ARM Neon Instruction
时间轴
2025-10-30
init
参考文档:

浮点运算
浮点运算PF和NEON指令
- VFP发展历史
- VFPv1:早期版本
- VFPv2:ARMv5和ARMv6处理器中的VFP协作处理器
- VFPv3:ARMv7处理器
- VFPv4:ARMv7处理器
- NEON:支持SIMD指令和浮点运算指令
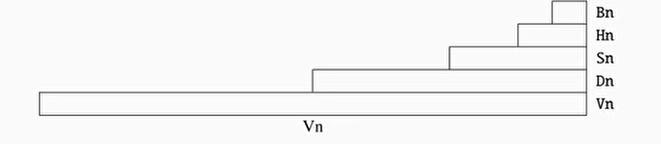
矢量(向量)寄存器与通道

- 矢量被划分为多个通道(lanes),每个通道包含一个矢量元素(vector elements)

- 通道数据类型:
- Vn:128位的数据类型
- Dn:64位的数据类型
- Sn:32位的数据类型
- Hn:16位的数据类型
- Bn:8位的数据类型
| 名称 | 位宽 | 对应的V寄存器范围 | 说明 |
|---|---|---|---|
| Vn | 128 bit | V0–V31 | NEON 128 位寄存器(完整向量) |
| Dn | 64 bit | D0–D31 | Vn 的低 64 位(Double precision) |
| Sn | 32 bit | S0–S31 | Dn 的低 32 位(Single precision) |
| Hn | 16 bit | H0–H31 | S 寄存器再下一级(Half precision) |
| Bn | 8 bit | B0–B31 | 最低的 8 位(Byte) |
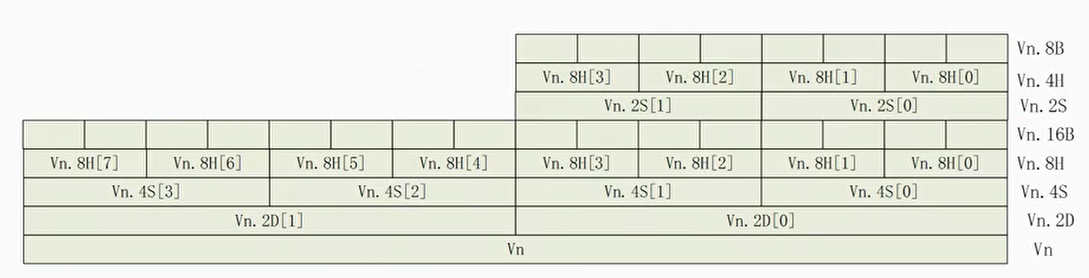
| 矢量组表示方法 | 含义 |
|---|---|
| Vn.8B | 8 bits × 8 lanes,表示 8 个数据通道,每个数据元素为 8 位数据。 |
| Vn.4H | 16 bits × 4 lanes,表示 4 个数据通道,每个数据元素为 16 位数据。 |
| Vn.2S | 32 bits × 2 lanes,表示 2 个数据通道,每个数据元素为 32 位数据。 |
| Vn.2D | 64 bits × 2 lane,表示 2 个数据通道,每个数据元素为 64 位数据。 |
| Vn.16B | 8 bits × 16 lanes,表示 16 个数据通道,每个数据元素为 8 位数据。 |
| Vn.4S | 32 bits × 4 lanes,表示 4 个数据通道,每个数据元素为 32 位数据。 |
| Vn.2D | 64 bits × 2 lane,表示 2 个数据通道,每个数据元素为 64 位数据。 |
-
索引某个通道的值
- 例如“V0.S[1]”表示V0矢量组中的第1个32位的数据,即Bit[63:32]
-
矢量寄存器列表(vector register list)

-
索引矢量寄存器列表某个通道的值


浮点数
- ARMv8支持IEEE 754标准
- ARM64处理器支持单精度和双精度浮点数。在ARM64处理器中,单精度浮点数采用32位Sn寄存器来表示,双精度浮点数采用64位Dn寄存器来表示
- 在C语言中可以使用float类型来表示单精度浮点数,double类型来表示双精度浮点数
- 浮点数由三部分组成:符号位S,阶码和尾数
- 符号位为0表示正数,为1表示负数
- 阶码有一个固定的偏移量127
- 单精度浮点数使用32位空间来表示,其中阶码8位,位数24位
- 双精度浮点数使用64位空间来表示,其中阶码11位,尾数53位
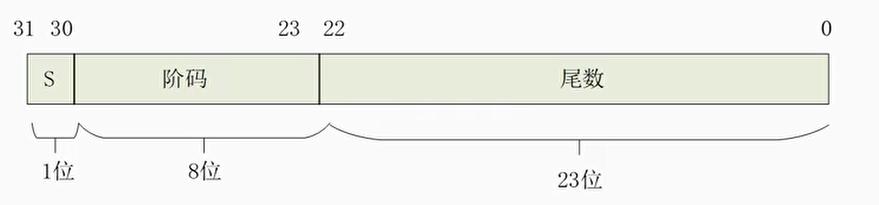
浮点数二进制表示
-
把十进制数(5.25)转换为单精度的浮点数,那么它的二进制存储格式是多少
-
步骤
- 把十进制数转换成二进制数:整数部分直接转换成二进制数,小数部分乘2取整
整数部分直接把5转成二进制,变成了二进制数:101
小数部分则需要将十进制小数部分乘2,所得积的小数点左边的数字(0或1)作为二进制表示法中的数字,直到满足精确度位置
0.25 * 2 = 0.5 小数点左边为0
0.5 * 2 = 1.0 小数点左边为1
十进制数(5.25)转成二进制数位101.01
- 规格化二进制数,改变阶码,使小数点前面只有第一位有效数字
二进制数位(101.01)规格化之后变成:1.0101*2^2,其中尾数为0101,阶码为2
- 计算阶码。对于单精度浮点数需要加上7F(127)的偏移量,对于双精度浮点数需要加上3FF(1023)的偏移量。
本例子中最终的阶码位129
- 把数字符号位,阶码和尾数合起来就得到浮点数存储形式
本例子中,符号位为0,阶码为:1000 0001,尾数为:0101,用16进制来表示为:0x40a80000
实验一:浮点数二进制表示法

fmov指令
fmov指令支持的浮点常量是有限的
FPCR寄存器
Floating-point Control Register
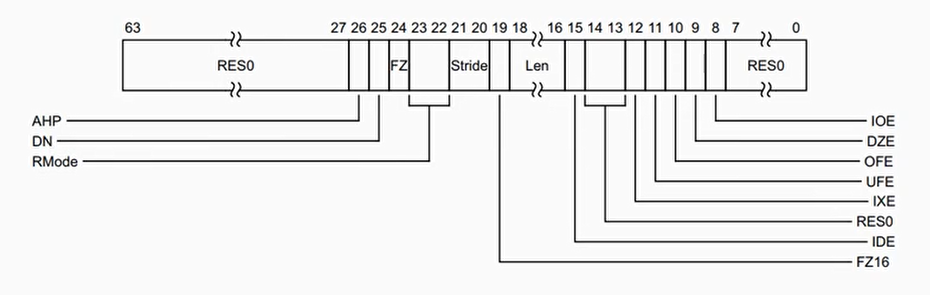
AHP(比特26)——Alternative half-precision control bit
此标志位用于控制半精度浮点采用IEEE754-2008标准还是ARM设计的一个替代实现。当此标志为0时,采用IEEE754-2008标准的半精度表示法;而为1时,则采用ARM自己设计的替换表示。
这里需要注意的是,从ARMv8.2所引入的新增FP16指令扩展会直接采用IEEE格式的半精度浮点,而直接忽略此标志。
下面简单介绍一下ARM自己设计的半精度浮点表示。在ARMv8参考指南中的A1.4.2小节(Half-precision floating-point formats)有所详细描述。它与IEEE754-2008的规范一样,1位符号位;5位指数位;10位尾数位。但在表示无穷大以及非数上两者表示有差异。

当指数部分为全1时(即0x1F):
- 对于IEEE754-2008:此半精度浮点数可能为正负无穷大(±∞,±INF),也可能是一个非数(NaN)。取决于尾数部分——如果尾数部分全为零,那么当符号位为S=0时,该浮点数为+INF;如果符号位S=1时,则为-INF。如果尾数部分不为零,则看尾数的最高位(bit 9),如果为0,则该非数是一个SNaN,否则为一个QNaN。
- 对于ARM替换实现的半精度浮点:该浮点值会被作为一个规格化数,其等价于 (-1)S * 216 * (1.fraction)。这意味着最大正的规格化数为(2 - 2-10) * 216 =131008。
DN(比特25)——Default NaN mode control bit
该标志控制着是否将一个NaN操作数进行传播到浮点操作的输出,即即便有某个操作数为NaN,计算照常完整执行。如果该标志置1,那么对于一条浮点运算操作指令,只要有某一操作数为NaN,则立即返回ARM处理器所设定好的一个默认NaN值。这个标志同样可以起到提升浮点数执行性能。
如果DN标志为1,那么对于三种浮点类型的默认NaN数值如下:
- 16位半精度浮点:0x7E00
- 32位单精度浮点:0x7FC0’0000
- 64位双精度浮点:0x7FF8’0000’0000’0000
FZ(比特24)——Flush-to-zero mode control bit
该模式的行为效果与x86的 DAZ 标志一致(而不是 FTZ )——如果该标志被置1,那么对于一条浮点计算指令,操作数中所有非规格化数全都被舍入为0。另外,此标志仅仅控制32位单精度浮点与64位双精度浮点,而不对ARMv8.2-FP16所引入的16位半精度浮点产生影响。
RMode(比特23:22)——Rounding Mode control field
关于此字段,浮点数的舍入模式相关。
FZ16(比特19)——Flush-to-zero mode control bit on half-precision data-processing instructions
该标志只有当ARM架构支持了ARMv8.2-FP16指令扩展之后才有效。该标志是对半精度浮点的flush-to-zero操作的控制,语义与上面的FZ一样。只不过此标志仅仅用于控制16位半精度浮点,而对其他浮点类型不受影响。
架构特性访问控制寄存器CPACR_EL1
有一对PF/NEON寄存器是否会陷入到EL1的控制字段:FPEN
- 当FPEN为0b01,表示在EL0里访问SVE,高级SIMD以及浮点单元寄存器时会陷入到EL1中处理,异常类型代码为0x7
- 当FPEN为0b00或者ob10,表示在EL0或者EL1里访问SVE,高级SIMD以及浮点单元寄存器时会陷入到EL1中处理,异常类型代码为0x7
- 当FPEN为0b11,表示不会陷入到EL1中
浮点数的条件操作码
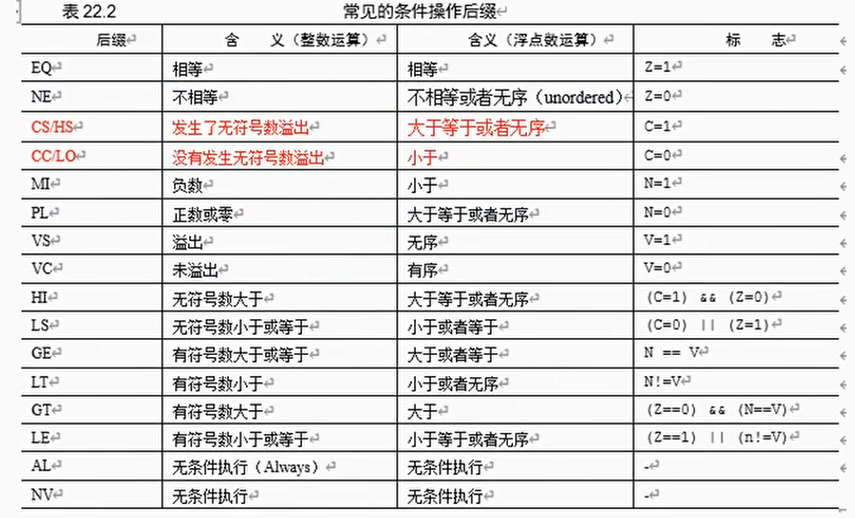
常用的浮点数指令
- 指令以F字母开头,大概几十条指令
- 见ARMv8.6手册第C.2章
- 见<<ARM Compiler arm asm User Guide,v6.6>>第18-20章

Neon指令优化
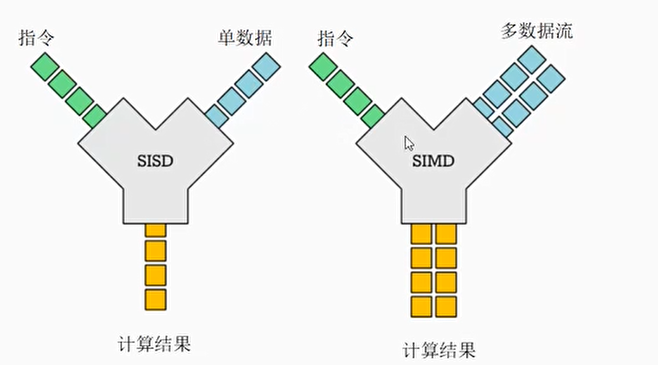
SISD和SIMD
- SISD(Single Instruction Single Data)指的是单指令单数据。每条指令在单个数据源上执行其指定的操作
1 | ADD w0, w0, w5 |
- SIMD指的是单指令多数据流,它对多个数据元素同时执行相同的操作。这些数据元素被打包成一个更大的寄存器中的独立通道(lanes)
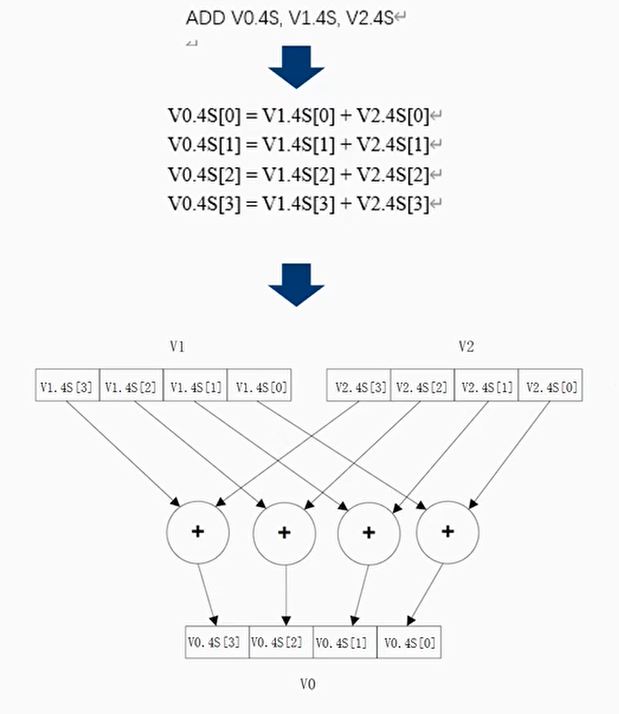
- SIMD指的是单指令多数据流,它对多个数据元素同时执行相同的操作。这些数据元素被打包成一个更大的寄存器中的独立通道(Lanes)
LD1指令
-
LD1指令是用来把多个元素加载到一个,两个,三个或四个矢量寄存器中。
-
LD1指令支持没有偏移和后变基两种模式
- 没有偏移的模式
1
2
3
4LD1 {<Vt>.<T> }, [<Xn|SP>]
LD1 {<Vt>.<T>, <Vt2>.<T>}, [<Xn|SP>]
LD1 {<Vt>.<T>, <Vt2>.<T>, <Vt3>.<T>}, [<Xn|SP>]
LD1 {<Vt>.<T>, <Vt2>.<T>, <Vt3>.<T>, <Vt4>.<T>}, [<Xn|SP>]- 后变基模式
1
2
3
4LD1 {<Vt>.<T> }, [<Xn|SP>], <imm>
LD1 {<Vt>.<T>, <Vt2>.<T>}, [<Xn|SP>], <imm>
LD1 {<Vt>.<T>, <Vt2>.<T>, <Vt3>.<T>}, [<Xn|SP>], <imm>
LD1 {<Vt>.<T>, <Vt2>.<T>, <Vt3>.<T>, <Vt4>.<T>}, [<Xn|SP>], <imm>

例子1:LD1指令加载RGB24
- 以RGB24图像格式为例,一个像素用24位(3个字节)表示R(红),G(绿),B(蓝)三种颜色。它们在内存中的存储格式是R0, G0, B0, R1, G1, B1以此类推
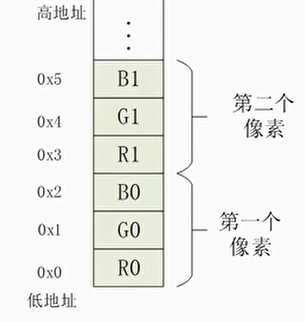
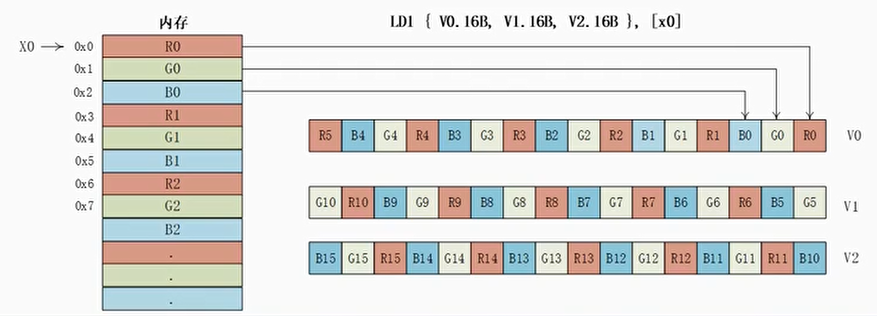
- 使用LD1指令来把RGB24格式的数据加载到矢量寄存器
1 | LD1 {V0.16B, V1.16B, V2.16B}, [x0] |
ST1指令
-
ST1指令是把一个,两个,三个或四个矢量寄存器的多个数据元素的内容存储到内存中
-
ST1指令支持没有偏移和后变基模式
- 没有偏移的模式:
1
2
3
4ST1 {<Vt>.<T>}, [<Xn|SP>]
ST1 {<Vt>.<T>,<Vt2>.<T>},[<Xn|SP>]
ST1 {<Vt>.<T>,<Vt2>.<T>,<Vt3>.<T>},[<Xn|SP>]
ST1 {<Vt>.<T>,<Vt2>.<T>,<Vt3>.<T>,<Vt4>.<T>},[<Xn|SP>]- 后变基模式:
1
2
3
4ST1 {<Vt>.<T>}, [<Xn|SP>], <imm>
ST1 {<Vt>.<T>,<Vt2>.<T>},[<Xn|SP>], <imm>
ST1 {<Vt>.<T>,<Vt2>.<T>,<Vt3>.<T>},[<Xn|SP>], <imm>
ST1 {<Vt>.<T>,<Vt2>.<T>,<Vt3>.<T>,<Vt4>.<T>},[<Xn|SP>], <imm>
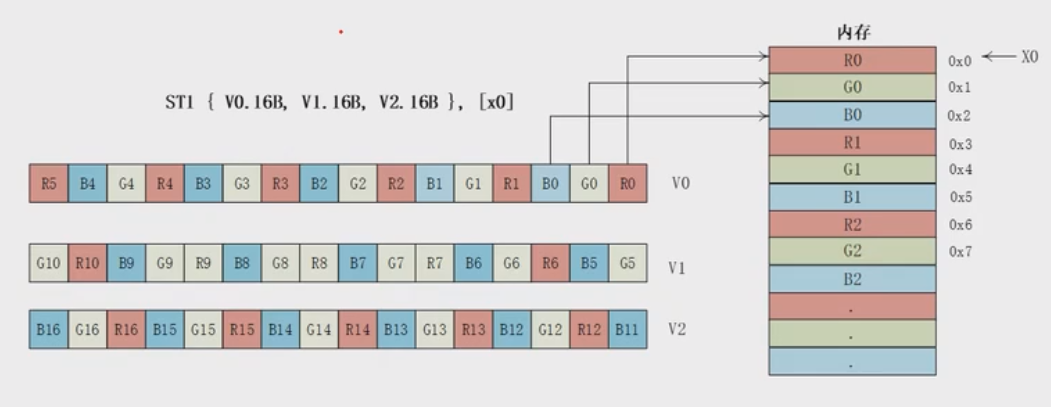
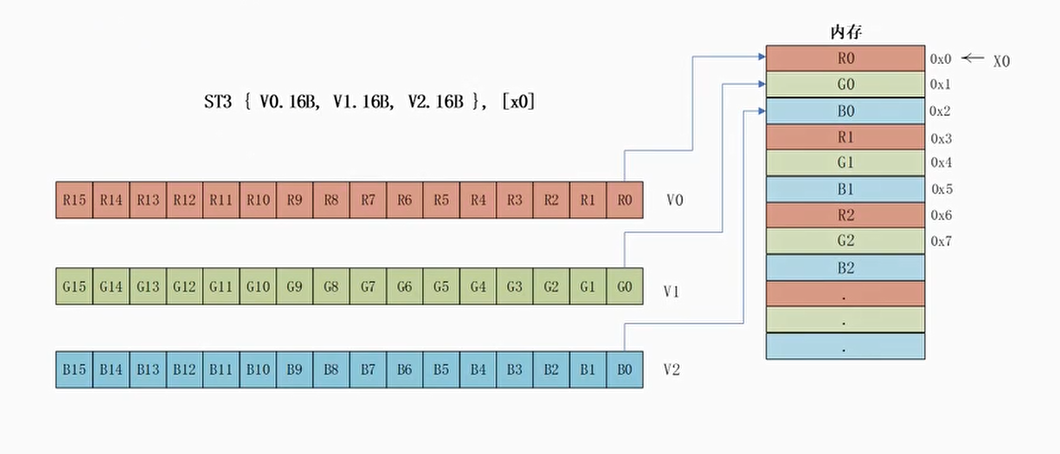
例子:ST1指令存储RGB24
- V0, V1和V3矢量寄存器中存储了RGB24格式的数据,通过ST1指令来把数据存储到内存中
1 | ST1 {V0.16B, V1.16B, V2.16B}, {x0} |
实验2:LD1和ST1指令的使用

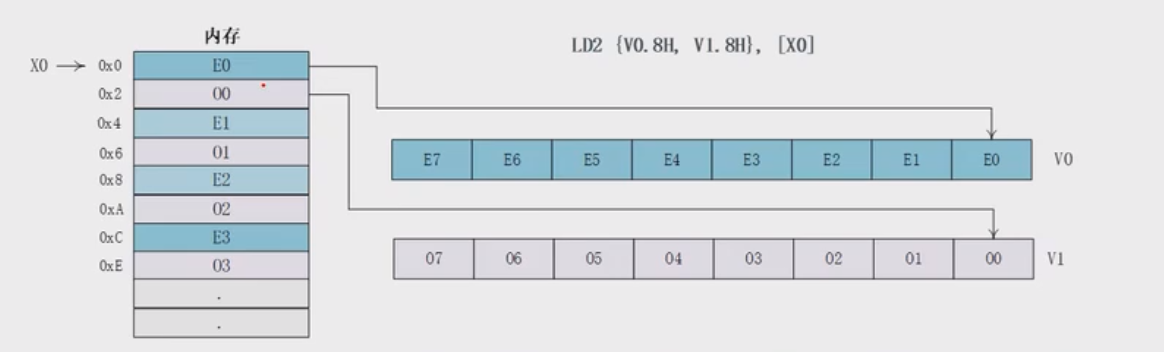
LD2/ST2:交替(interleave)方式加载和存储
-
LD2和ST2指令就是支持交替方式来加载和存储数据
-
支持没有偏移和后变基两种模式
1
2
3
4
5LD2 {<Vt>.<T>,<Vt2>.<T>},[<Xn|SP>]
ST2 {<Vt>.<T>,<Vt2>.<T>},[<Xn|SP>]
LD2 {<Vt>.<T>,<Vt2>.<T>},[<Xn|SP>], <imm>
ST2 {<Vt>.<T>,<Vt2>.<T>},[<Xn|SP>], <imm> -
例子
1 | LD2 {V0.8H, V1.8H}, [x0] |
实验3:LD2和ST2指令的使用

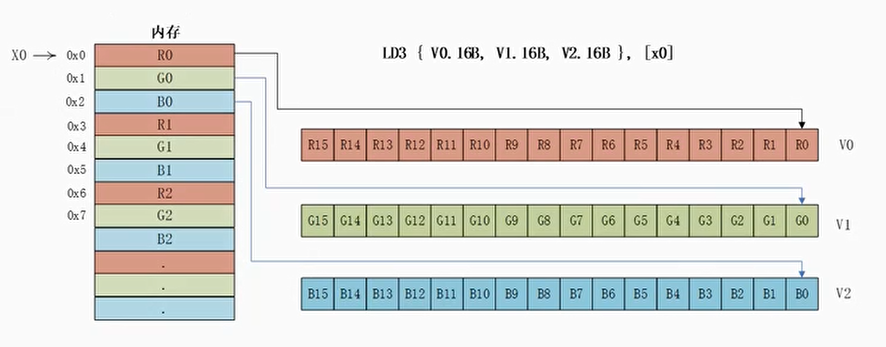
LD3/ST3:三通道交替(interleave)
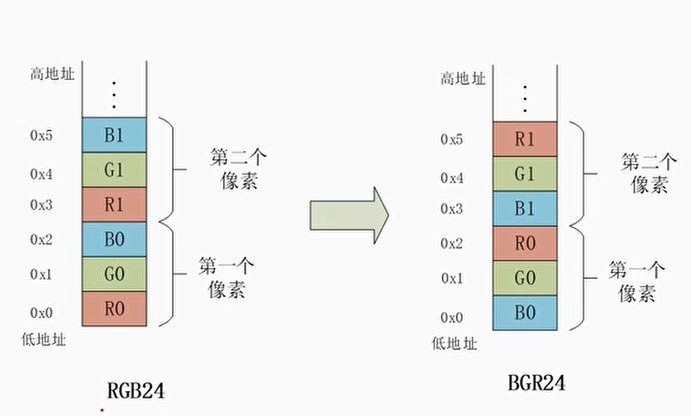
- 在RGB24转BGR24中,如果我们使用LD1指令来加载RGB24数据到矢量寄存器,那么需要在不同的通道中获得不同的颜色组件,然后移动这些组件并重新组合,这样效率会很低
- LD3和ST3指令就是支持交替方式来加载和存储数据
- 支持没有偏移和后变基两种模式
1 | LD3 {<Vt>.<T>,<Vt2>.<T>,<Vt3>.<T>,<Vt4>.<T>},[<Xn|SP>] |
例子:RGB24转BGR24
- 使用LD3指令来吧RGB24格式的数据加载到矢量寄存器中
1 | LD3 {V0.16B, V1.16B, V2.16B}, [x0] |

存储RGB24到内存
实验4:使用LD3/ST3来实现RGB24转BGR24
C语言实现
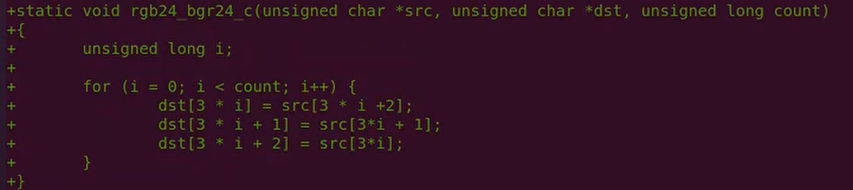
汇编实现
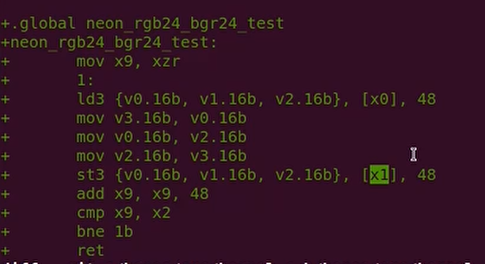
LD4/ST4:四通道交替(interleave)
- ARGB图像是RGB基础上加了Alpha(透明度)通道,为了加快ARGB格式的数据加载和存储操作,NEON指令提供了LD4和ST4指令。LD4与LD3类似,不过它可以把数据解交叉地加载到4个矢量寄存器中
- LD4和ST4指令就是支持交替地方式来加载和存储数据
- 支持没有偏移和后变基两种模式
1 | LD4 {<Vt>.<T>,<Vt2>.<T>,<Vt3>.<T>,<Vt4>.<T>},[<Xn|SP>] |
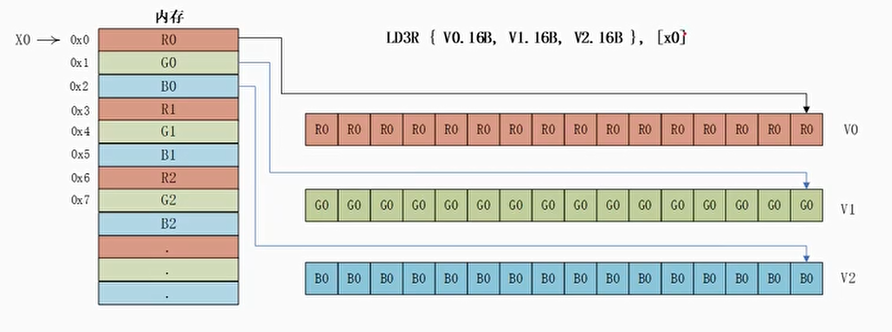
LDnR指令
- LDn指令还有一个指令变种LDnR指令,R表示替代的意思。它会从内存中加载一组数据元素,然后把数据复制到矢量寄存器地所有通道中
- 例子:
1 | LD3R {V0.16B, V1.16B, V2.16B}, [x0] |
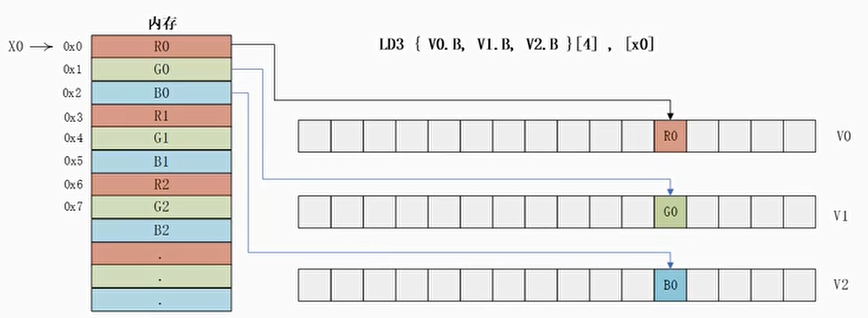
读写某个通道的值
- LDn指令可以加载数据到矢量寄存器的某个通道中,而其他通道的值不变
- 例子:
1 | LD3 {V0.B, V1.B, V2.B}[4], [x0] |
MOV指令
- 从通用寄存器中搬移数据
1 | mov w1, #0xa |
- 矢量寄存器搬移
1 | MOV V3.16B, V0.16B |
- 搬移数据元素到矢量寄存器
1 | mov h2, v1.8h[2] |
- 搬移数据元素
1 | mov v1.8h[2], v0.8h[2] |
MOVI
movi 是 ARMv8(AArch64)体系结构中 NEON(Advanced SIMD) 的一条向量立即数加载指令。它的全称是 “Move Immediate (vector)”。
movi 用于:
把一个立即数(immediate) 装载到一个 SIMD/浮点寄存器(Vn 或 Qn) 中。
它可以一次性填充寄存器中的所有元素,常用于初始化向量寄存器。
语法格式
有几种常见形式(以 A64 汇编为例):
1 | movi Vd.<T>, #imm |
其中:
Vd:目标寄存器(例如v0、v1)<T>:数据类型(如8b、16b、4h、2s、1d等)#imm:立即数LSL/MSL:逻辑左移 / 按符号扩展左移,用来改变立即数填充规则
反转指令
- REV16指令
表示矢量寄存器中的16位数据元素组成一个容器。在这个16位的容器里,颠倒8位数据元素的顺序,即颠倒B[0]和B[1]之间的顺序
- REV32指令
表示矢量寄存器中的32位数据元素组成一个容器。在这个容器里,颠倒8位数据元素或者16位数据元素的顺序
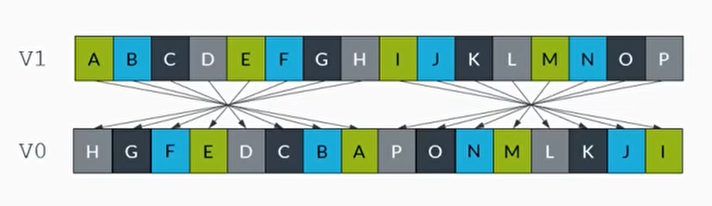
- REV64指令
表示矢量寄存器中的64位数据元素组成一个容器。在这个容器里,颠倒8位,16位或者32位数据元素的顺序
例子1:
1 | REV16 V0.16B, V1.16B |
V0是目标寄存器,V1是源寄存器
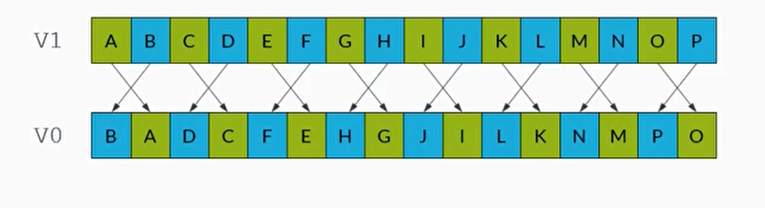
例子2:
1 | REV32 V0.16B, V1.16B |
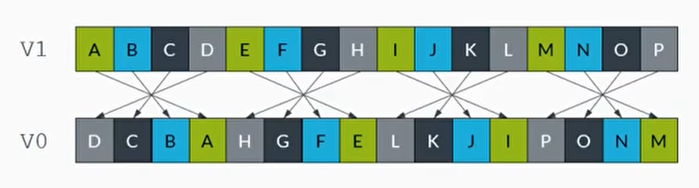
例子3:
1 | REV64 V0.16B, V1.16B |
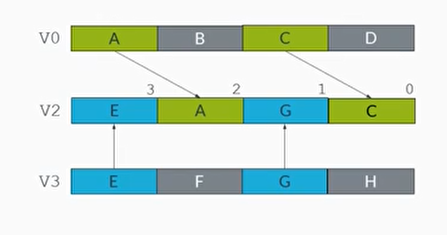
ZIP1和ZIP2指令
- ZIP1指令会分别从两个源矢量寄存器中提取一半的数据元素,然后交织地组成一个新的矢量,写入到目标矢量寄存器中
- ZIP2指令会分别从两个源矢量寄存器中提取一半地数据元素,这里提取源矢量寄存器中高位部分的数据元素,然后交织地组成一个新的矢量,写入到目标矢量寄存器中
例子:
1 | ZIP1 V0.8H, V3.8H, V4.8H |
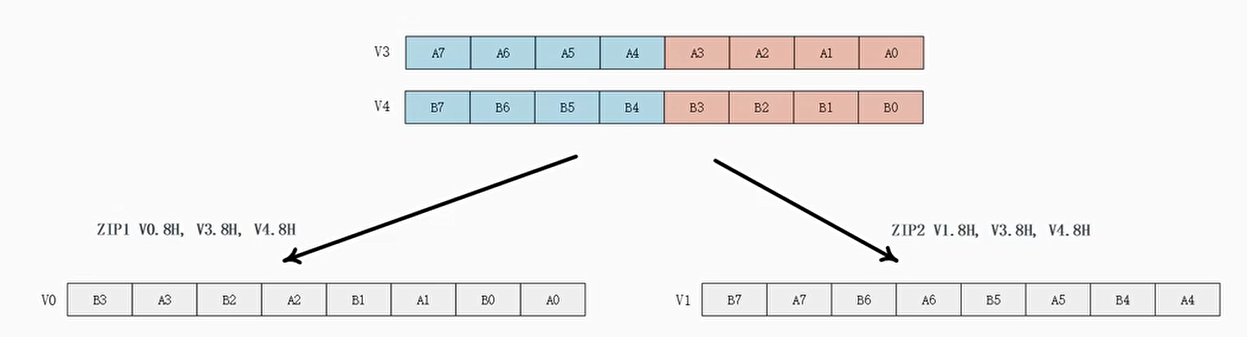
TRN1和TRN2交错交换指令
- TRN1指令从两个源矢量寄存器中交织地提取奇数的元素数据元素来组成一个新的矢量,写入到目标矢量寄存器中
- TRN2指令从两个源矢量寄存器中交织地提取偶数地数据元素来组成一个新的矢量,写入到目标矢量寄存器中
例子
1 | TRN1 V1.4S, V0.4S, V3.4S |
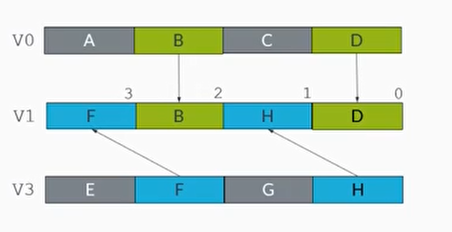
1 | TRN2 V2.4S, V0.4S, V3.4S |
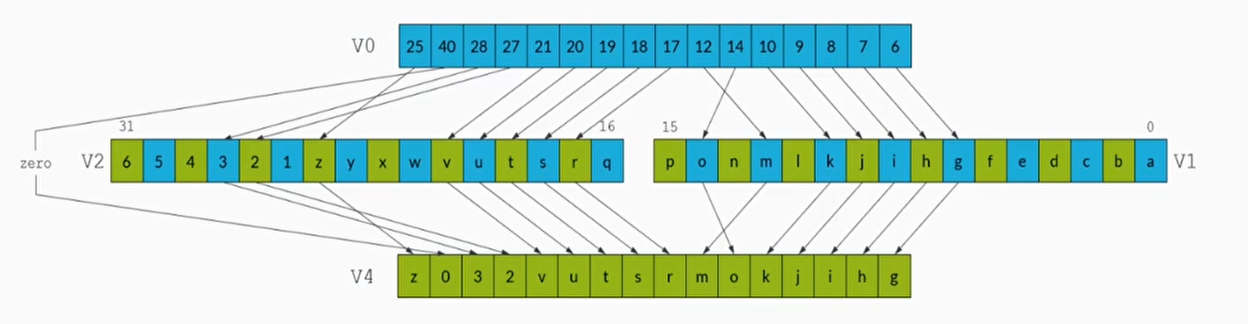
TBL查表指令
- TBL指令格式如下

例子:
1 | TBL V4.16B, {V1.16B, V2.16B}, V0.16B |
还有一个变种指令TBX,唯一区别是在索引越界时保持原值不变而不是写0
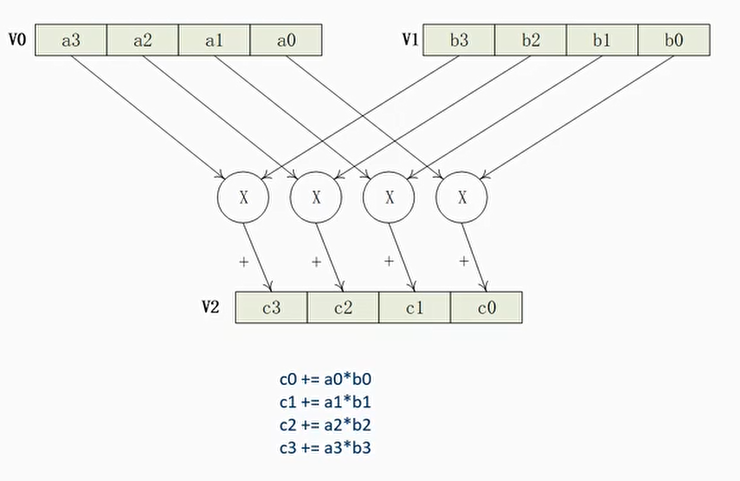
乘加指令MLA
- MLA指令乘加指令,Vd += Vn * Vm
- 例子
1 | mla v2.4s, v0.4s, v1.4s |
这种方式支持b
1 | mla v2.4s, v0.4s, v1.4s[0] |
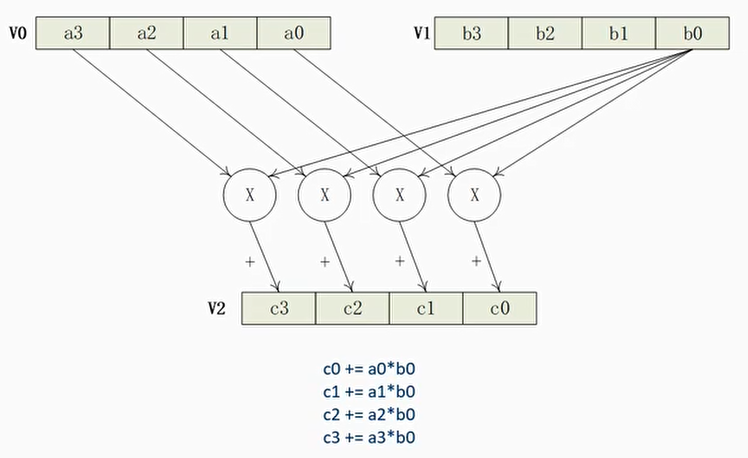
这种方式支持h和s不支持b
实验5:熟悉MLA指令

1 | neon_mla_test: |
矢量算数指令
实验6:案例分析1-RGB24转BGR24
C语言实现

内嵌汇编
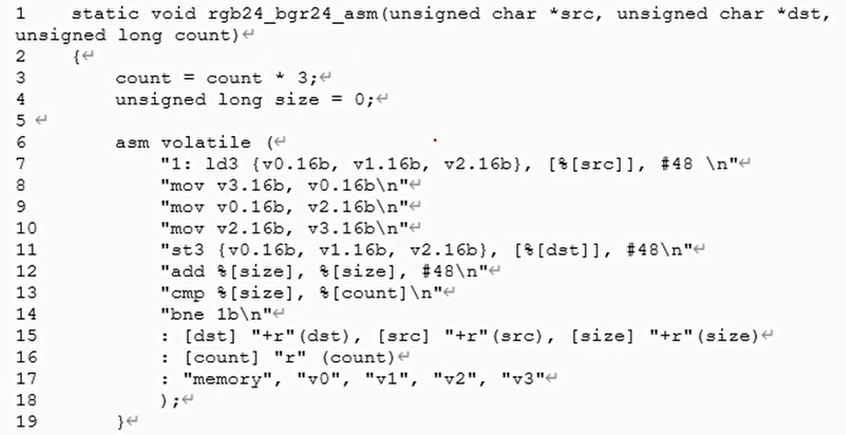
注意两点:
- 使用后变基模式,所以dst,src要放在输出部
- 破坏部中要告诉编译器使用了v0,v1,v2,v3这四个编译器,否则编译器可能会在其他地方分配了这些矢量寄存器
使用NEON内建函数
编译器封装的neon的一些指令

文档:
- <<Arm Neon Intrinsics Reference for ACLE Q3 2020>>
- <<NEON Programmer Guide>>
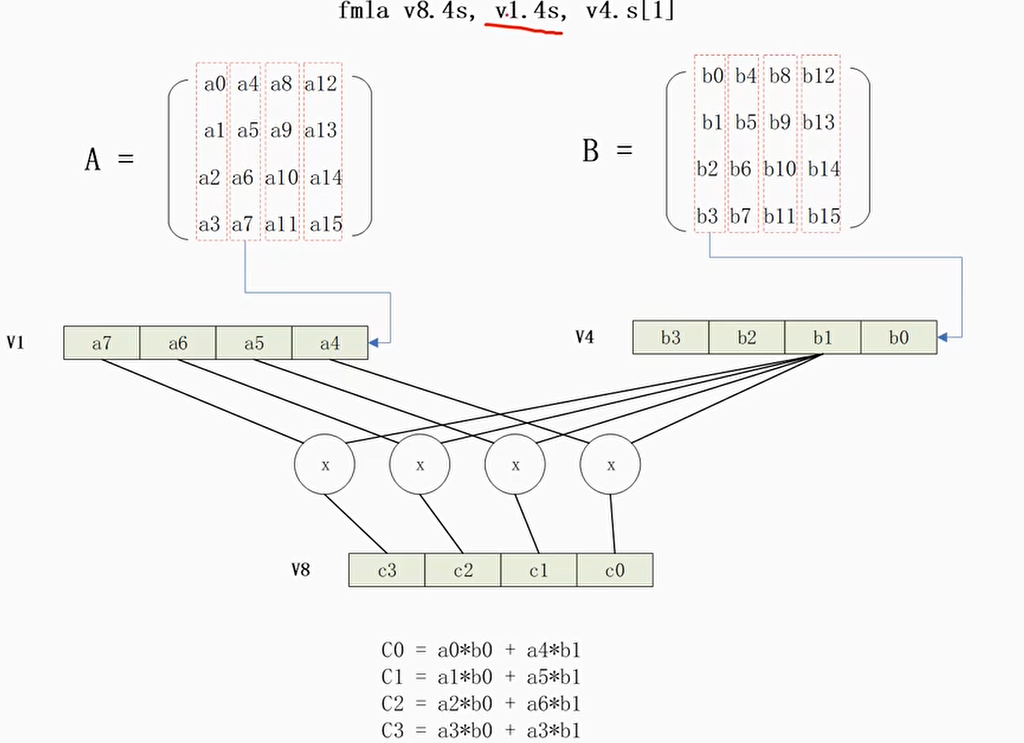
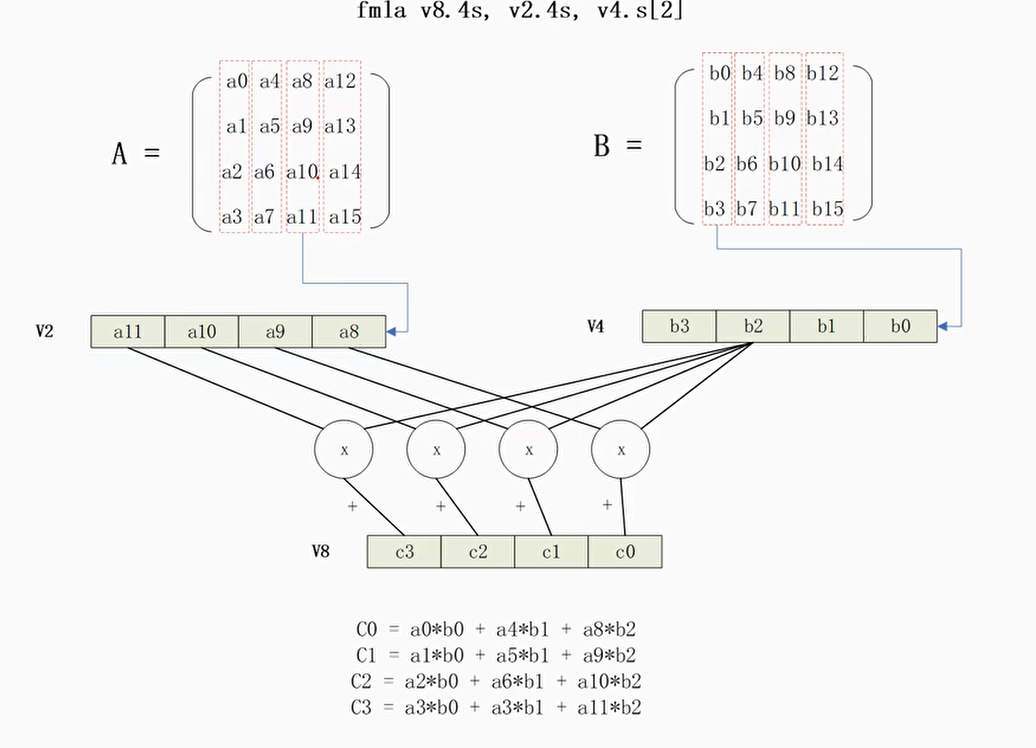
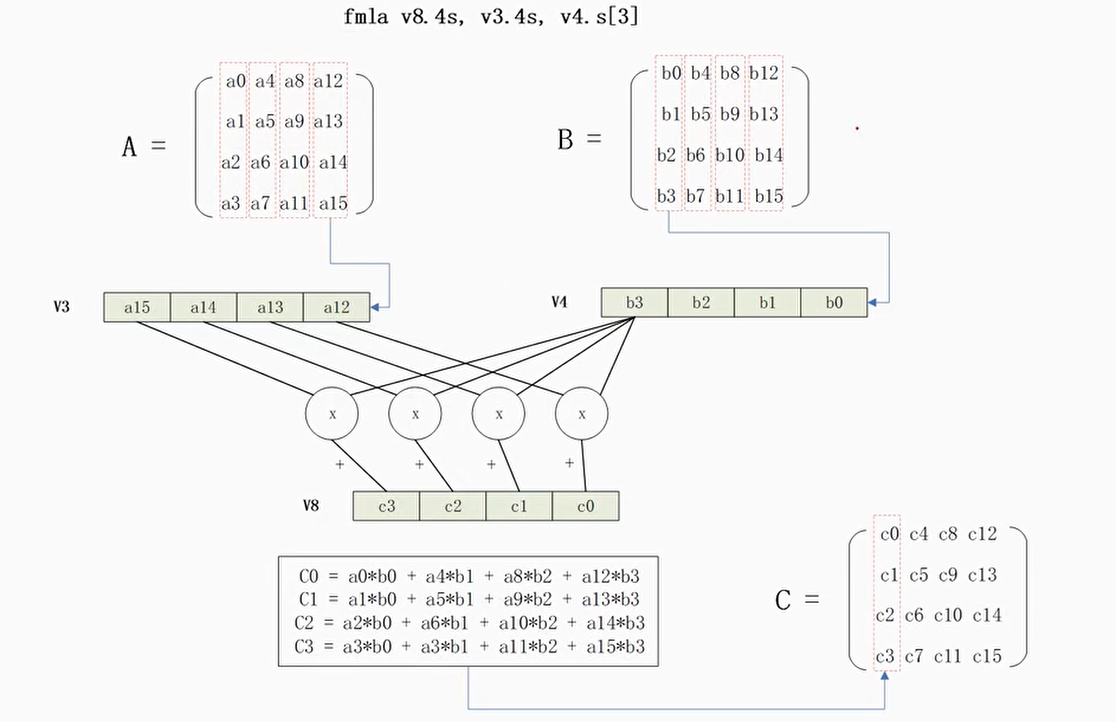
4×4矩阵乘积
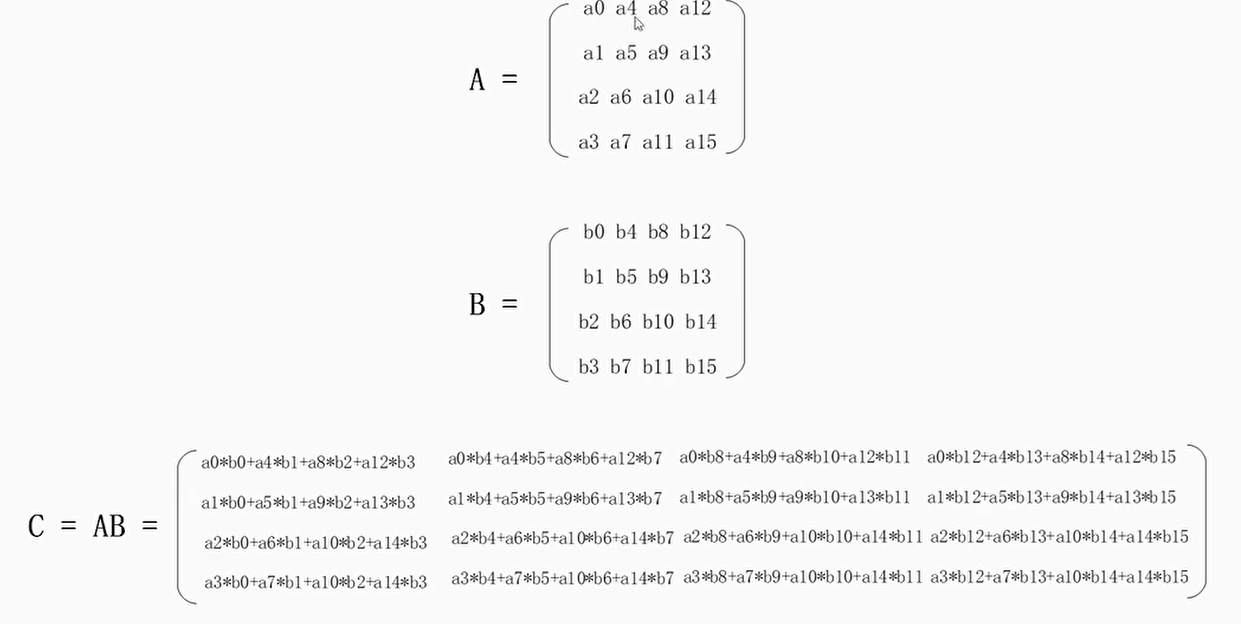
C语言实现
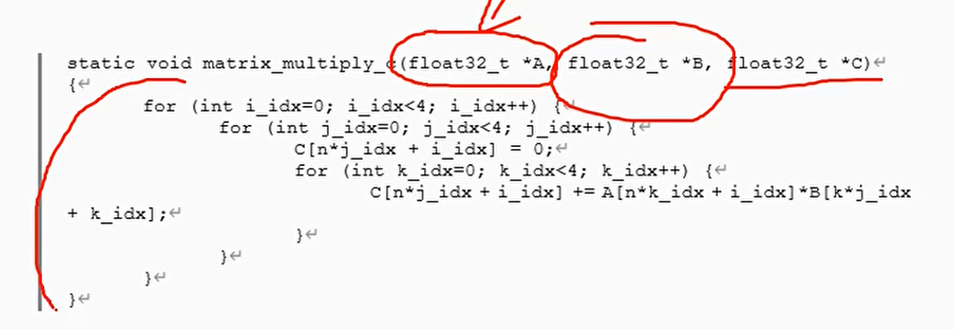
手工编写NEON汇编

使用NEON内建函数
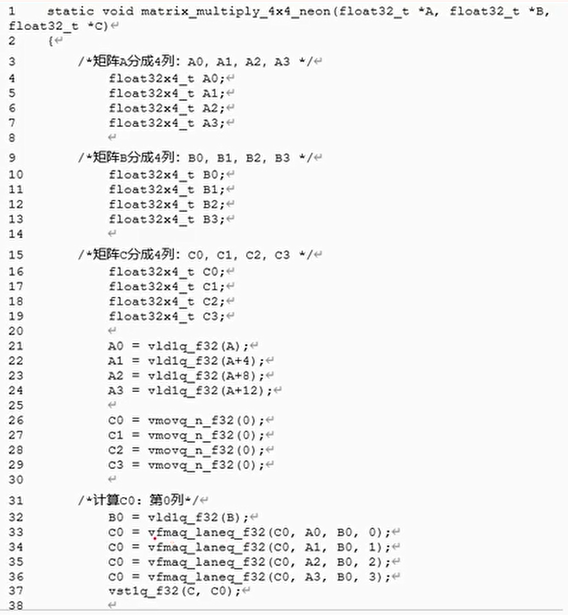

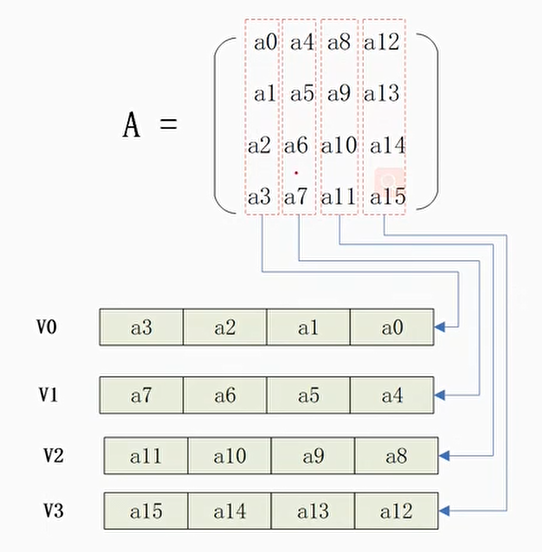
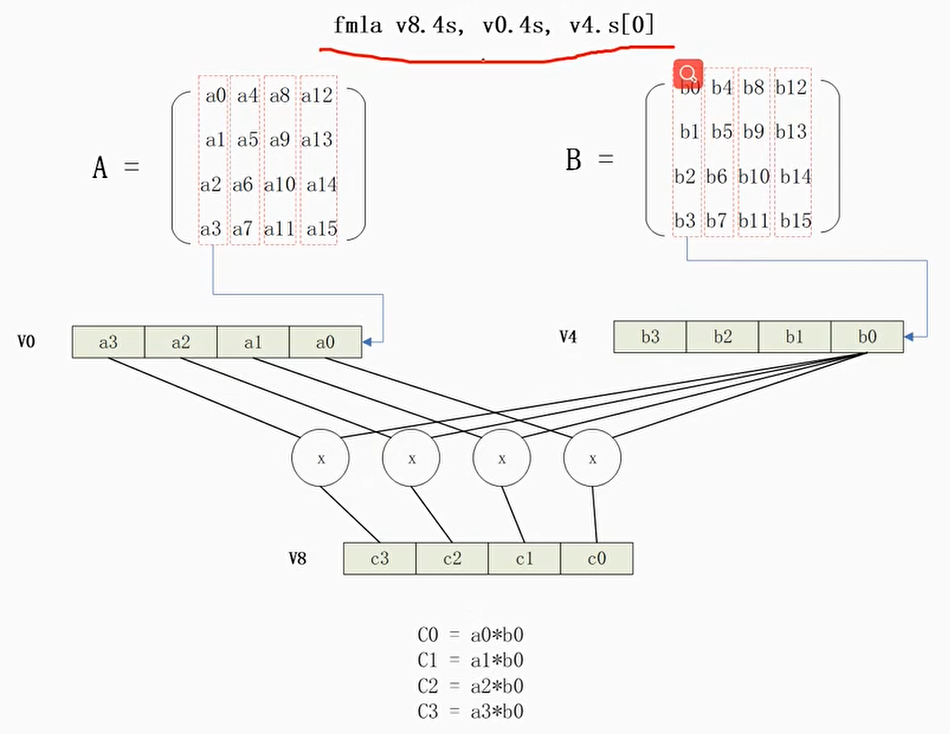
自动矢量优化
- 使用NEON指令集优化代码有如下三种做法:
- 手工编写NEON汇编代码
- 使用编译器提供的NEON内建函数(NEON Intrinsics)
- 使用编译器提供的自动矢量优化(Auto-vectorization)选项,让编译器自动生成NEON指令来进行优化
- GCC汇编器内置了自动矢量优化功能。GCC提供如下几个编译选项:
- -ftree-vectorize:执行矢量优化。这个会默认使能"-ftree-loop-vectorize"与"-ftree-slp-vectorize"
- -ftree-loop-vectorize:执行循环矢量优化。展开循环以减少迭代次数,同时在每个迭代中执行更多的操作。
- -ftree-slp-vectorize:将标量操作捆绑在一起,以利用矢量寄存器的带宽。SLP是Superword-Level-Parallelism的缩写
- GCC的"O3"优化选项会自动使能"-ftree-vectorize",即使能自动矢量优化功能
自动矢量优化约束条件
- GCC自动矢量优化功能在有些情况下可能不工作
- 在有相互依赖关系的不同循环的迭代
- 带有break子句的循环
- 具有复杂条件的循环