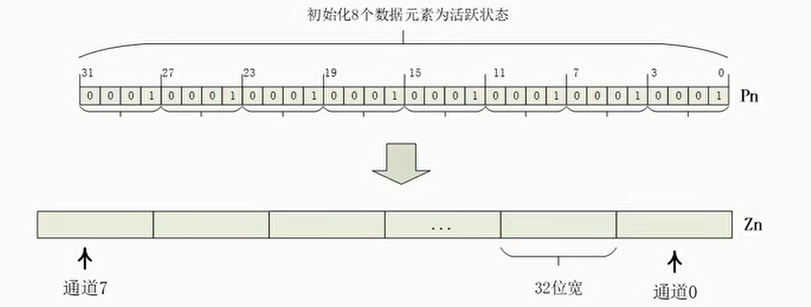
可扩展矢量指令SVE/SVE2
- SVE全称Scalable Vector Extension
- 第一版在ARMv8.2加入,第二版在ARMv9加入
- SVE是针对高性能计算(HPC)和机器学习领域开发的一套全新的矢量指令集,它是下一代SIMD指令集实现,而不是NEON指令集的简单扩展
- SVE指令集中有很多概念与NEON指令集类似,例如矢量,通道,数据元素等
- SVE提出一个全新的概念:可变矢量长度编程模型 (Vector Length Agnostic,VLA)
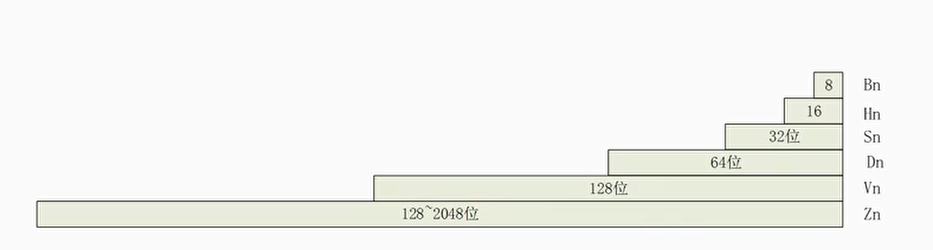
SVE寄存器
- 32个全新的可变长矢量寄存器Z0~Z31
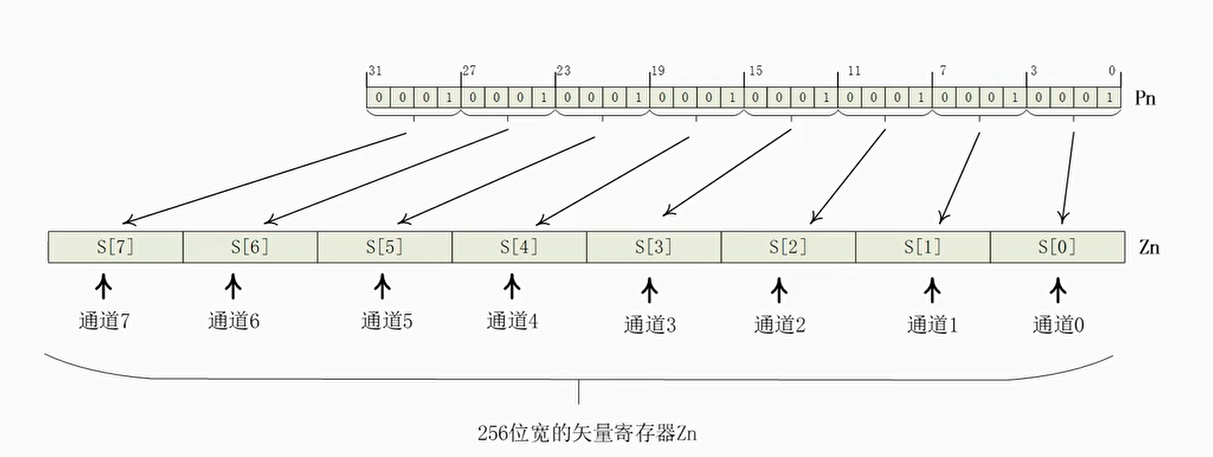
- 16个可预测寄存器(predicate register)P0~P15
- 首次错误预测寄存器(First Fault predicate Register,FFR)
- SVE控制寄存器ZCR_ELx
设置矢量寄存器长度
| 寄存器类型 | 名称 | 数量 | 每个寄存器长度 | 说明 |
|---|---|---|---|---|
| Z 寄存器 | Z0–Z31 |
32 个 | VL bits | 向量数据寄存器 |
| P 寄存器 | P0–P15 |
16 个 | VL / 8 bits | 预测寄存器(mask) |
| FFR | FFR |
1 个 | VL / 8 bits | 最终掩码(First-Fault Register) |
矢量长度称为vector length
可变长矢量寄存器
预测寄存器
SVE指令语法
- SVE指令格式由操作代码,目标寄存器,P寄存器和输入操作符组成
1 | LD1D {<Zt>.D}, <Pg>/Z, [<Xn|SP>, <Xm>, LSL #3] |
1 | ADD <Zdn>.<T>, <Pg>/M, <Zdn>.<T>, <Zm>.<T> |
SVE实验环境
早期 Cortex-A 核心
- Cortex-A53 / A55 / A57 / A72 / A76 / A77 / A78
- 仅支持 NEON(128-bit SIMD),不支持 SVE 或 SVE2
QEMU
1 | qemu-system-aarch64 -m 1024 -cpu max,sve=on,sve256=on -M virt,gic-version=3,its=on,iommu=smmuv3\ |
SVE特有编程模式1:预测指令
- SVE指令集为了支持可变长矢量计算提供了预测管理机制(Governing predicate)
- 预测指令会使用预测管理机制来预测矢量寄存器中活跃状态的数据元素有哪些。在预测指令中仅仅处理这些活跃状态的数据元素,对于不活跃的数据元素是不进行处理的。
- 例子:
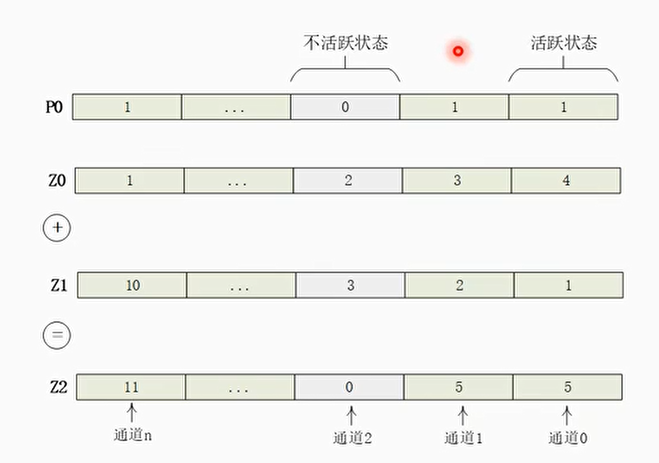
合并预测与零预测
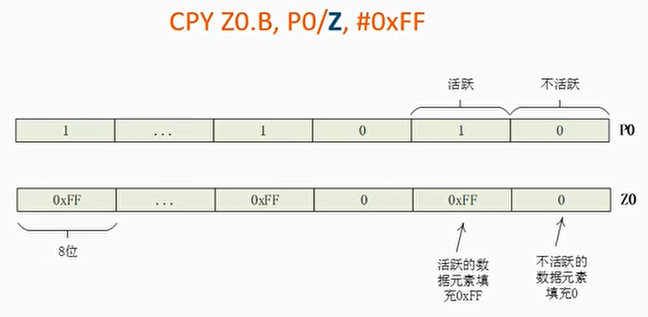
- 零预测(zeroing predication):在目标矢量寄存器中,不活跃状态数据元素的值填充0
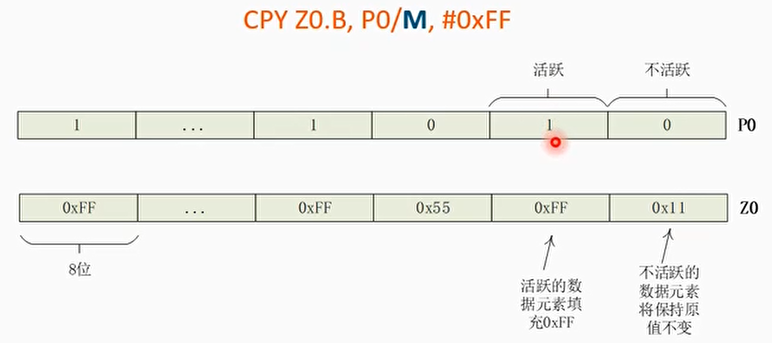
- 合并预测(merging predication):在目标矢量寄存器中,不活跃状态数据元素保持原值不变
零预测
合并预测
SVE特有编程模式2:聚合加载和离散存储
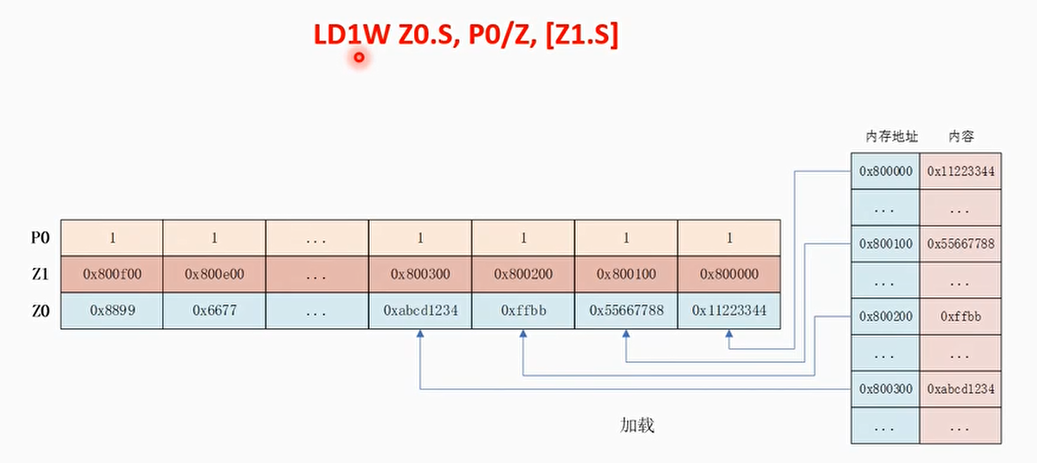
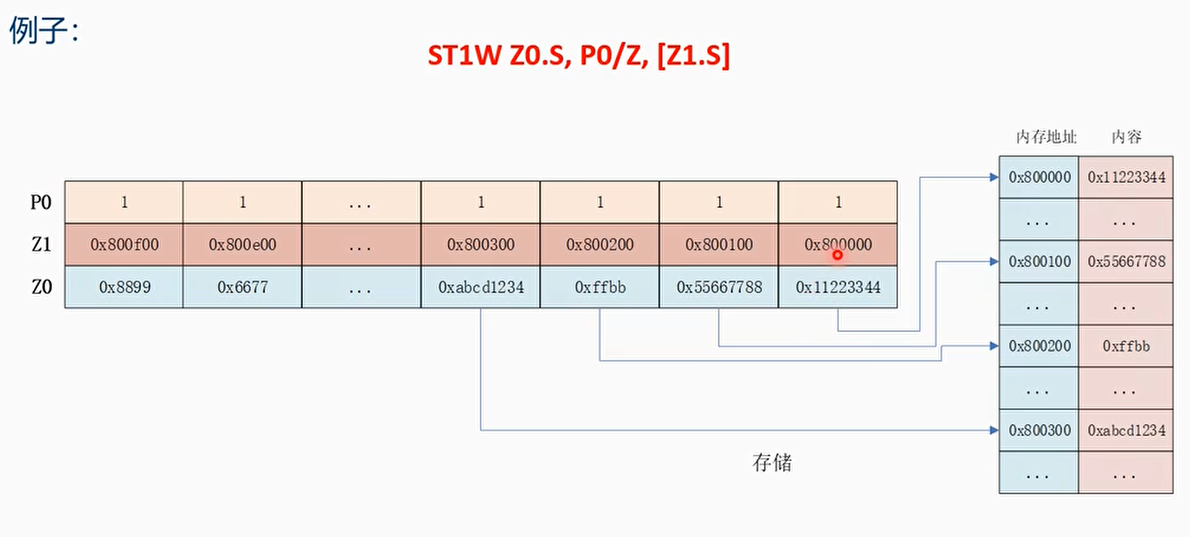
- 支持聚合加载(Gather-load)和离散存储(scatter-store)模式
- 聚合加载和离散存储指的是可以使用矢量寄存器中每个通道的值作为基地址或者偏移量来实现非连续地址的加载和存储
- 传统的NEON指令集只能支持线性地址的加载和存储功能
例子:聚合加载,加载多个离散地址的值
离散存储
SVE特有编程模式3:基于预测的循环控制
- 以预测寄存器Pn中活跃状态的数据元素为对象来实现循环控制的
- PSTATE与NVCZ状态标志位
- SVE指令集提供如下几组与循环控制相关的指令
- 初始化预测寄存器的指令,例如WHILELO等
- 根据预测约束条件增加数据元素的统计计数,例如INCB等
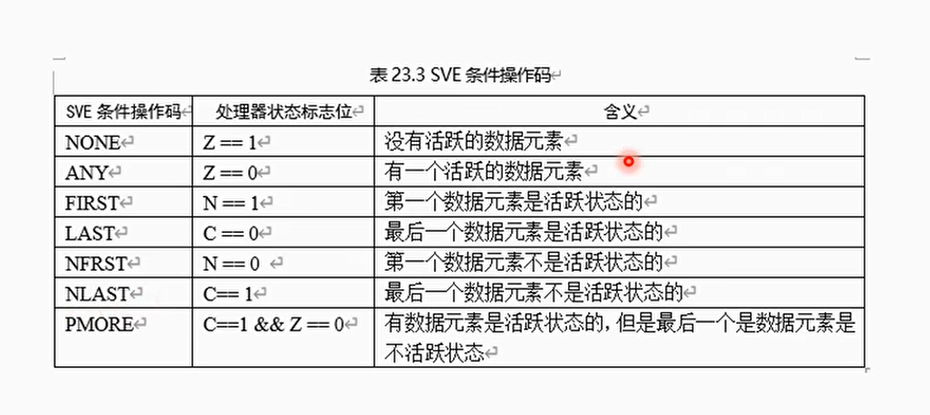
- 根据SVE条件操作码,与跳转指令结合来完成条件跳转功能,例如B.FIRST等
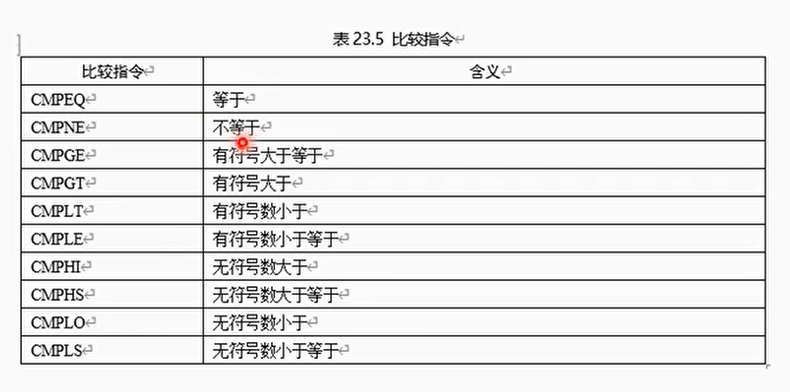
- 基于数据元素为对象的比较指令,例如CMPEQ指令等
- 退出循环指令,例如BRKA指令
PSTATE处理器状态和NCZV
- 以数据元素为对象的循环控制方法可以和处理器状态PSTATE有机结合起来
- 当SVE生成一个预测结果时会更新PSTATE的NCVZ状态标志位
- SVE指令会根据预测寄存器的结果或者FFR寄存器来更新PSTATE的NCVZ状态标志位
- SVE指令也可以根据CTERMEQ/CTERMNE指令来更新PSTATE的NCVZ状态标志位

初始化预测寄存器指令
类似C语言的while循环,给定一个初始值和目标值,以一个矢量寄存器包含数据元素的个数为步长,然后以递增或者递减的方式来遍历并初始化预测寄存器中的数据元素

以whilelt为例
1 | whilelt <pd>.<T>, <Rn>, <Rm> |
- <pd>:目标预测寄存器(如 p0、p1)
- <T>:元素类型(如 .b, .h, .s, .d)
- <Rn>:起始索引或计数寄存器
- <Rm>:结束索引或上限寄存器
1 | p[i] = (Rn + i*sizeof(T)/8 < Rm) ? 1 : 0 |
- 从 Rn 开始,逐个元素地比较索引;
- 只要当前索引还“小于 Rm”,就把对应的
p位设置为 1; - 一旦超出,就置 0。
| 类型 | 元素位宽 | 每步增量(bytes) | 举例 |
|---|---|---|---|
.b |
8-bit | 1 | 1 字节对齐 |
.h |
16-bit | 2 | 2 字节对齐 |
.s |
32-bit | 4 | 4 字节对齐 |
.d |
64-bit | 8 | 8 字节对齐 |
例子
1 | whilelt p0.b, xzr, x2 |
- p0.b b表示要预测的寄存器通道数是8位宽
- xzr是起始值
- x2是目标值,从低到高以递增方式达到x2为止或者已经初始化完预测寄存器中所有值
SVE条件操作码
根据预测约束条件增加数据元素的统计计数

基于数据元素为对象的比较指令
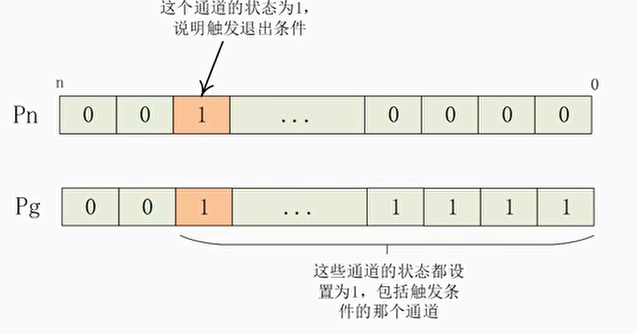
Break循环指令
- BRKA指令
1 | BRKA <Pd>.B, <Pg>/<ZM>, <Pn>.B |
break after
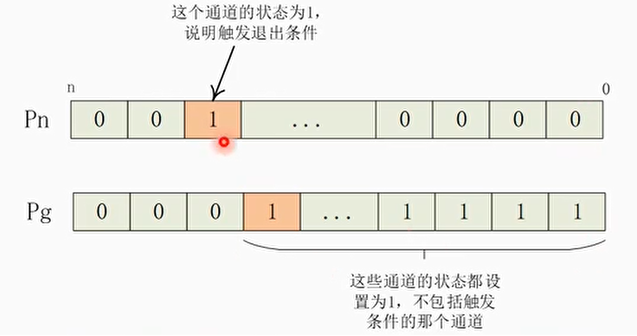
- BRKB指令
1 | BRKB <Pd>.B, <Pg>/<ZM>, <Pn>.B |
实验2:使用SVE指令实现memcpy_1b()函数

1 | .global sve_ld1_test |
假设VL是256,那么p0最多可以描述32个8位宽(B)的计数寄存器,所以incb x3会让x3从0变为32(32个字节)
whilelt p0.b, x3, x2这条指令当x3=32时,p0.b全为0
b.any表示只要矢量寄存器中有一个元素是活跃的都会触发跳转
实验3:使用SVE指令实现memcpy_4b()函数

1 | .global sve_ld1_test |
SVE特有编程模式4:基于软件推测的向量分区
- NEON不支持推测式加载操作(speculative load),SVE支持
- 推测式加载操作遇到的难题:如果在读取过程中某些元素发生内存错误(memory fault)或者访问了无效页面(invalid page),可能很难跟踪究竟是哪个通道的数据读取操作造成的
- SVE引入:
- 首次异常预测寄存器(First-Fault predicate Register,FFR)
- 首次异常加载指令,例如LDFF1B
例子:
1 | LDFF1D Z0.D, P0/Z, [Z1.D] |
以Z1.D寄存器中每个通道的值为基地址,加载其地址对应的元素到Z0
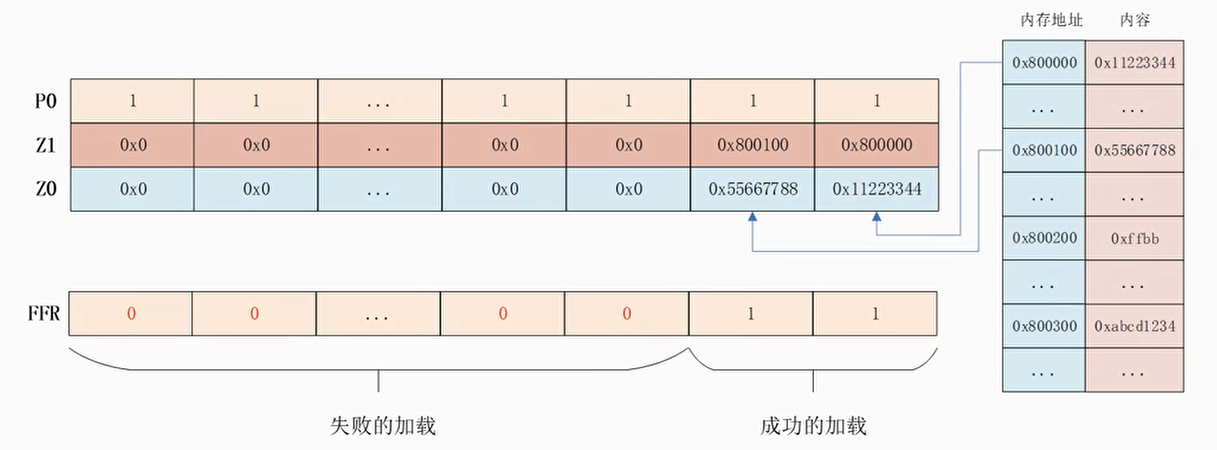
第三个通道是无效地址,直接标记为加载失败而不向CPU报告
SVE/SVE2指令
- SVE是在ARMv8.2加入,SVE2是在ARMv9加入
- SVE/SVE2指令手册:<<Arm A64 Instruction Set Architecture Armv9, for Armv9-A architecture profile>>
- SVE指令集包含了几百条指令,它们可以分成如下几大类
- 加载存储指令以及预取指令
- 向量移动指令
- 整数运算指令
- 位操作指令
- 浮点数运算指令
- 预测操作指令
- 数据元素操作指令
- 如何阅读指令手册:

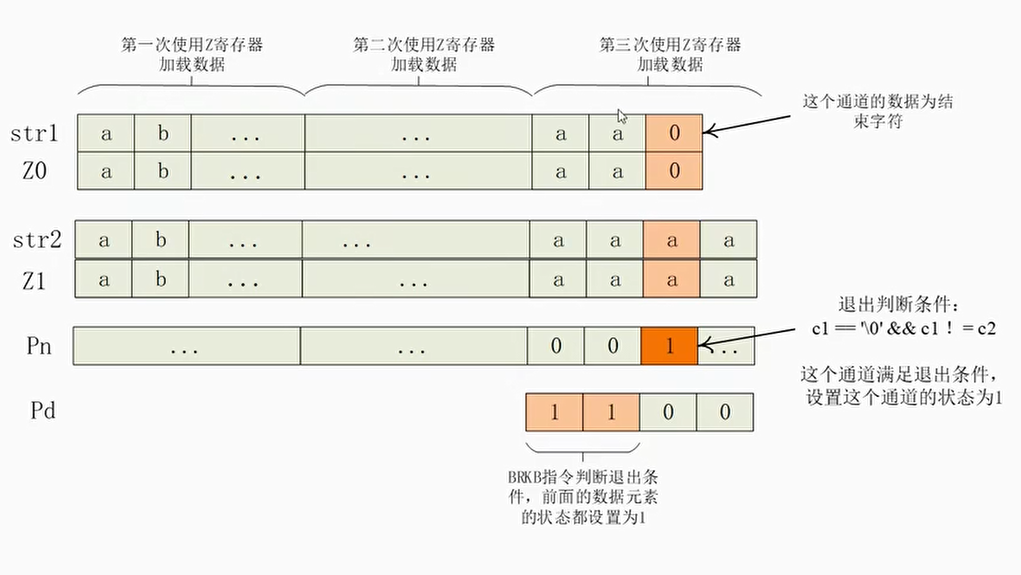
实验4:案例分析1-使用SVE指令来优化strcmp函数

- 使用SVE指令来优化strcmp()有两个难点:
- 难点1:字符串str1和str2的长度是未知的。在C语言中通过判断字符是否为’\0’来确定字符串的结束。而矢量运算中,SVE加载指令一次装载多个通道的数据。如果装在了字符串结束后的数据,那么会造成非法访问,导致程序出错。
- 难点2:尾数问题
1 | .global strcmp_sve |
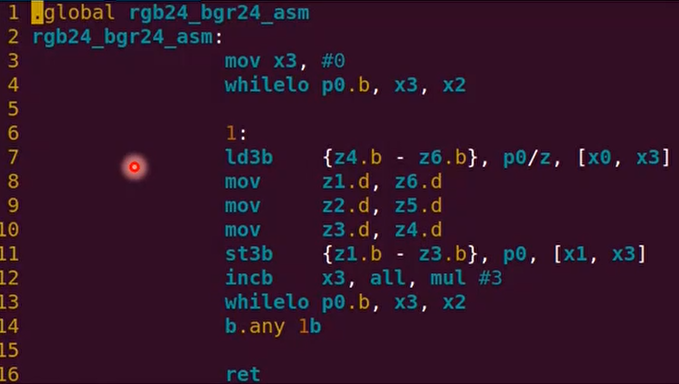
案例5:RGB24转BGR24
案例6:4×4乘积矩阵
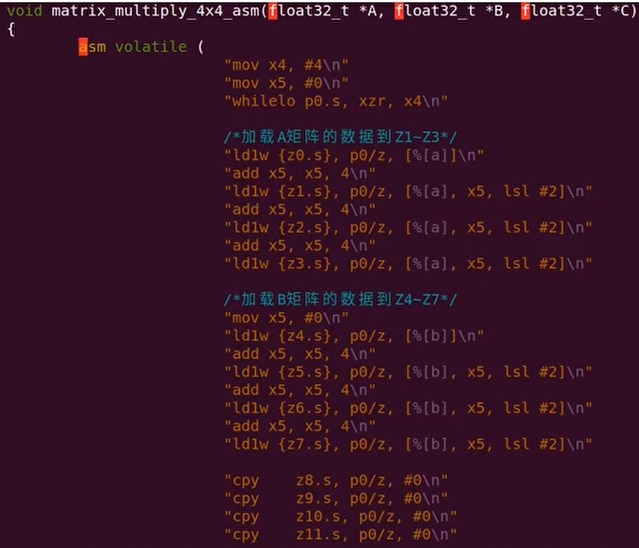
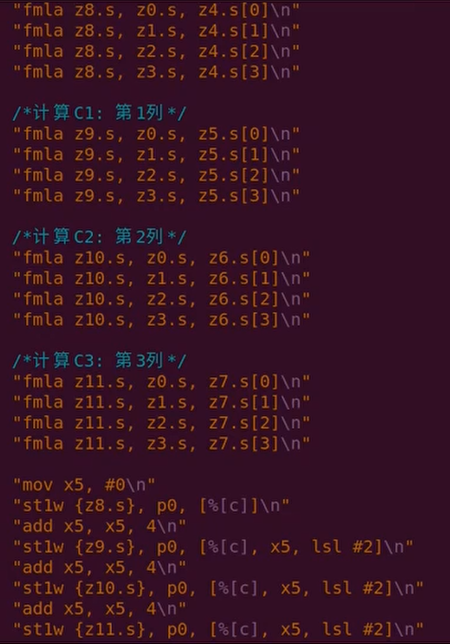
和Neon指令不同的地方


总结:上面用到的SVE指令
- whilelt/whilelo类指令
- b.Any类跳转指令
- BRKA和BRKB指令
- LASTA指令
- LD1和ST1指令
- LD3和ST3指令
- FMLA指令
- INCB类指令
- ld1ff1b类指令
- Setffr和rdffrs类指令
- Cmpeq和cmpne类指令
- Mov类指令
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 常想一二,不思八九!
评论