数据结构与算法
时间轴
2025-09-28
add 绪论
2025-10-18
add 线性表,栈,队列,数组,串
2025-10-20
add 树,图
2025-11-09
add DSU 并查集
2026-03-22
add 算法
绪论
数据的逻辑结构
数据的逻辑结构是指数据元素之间的关系,即从逻辑关系上描述数据。它与数据的存储无关,是独立于计算机的
- 线性结构
- 线性表
- 数组
- 栈
- 队列
- 线性表
- 非线性结构
- 集合
- 树形结构
- 一般树
- 二叉树
- 图状结构
- 有向图
- 无向图
数据的存储结构
存储结构是指数据结构在计算机中的表示,也称物理结构
- 顺序存储
顺序存储是指把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中;
- 链式存储
链式存储借助指示元素存储地址的指针来表示元素之间的逻辑关系;
- 索引存储
索引存储是指在存储元素信息的同时,还建立附加的索引表。索引表中的每项都称为索引项,索引项的一般形式是(关键字 key,地址 address);
- 散列存储
散列存储是根据元素的关键字直接计算出该元素的存储地址,又称哈希(Hash)存储。
算法的基本概念
- 有穷性
有穷性是指一个算法必须总在执行有穷步后结束,且每一步都在有穷时间内完成;
- 确定性
确定性是指算法中每条指令都必须有正确的含义,对于相同的输入只能得出相同的输出;
- 可行性
可行性是指算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现;
- 输入
输入是指一个算法有0或多个输入,这些输入取自于某个特定的对象的集合
- 输出
输出是指一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。
算法效率的度量
时间复杂度
加法规则:
常见的渐进时间复杂度
空间复杂度
数据结构
线性表
定义:线性表是具有相同数据类型的n(n>=0)个数据元素的有限序列。
线性表一般表示为:
线性表的顺序表示
线性表的顺序存储也称顺序表,其特点是表中元素的逻辑顺序与其物理顺序相同。线性表是一种随机存取的存储结构
- C语言描述
1 | // 静态分配 |
- C++描述
一般使用标准库vector,也可以自定义
1 | template <typename T> |
- Rust描述
Rust中一般用标准库的Vec,自己写要用许多unsafe API
基本操作时间复杂度
| 操作 | 最好情况 | 最坏情况 | 平均情况 | 备注 |
|---|---|---|---|---|
| 按位置插入 | O(1)(表尾) | O(n)(表头) | O(n) | 表尾插入均摊 O(1) |
| 按位置删除 | O(1)(表尾) | O(n)(表头) | O(n) | 表尾删除 O(1) |
| 按下标访问 | O(1) | O(1) | O(1) | 数组随机访问 |
| 查找(顺序) | O(1) | O(n) | O(n) | 如果无序只能顺序查找 |
线性表的链式表示
单链表
线性表的链式存储又称单链表。
- C语言描述
1 | typedef struct LNode{ |
这个C语言定义的效果是
| 部分 | 含义 |
|---|---|
struct Node { ... }; |
定义了一个结构体类型,标签名是 Node(即 struct Node) |
LNode |
给 struct Node 起了一个类型别名 |
*LinkList |
给 struct Node*(即该结构体指针)起了一个别名为LinkList |
- C++描述
TODO
- Rust描述
TODO
头结点
通常用头指针来标识一个单链表,头指针为NULL时表示一个空表。此外,为了操作上的方便,在单链表第一个结点之前附加一个结点,称为头节点。
-
头节点的数据域可以不设置任何信息,也可以记录表长等信息。
-
引入头节点可以带来两个优点:
- 由于第一个数据节点的位置被放在头节点的指针域中,因此在链表上的第一个位置上的操作和在表的其他位置上的操作一致,无需进行特殊处理
- 无论链表是否为空,其头指针都是指向头节点的非空指针(空表中头节点的指针域为NULL),因此空表和非空表的处理也就得到了统一。
头插法建立单链表
1 |
|
尾插法建立单链表
TODO
双链表
单链表中只有一个指向其后继的指针,使得单链表只能从头节点依次顺序地向后遍历。双链表节点中有两个指针prior和next,分别指向前驱节点和后继节点。
- C语言描述
1 | typedef struct DNode{ |
- C++描述
TODO
- Rust描述
TODO
循环链表
循环单链表
循环单链表和单链表的区别在于,表中的最后一个节点的指针不是NULL,而改为指向头节点,从而整个链表形成一个环。
-
C语言描述
-
C++描述
-
Rust描述
循环双链表
循环双链表相比于循环单链表,其头节点的prior指针要指向尾节点
-
C语言描述
-
C++描述
-
Rust描述
静态链表
静态链表借助数组来描述线性表的链式存储结构,节点也有数据域data和指针域next,与前面的链表中的指针不同的是,这里的指针是节点的相对地址(数组下标),又称游标。和顺序表相同,静态链表也要预先分配一块连续的内存地址空间。
例如:
| 下标 | data | next |
|---|---|---|
| 0 | 4 | |
| 1 | 头结点 | 2 |
| 2 | 10 | 3 |
| 3 | 20 | 5 |
| 4 | 6 | |
| 5 | 30 | -1 |
| 6 | -1 |
1 | 主链表部分: |
C语言描述
1 |
|
C++描述
Rust描述
栈
栈(Stack)是只允许在一端进行插入或删除操作的线性表。
- 栈顶(Top) 线性表允许进行插入删除的那一端
- 栈底(Bottom) 固定的。不允许进行插入和删除的另外一端
栈的特性可以明显的概括为后进先出(Last In First Out,LIFO)
栈的数学性质:
n 个不同元素进栈,其可能的出栈序列个数为第 n 个 Catalan 数(卡特兰数)
公式为:
栈的顺序存储结构
- C语言描述
1 |
|
- C++描述
TODO
- Rust描述
TODO
共享栈
利用栈底位置相对不变的特性,可以让两个顺序栈共享一个一维数组空间,将两个栈的栈底分别设置在共享空间的两端,两个栈顶向共享空间的中间延伸。
1 | 下标: 0 1 2 3 4 5 6 7 8 9 |
共享栈是为了更有效地利用地址空间。当且仅当两个栈相邻时发生栈满上溢。
栈的链式存储结构
采用链式存储的栈称为链栈,链栈的优点
- 便于多个栈共享存储空间和提高效率
- 不存在栈满上溢的情况
链栈通常采用单链表实现,并规定所有操作都是在表头进行。
- C语言描述
这里规定链栈没有头节点
1 | typedef struct LinkNode{ |
- C++描述
TODO
- Rust描述
TODO
经典应用
括号匹配
表达式求值
递归转为栈实现
队列
**队列(Queue)**也是一种操作受限的线性表,只允许在表的一端进行插入,而在表的一端进行删除。
-
队头(Front) 允许删除的一端,也称队首
-
队尾(Rear) 允许插入的一端
-
入队(EnQueue) 向队尾插入元素
-
出队(DeQueue) 队头删除元素
队列的特性可简单概括为先进先出(First In First Out,FIFO)
队列的顺序存储结构
- C语言描述
1 |
|
- C++描述
TODO
- Rust描述
判断队空
Q.rear == Q.front==0
判断队满
由于:
- 进队操作:队不满时,先送值到队尾元素,再将队尾指针+1
- 出队操作:队不为空时,先取队头元素值,再将队头指针+1
因此不能用“Q.rear==MaxSize ”作为队列满的条件,整个问题使用循环队列来解决
循环队列
将顺序队列臆造为一个环状的空间,即把存储队列元素的表从逻辑上视为一个环,称为循环队列
-
当队首指针 Q.front == MaxSize -1后,再前进一个位置到0
-
初始化:Q.front = Q.rear = 0
-
队首指针进1:Q.front = (Q.front + 1) % MaxSize
-
队尾指针进1:Q.rear = (Q.rear + 1) % MaxSize
-
判断队满三种方式
-
牺牲一个单元来区分队空队满,入队时少用一个队列单元,这是较为普遍的做法,约定以"队头指针在队尾指针的下一位置作为队满的标志"
- 队满条件 : (Q.rear + 1) % MaxSize == Q.front
- 队空条件: (Q.front == Q.rear)
- 队列中元素的个数: (Q.rear - Q.front + MaxSize) % MaxSize
-
新增一个表示元素个数的数据成员size,这样队空队满的情况下都有Q.rear == Q.front
- 队满条件 : Q.size == MaxSize
- 队空条件: Q.size = 0
- 队列中元素的个数: size
-
新增tag数据成员。tag为0时表示最近执行了一次删除;tag为1时表示最近执行了一次插入
- 队满条件 : 当tag等于0时,若因删除导致Q.front == Q.rear则队空;
- 队空条件: 当tag等于1时,因插入导致Q.front == Q.rear则为队满;
- 队列中元素个数
-
队列的链式存储结构
通常将链式队列设计成一个带头结点的单链表。
- C语言描述
1 | typedef struct LinkNode{ |
- C++描述
TODO
- Rust描述
TODO
双端队列
双端队列是指允许两端都可以进行入队和出队操作的队列。将队列的两端称为前端和后端。
输入受限的双端队列
允许在一端进行插入和删除,但在另一端只允许插入。
输出受限的双端队列
允许在一端进行插入和删除,但在另一端只允许删除。
优先队列(堆)
堆就是利用完全二叉树的结构来维护的一维数组。
堆可以分为大顶堆和小顶堆。
-
大顶堆:每个结点的值都大于或等于其左右孩子结点的值。
-
小顶堆:每个结点的值都小于或等于其左右孩子结点的值。
以大顶堆为例:
大顶堆的构建过程就是从最后一个非叶子结点开始从下往上调整。
用数组表示待排序序列,则最后一个非叶子结点的位置是:数组长度/2-1
比较当前结点的值和左子树的值,如果当前节点小于左子树的值,就交换当前节点和左子树;交换完后要检查左子树是否满足大顶堆的性质,不满足则重新调整子树结构;
再比较当前结点的值和右子树的值,如果当前节点小于右子树的值,就交换当前节点和右子树;交换完后要检查右子树是否满足大顶堆的性质,不满足则重新调整子树结构;
无需交换调整的时候,则大顶堆构建完成。
1 |
|
经典应用
层次遍历
数组与特殊矩阵
数组
大多数语言都提供了数组数据类型。
特殊矩阵的压缩
对称矩阵(Symmetric Matrix)
- 性质:矩阵 满足 。
- 压缩方法:只存储矩阵的上三角或下三角部分,例如存储上三角(包括对角线)的元素。
如果矩阵是 ,元素按行存储上三角:
- 下标映射公式(存储到一维数组
B[k]):
其中 从 1 开始计数。
- 存储空间: 个元素。
三角矩阵(Triangular Matrix)
- 性质:
- 上三角矩阵:所有元素 当
- 下三角矩阵:所有元素 当
- 压缩方法:只存储非零的三角部分。
上三角矩阵按行存储公式:
下三角矩阵按行存储公式:
- 存储空间: 个元素。
三对角矩阵 / 带状矩阵(Tridiagonal / Banded Matrix)
- 性质:矩阵只有主对角线、上对角线和下对角线有非零元素,其余为 0。
- 压缩方法:存三个一维数组:
A[1..n]存主对角线B[1..n-1]存上对角线C[1..n-1]存下对角线
- 访问公式:
- 存储空间: 个元素,比普通 大幅节省。
稀疏矩阵
矩阵中非零元素的个数t,相对矩阵元素的个数s来说非常少,即的矩阵称为稀疏矩阵。
若采用常规方法存储稀疏矩阵相当浪费空间,因此仅存储非零元素。但通常非零元素的分布非常没有规律,所以还要存储非零元素的行和列。
因此,将非零元素及对应的行和列构成一个三元组
然后按某种规律存储这个三元组。稀疏矩阵压缩存储后失去了随机存取的特性。
稀疏矩阵的三元组既可以采用数组存储,也可以采用十字链表法存储。
三元组顺序表(数组存储)
- 将稀疏矩阵中的非零元素按照行优先或列优先顺序存储为三元组
(行标, 列标, 值)。 - 常用顺序:
- 行优先:按行从上到下、每行从左到右存储。
- 列优先:按列从左到右、每列从上到下存储。
- 适用于矩阵非零元素不频繁修改的情况。
十字链表存储(Cross Linked List / Orthogonal List)
- 对于动态修改的稀疏矩阵较适用。
- 每个非零元素节点包含:
- 值
- 行标
- 列标
- 行指针(指向同一行的下一个非零元素)
- 列指针(指向同一列的下一个非零元素)
- 可以实现行和列的快速遍历,适合矩阵乘法和转置等操作。
并查集
Disjoint Set Union,DSU / Union-Find
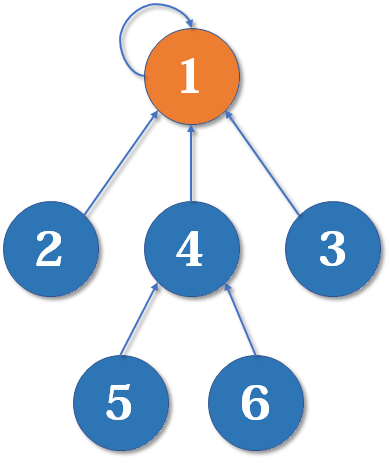
并查集是一种 动态维护若干不相交集合 的数据结构,支持两种主要操作:
| 操作 | 功能说明 |
|---|---|
find(x) |
查找元素 x 所在集合的代表(根节点) |
union(x, y) / join(x, y) |
合并两个元素所属的集合 |
(可选)connected(x, y) |
判断两个元素是否属于同一集合(即 find(x) == find(y)) |
数据结构定义
1 |
|
技巧:
| 技术 | 说明 | 效果 |
|---|---|---|
| 路径压缩 (Path Compression) | 在 find() 时将查找路径上所有节点的父节点都指向根节点 |
显著降低树高,几乎摊还 O(1) |
| 按秩合并 (Union by Rank/Size) | 在 union() 时让“矮树”挂到“高树”下 |
保持树的平衡,进一步优化查找效率 |
时间复杂度
| 操作 | 均摊时间复杂度 |
|---|---|
find() |
近似 O(1) |
union() |
近似 O(1) |
connected() |
近似 O(1) |
严格来说,是 O(α(n)),但 α(n) ≤ 5 对任何实际规模的 n。
串
串的模式匹配
子串的定位操作通常称为串的模式匹配,它求的是子串(通常称为模式串)在主串中的位置。
朴素模式匹配算法
模式串 p 与主串 s
1 | S: a b a b c a b c a c b a b |
代码:
1 |
|
最坏情况:,其中 是主串长度, 是模式串长度。
- 例如主串
"aaaaaaab"和模式串"aaaab",每次匹配失败都需要回溯多个字符。
平均情况:通常小于最坏情况,但仍然可能接近 。
KMP算法
推荐讲解非常好的文章:

朴素模式匹配算法中,每次匹配失败都是将模式串(要匹配的子串)后移一位从头开始比较。
几个概念:
- 前缀:包含首字母,不包含尾字母的所有子串
- 后缀:包含尾字母,不包含首字母的所有子串
- PM(Partial Match) 部分匹配值,即下面的表格
下面以"ABCDABD"作为要匹配的子串来举例:
| 子串 | 前缀集合(不含完整串) | 后缀集合(不含完整串) | 最长相等前后缀长度 |
|---|---|---|---|
| A | (空) | (空) | 0 |
| AB | A | B | 0 |
| ABC | A, AB | C, BC | 0 |
| ABCD | A, AB, ABC | D, CD, BCD | 0 |
| ABCDA | A, AB, ABC, ABCD | A, DA, CDA, BCDA | 1(A) |
| ABCDAB | A, AB, ABC, ABCD, ABCDA | B, AB, DAB, CDAB, BCDAB | 2 (AB) |
| ABCDABD | A, AB, ABC, ABCD, ABCDA, ABCDAB | D, BD, ABD, DABD, CDABD, BCDABD | 0 |
则PM表为
| 编号 | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|---|
| String[i] | A | B | C | D | A | B | D |
| PM | 0 | 0 | 0 | 0 | 1 | 2 | 0 |
- 如果给定文本串“BBC ABCDAB ABCDABCDABDE”,和模式串“ABCDABD”,现在要拿模式串去跟文本串匹配,如下图所示:

-
- 因为模式串中的字符A跟文本串中的字符B、B、C、空格一开始就不匹配,所以不必考虑结论,直接将模式串不断的右移一位即可,直到模式串中的字符A跟文本串的第5个字符A匹配成功:

-
- 继续往后匹配,当模式串最后一个字符D跟文本串匹配时失配,显而易见,模式串需要向右移动。但向右移动多少位呢?因为此时已经匹配的字符数为6个(ABCDAB),然后根据PM表可得失配字符D的上一位字符B对应的长度值为2,所以根据之前的结论,可知需要向右移动6 - 2 = 4 位,从PM[i] = 2 即下标为2的地方重新开始匹配

我们可以定义一个next数组:当模式串的第j个(从0开始)匹配失败时,从模式串的第next[j]个继续向后匹配。
KMP 里的 next 数组有两种写法:
PM 表 = 前缀函数 π(i)(也叫lps 数组,Longest Prefix Suffix)。
-
有些教材里 next 就等于 PM(lps)
-
有些教材里 next 是 PM 的变形
-
next[0] = -1 (表示完全重新开始匹配)
-
next[i] = PM[i-1]
-
1 |
|
树与二叉树
术语
graph TD
A[A] --> B[B]
A --> C[C]
B --> D[D]
B --> E[E]
C --> F[F]
C --> G[G]
E --> H[H]
E --> I[I]
style A fill:#f9f,stroke:#333,stroke-width:2px
style D fill:#9f9,stroke:#333
style F fill:#9f9,stroke:#333
style G fill:#9f9,stroke:#333
style H fill:#9f9,stroke:#333
style I fill:#9f9,stroke:#333
-
结点的分类
-
根节点 (Root)
-
树的顶端节点。
-
示例:
A是根节点。
-
-
双亲 (Parent)
-
节点的直接上一层节点。
-
示例:
B的父节点是A。
-
-
兄弟 (Sibling)
-
具有同一个父节点的节点互为兄弟。
-
示例:
D和E是兄弟,F和G是兄弟。
-
-
子节点
- 子节点:父节点直接连接的节点。
- 示例:
D、E是B的子节点。
-
子孙
- 节点的所有后代,包括子节点。
- 示例:
H、I是B的子孙。
-
分支节点 (Internal Node)
- 有子节点的节点。
- 示例:
A、B、C、E都是分支节点。
-
叶节点 (Leaf Node)
- 没有子节点的节点。
- 示例:
D、F、G、H、I是叶节点。
-
-
结点的属性
-
结点的深度 (Depth)
-
从根节点到该节点的路径长度(边数)。(自顶向下)
-
示例:
A深度 0,B深度 1,D深度 2。
-
-
结点的高度 (Height)
-
从该节点到最深叶节点的最长路径长度。(自底向上)
-
示例:
B高度 2(最长路径 B→E→H 或 B→E→I)。 -
结点的层次 (Level)
-
层次 = 深度 + 1
-
示例:根节点 A 层次 1,B 层次 2。
-
-
度 (Degree)
- 一个节点拥有子节点的个数。
- 示例:
B的度是 2(D、E)。
-
-
-
树的分类
-
度为m的树
- 任意结点度数不大于m
- 至少有一个结点的度数为m
- 一定为非空树,因此至少有m+1个结点
-
m叉树
- 任意节点度数不大于m
- 可以是空树
-
有序树 / 无序树 (Ordered / Unordered Tree)
-
有序树:树中结点的各个子树从左到右是有次序的,不能互换,即子节点有固定顺序。
-
无序树:子节点顺序不重要。
-
-
森林 (Forest)
-
多棵互不相连的树组成的集合。
-
如果去掉根节点 A,就形成两棵树 B 树和 C 树,组成森林。
-
-
-
其他概念
- 路径 (Path)
- 从一个节点到另一个节点经过的节点序列。
- 示例:A→B→E→H 是一条路径。
- 路径长度 (Path Length)
- 路径上边的数量。
- 示例:A→B→E→H,路径长度 = 3。
- 路径 (Path)
树的性质
-
树中的结点数等于所有结点度数之和+1
- 证明很简单,除了根节点,其他所有节点头上都有一条边
-
度为 的树第 层上至多有 个结点()
-
高度为 的 叉树至多有 个结点
-
具有 个结点的 叉树的最小高度是
- 证明:高度最小的情况下,尽量让每个节点都有 个孩子那么:
二叉树
二叉树是有序树
术语
-
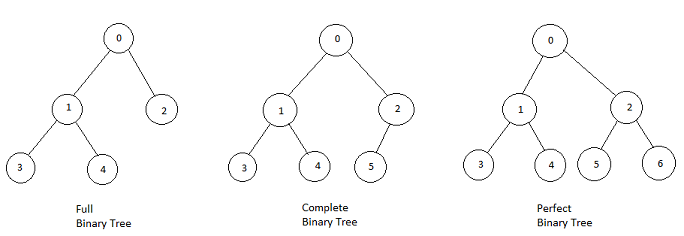
满二叉树
graph TD style A fill:#f9f,stroke:#333,stroke-width:2px style B fill:#9cf,stroke:#333,stroke-width:1px style C fill:#9cf,stroke:#333,stroke-width:1px style D fill:#9cf,stroke:#333,stroke-width:1px style E fill:#9cf,stroke:#333,stroke-width:1px style F fill:#9cf,stroke:#333,stroke-width:1px style G fill:#9cf,stroke:#333,stroke-width:1px style H fill:#9f9,stroke:#333,stroke-width:1px style I fill:#9f9,stroke:#333,stroke-width:1px style J fill:#9f9,stroke:#333,stroke-width:1px style K fill:#9f9,stroke:#333,stroke-width:1px style L fill:#9f9,stroke:#333,stroke-width:1px style M fill:#9f9,stroke:#333,stroke-width:1px style N fill:#9f9,stroke:#333,stroke-width:1px style O fill:#9f9,stroke:#333,stroke-width:1px A((1)) --> B((2)) A --> C((3)) B --> D((4)) B --> E((5)) C --> F((6)) C --> G((7)) D --> H((8)) D --> I((9)) E --> J((10)) E --> K((11)) F --> L((12)) F --> M((13)) G --> N((14)) G --> O((15))-
高度为 ,且含有个结点的二叉树称为满二叉树
-
满二叉树除了叶子节点外每个结点的度数为2
-
可以对满二叉树进行按层序编号, 对于节点编号为 的结点:
-
左孩子编号:
-
右孩子编号:
-
父节点编号:
-
-
-
完全二叉树
graph TD style A fill:#f9f,stroke:#333,stroke-width:2px style B fill:#9cf,stroke:#333,stroke-width:1px style C fill:#9cf,stroke:#333,stroke-width:1px style D fill:#9cf,stroke:#333,stroke-width:1px style E fill:#9cf,stroke:#333,stroke-width:1px style F fill:#9cf,stroke:#333,stroke-width:1px style G fill:#9cf,stroke:#333,stroke-width:1px style H fill:#9f9,stroke:#333,stroke-width:1px style I fill:#9f9,stroke:#333,stroke-width:1px style J fill:#9f9,stroke:#333,stroke-width:1px style K fill:#9f9,stroke:#333,stroke-width:1px style L fill:#9f9,stroke:#333,stroke-width:1px A((1)) --> B((2)) A --> C((3)) B --> D((4)) B --> E((5)) C --> F((6)) C --> G((7)) D --> H((8)) D --> I((9)) E --> J((10)) E --> K((11)) F --> L((12))- 高度为,有个结点的二叉树,当且仅当其每个结点都与高度为的满二叉树中编号为1~n的结点一一对应时,称为完全二叉树
- 若 ,则结点 为分支结点
- 叶节点只可能在层次最大的两层出现,对于最大层次的叶节点,都一次排列在该层最左边的位置上。
- 若有度为1的结点,则只可能有一个,且该结点只有左孩子而无右孩子。
- 按层序编号后,一旦出现某个结点(序号为 )为叶子结点或只有左孩子,则编号大于 的结点均为叶结点
- 若 为奇数,则每个分支节点都右左孩子和右孩子;若 为偶数,则编号最大的分支结点(编号为 )只有左孩子,没有右孩子 其余结点左右孩子都有
- 一棵完全二叉树的两棵子树(根节点的左子树和右子树),至少有一棵是满二叉树
-
二叉排序树
- 左子树上所有结点的关键字均小于根节点的关键字,右子树上所有结点的关键字均大于根结点的关键字;左子树和右子树又都是一棵二叉排序树。
-
平衡二叉树
- 树上任意一个结点的左子树和右子树的深度之差不超过1
性质
-
非空二叉树上的叶节点数等于度为2的结点数加1,即
-
非空二叉树上第 层上至多有 个结点()
-
高度为 的二叉树之多有 个结点()
-
具有个结点的完全二叉树的高度为 或
-
对完全二叉树结点进行编号,有如下关系
| 项目 | 1-based 编号(根=1) | 0-based 编号(根=0) |
|---|---|---|
| 左孩子 | ||
| 右孩子 | ||
| 父节点 | ||
| 至少有左孩子的条件 | ||
| 右孩子存在条件 | ||
| 叶节点条件 | 或 | |
| 只有左孩子条件 | 且 | |
| 深度(root 层=1) | ||
| 深度(root 层=0) |
存储结构
- 顺序存储结构
数组存储,按照完全二叉树的方式来存储,用0或-1表示空结点。
- 链式存储
容易验证,在含有个结点的二叉链表中,含有 个空指针域
n个结点,2n个指针域,n-1个结点头上有一个指针指向自己,故有n+1个空指针域
二叉树的遍历
先序遍历
先访问根节点,再遍历左子树,再遍历右子树
递归写法
1 | void PreOrder(BiTree T){ |
非递归写法
1 | void PreOrder(BiTree T){ |
rust语言描述
1 | // Definition for a binary tree node. |
中序遍历
先访问左子树,再访问根节点,再访问右子树
递归写法
1 | void InOrder(BiTree T){ |
非递归写法
- 沿着根结点的左孩子,依次入栈,直到左孩子为空,说明已经可以找到可以输出的结点
- 栈顶元素出栈并访问,若其有右孩子则继续执行1,否则继续执行2
1 | void InOrder(BiTree T){ |
后序遍历
先访问左子树,再访问右子树,再访问根节点
递归写法
1 | void PostOrder(BiTree T){ |
非递归写法
- 沿着根的左孩子,依次入栈,直到左孩子为空;
- 读栈顶元素:若其右孩子不为空,且未被访问过,将右子树执行1,否则栈顶元素出栈并访问
若栈顶元素想要出栈访问,要么右子树为空,要么右子树已经访问完(此时左子树早已访问完)因此我们需要用一个辅助指针,表示最近一次访问的结点:
1 | void PostOrder(BiTree T){ |
后序遍历,当要访问某一个节点时,此时栈中的节点就是从 root 到当前节点的路径上的所有节点。
三种遍历非递归写法
1 |
|
层次遍历
按照从第一层到最后一层,从左到右的顺序进行遍历
1 | void LevelOrder(BiTree T){ |
如果需要在每层访问完成时记录或进行一些操作:
1 | /** |
Morris 莫里斯遍历
Morris 遍历用到了线索二叉树的思想,在 Morris方法中不需要为每个节点额外分配指针指向其前(predecessor)和后继节点(successor),只需要利用 叶子节点中的左右空指针 指向某种顺序遍历下的前驱节点或后继节点就可以了 。
graph TD
subgraph 图2
B1[1]
B2[2]
B3[3]
B4[4]
B5[5]
B6[6]
B7[7]
B1 --> B2
B1 --> B3
B2 --> B4
B2 --> B5
B3 --> B6
B3 --> B7
B4 -.-> B2:::cur2
B5 -.-> B1:::cur1
B6 -.-> B3:::curn
end
subgraph 图1
A1[1] --> A2[2]
A1 --> A3[3]
A2 --> A4[4]
A2 --> A5[5]
A3 --> A6[6]
A3 --> A7[7]
endMorris的整体思路就是将 以某个根结点开始,找到它左子树的最右侧节点之后与这个根结点进行连接
我们可以从 图2 看到,如果这么连接之后,cur 这个指针是可以完整的从一个节点顺着下一个节点遍历,将整棵树遍历完毕,直到 7 这个节点右侧没有指向。代码示例:
1 | /** |
图
术语
基本概念
| 术语 | 解释 |
|---|---|
| 有向图(Directed Graph) | 图中的边有方向,如 |
| 无向图(Undirected Graph) | 边没有方向,如 ,表示双向关系 |
按边结构分类
| 术语 | 解释 |
|---|---|
| 简单图(Simple Graph) | 不允许 自环(从自己连自己)和 重边(两点之间多条边) |
| 多重图(Multigraph) | 允许自环和重边 |
特殊图
| 术语 | 解释 |
|---|---|
| 完全图(Complete Graph) | 任意两个顶点之间都有一条边。无向完全图记作 ,有 条边 |
| 子图(Subgraph) | 从原图中取部分顶点和边组成的图 |
图的连通性
| 术语 | 解释 |
|---|---|
| 连通(Connected) | 无向图中,任意两顶点都有路径相连 |
| 连通图 | 图是整体连通的 |
| 连通分量 | 无向图中极大的连通子图(不能再扩大的连通片) |
| 强连通图 | 在有向图中,任意两点 和 都存在互相可达的路径 |
| 强连通分量 | 有向图中最大的强连通子图 |
树相关
| 术语 | 解释 |
|---|---|
| 生成树(Spanning Tree) | 连通无向图中包含所有顶点且边数最少()的树 |
| 生成森林(Spanning Forest) | 对于不连通的图,由各连通分量分别生成树组成的集合 |
顶点和边性质
| 术语 | 解释 |
|---|---|
| 顶点的度(Degree) | 与顶点相连的边数(无向图中) |
| 入度(In-degree) | 有向图中指向该顶点的边数 |
| 出度(Out-degree) | 有向图中从该顶点指出去的边数 |
| 边的权(Weight) | 边上附加的值(如距离、时间、费用等) |
| 网(Network) | 权图(带边权的图)又称网 |
| 稠密图(Dense Graph) | 边数很多的图,模糊的概念 |
| 稀疏图(Sparse Graph) | 边数很少的图,模糊的概念 |
路径与距离
| 术语 | 解释 |
|---|---|
| 路径 | 顶点序列,任意相邻两点间有边连接 |
| 路径长度 | 该路径上边的数量(或权值总和) |
| 回路(Cycle) | 起点和终点相同的路径 |
| 简单路径 | 路径中顶点不重复 |
| 简单回路 | 回路中除起点终点外其他顶点不重复 |
| 距离 | 两顶点间最短路径的长度 |
存储
邻接矩阵法
无向图:
- 如果
i和j有边:Edge[i][j] = Edge[j][i] = 1 - 如果无边:
Edge[i][j] = Edge[j][i] = 0
有向图:
- 如果有
i → j的边:Edge[i][j] = 1 - 如果没有:
Edge[i][j] = 0
网(带权图):
-
如果
i → j的权为w,则Edge[i][j] = w -
无边时一般设为
∞(或一个非常大的数) -
C语言描述
1 |
|
- C++描述
1 |
|
邻接表法
- C语言描述
1 |
|
- C++描述
十字链表法
1 |
|
邻接多重表
邻接多重表是无向图的另一种链式存储结构
1 | typedef struct ENode { |
图的遍历
广度优先搜索
1 | bool visited[MAX_VERTEX_NUM]; |
如果图为非带权图,可以通过BFS来求单源最短路径问题,主要利用广度优先遍历是按照距离从进到远来遍历图中每个顶点的的性质来决定的。
深度优先搜索
递归形式
1 | bool visited[MAX_VERTEX_NUM]; |
非递归形式
1 | void DFS_Non_RC(AGraph &G, int v){ |
最小生成树
Prim算法
思想:从一个点开始,每次选择代价最小的边把新的顶点加入生成树
更适合:稠密图(邻接矩阵)
Kruskal算法
思想:把图的所有边按权值排序,从小到大选择边,只要不成环就选
适合:稀疏图
用到并查集避免形成环路
最短路径
Dijkstra算法
单源最短路径问题
Floyd算法
各个顶点之间的最短路径
拓扑排序
以下面这题为例:
1 |
|
关键路径
哈希
参考文章:
哈希表 (Hash Table)又称散列表是一种数据结构 ,它使用键值对(Key-Value Pair)来存储数据,并通过哈希函数将键映射到数组的特定位置,从而实现高效的查找、插入和删除操作。
概念
-
存储结构: 哈希表通常由一个数组和一个哈希函数组成。数组的每个元素称为桶(Bucket),它可以存储一个或多个键-值对
-
哈希函数(Hash Function) : 哈希函数将键转换成一个数组的索引(即一个整数)
-
哈希化(Hashing):是将输入数据(通常是任意长度的)通过哈希函数转换为固定长度的输出(数组范围内下标)的过程
-
哈希冲突(Hash Collision) : 当不同的键被哈希函数映射到相同的索引时,就发生了哈希冲突。常用的解决哈希冲突的方式有链地址法和开放地址法
-
装填因子(Load Factor):哈希表中存储的元素数量与数组大小(总槽位数量)的比率
- 哈希表的大小(槽位数)是固定的,但存储的元素项数可以超过槽位数
- 装填因子表示哈希表空间的利用效率。较高的装填因子意味着表中存储的元素较多,空间利用率高
- 当装填因子增加(接近于 1 或更高) 时,哈希表的查找效率可能降低,尤其是在使用开放地址法时,冲突处理需要更多的探测次数
- 使用链地址法时,装填因子的增加会导致链表长度增加,从而提高平均查找时间
- 在动态哈希表中,当装填因子超过某个阈值(如 0.75),通常会触发哈希表的扩容,以减少冲突和提高性能
- 如果装填因子过低,可能会导致缩容,以节省空间
- 理想的装填因子:
- 开放地址法:理想的装填因子通常低于 1,推荐在 0.5 到 0.75 之间,以平衡空间利用和查找效率
- 链地址法:装填因子可以超过 1,因为多个元素可以存储在同一个槽中。通常装填因子在 0.7 到 1.0 是较好的选择,但也可以更高,具体取决于链表长度对性能的影响
-
扩容(Rehashing):当哈希表的装载因子超过设定值时,可能需要进行扩容。扩容通常包括创建一个更大的数组,并重新计算所有键的哈希值,以将它们映射到新数组中
-
缩容:缩容是指在数据量减少到一定程度时,减少哈希表的容量,以节省空间并提高内存利用效率
哈希函数
哈希函数将键转换成一个数组的索引(即一个整数),好的哈希函数应该具备的优点:
-
快速的计算:哈希表的优势就在于效率,所以快速获取到对应的hashCode非常重要
-
均匀的分布:哈希表中无论是链地址法还是开放地址法,当多个元素映射到同一个位置的时候,都会影响效率,优秀的哈希函数应该尽可能将元素映射到不同的位置,让元素在哈希表中均匀的分布
键的类型
归根结底哈希函数就是将键key转换为索引值,能作为键key的类型有很多数字、字符串 、对象等等,下面主要讨论字符串作为键,因为哈希表的键通常被实现为字符串,主要是出于以下几个原因:
-
一致性:使用字符串作为键可以提供一致的方式来处理不同类型的键。即使是数字和其他类型,最终也会转换为字符串进行存储
-
哈希函数:哈希表使用哈希函数将键映射到数组的索引。字符串通常更易于处理,因为它们可以直接进行哈希运算,而其他类型(如对象)可能需要更多的处理步骤
-
易于比较:字符串具有明确的比较规则,这使得查找、插入和删除操作变得更简单和高效
-
空间效率:在许多语言中,字符串作为键的存储方式通常比对象或其他复杂类型更紧凑,减少了内存使用
-
灵活性:字符串可以表示各种信息,能够轻松适应不同的场景,例如数据库索引、字段名称等
哈希函数要将字符串转换为数字,有两种方法:
-
方法一:将字符的 ASCII 值相加,问题就是很多键最终的值可能都是一样的,比如
was/tin/give/tend/moan/tick都是43 -
方法二:使用一个常数乘以键的每个字符的 ASCII 值,得到的数字可以基本保证它的唯一性(下面解释),和别的单词重复率大大降低,问题是得到的值太大了,因为这个值是要作为索引的,创建这么大的数组是没有意义的
其实我们平时使用的大于10的数字,可以用一种幂的连乘来表示它的唯一性: 比如:
7654 = 7*10³ + 6*10² + 5*10 + 4,单词也可以使用这种方案来表示:比如cats = 3*27³ + 1*27² + 20*27 + 17= 60337,27是因为有27个字母那么对于获取到的索引太大这个问题又出现了压缩算法,即把幂的连乘方案中得到的巨大整数范围压缩到可接受的数组范围中,有一种简单的方法就是使用取余操作符,它的作用是得到一个数被另外一个数整除后的余数,数组的索引是有限的,比如从 0 到 n-1(其中 n 是可接受的数组长度),通过对进行取余操作,可以将它们限制在这个范围内
霍纳法则
上面计算哈希值的时候使用的方式:cats = 3*27³ + 1*27² + 20*27 + 17= 60337,我们可以抽象成一个表达式:a(n)x^n + a(n-1)x^(n-1) +... + a(1)x + a(0)
-
乘法次数:
n + (n-1) +... + 1 = n(n + 1)/2 -
加法次数:
n次- 时间复杂度:
O(N²)
- 时间复杂度:
通过变换可以得到一种快得多的算法,即解决这类求值问题的高效算法霍纳法则 (Horner’s Method),在中国被称为秦九韶算法,霍纳法则核心是将普通多项式重写为嵌套形式,以三次多项式为例,逐步提取公因子 (x) 减少计算量,推导过程如下:
原始多项式形式(三次多项式):
- 第一步:提取前两项的公因子 (x):
- 第二步:对括号内部分再次提取公因子 (x):
- 第三步:整合剩余项,形成最终嵌套形式:
霍纳法则通用形式(n次多项式) 对任意 (n) 次多项式 ,可统一变形为:
其中:
- 乘法次数:
n次 - 加法次数:
n次 - 时间复杂度:从
O(N²)降到了O(N)
均匀的分布
在设计哈希表时,已经处理映射到相同下标值的情况:链地址法或者开放地址法,但是无论哪种方案都是为了提高效率,最好的情况还是让数据在哈希表中均匀分布,因此需要在使用常量的地方,尽量使用质数,比如哈希表的长度和N次幂的底数。
为什么他们使用质数,会让哈希表分布更加均匀呢?
因为质数和其他数相乘的结果相比于其他数字更容易产生唯一性的结果,减少哈希冲突。
比如Java中的HashMap的N次幂的底数选择的是31,比较常用的数是31或37,是经过长期观察分布结果得出的
哈希冲突
当不同的键被哈希函数映射到相同的索引时,就发生了哈希冲突。常用的解决哈希冲突的方式有链地址法和开放地址法
链地址法
链地址法是一种比较常见的解决冲突的方案(也称为拉链法),每个哈希表的槽(bucket)可以存储多个元素。当多个键被哈希到同一个索引时,链地址法会将这些元素存储在一个链表或其他数据结构中

-
原理
-
链地址法的核心思想是将每个数组元素作为一个桶,桶内存储多个键值对。通常使用链表或数组来实现
-
一旦发现重复,将重复的元素插入到链表的首端或者末端即可
-
当查询时先根据哈希化后的下标值找到对应的位置,再取出链表,依次查询找寻找的数据
-
-
效率
- 当用链地址法实现哈希表时,查找一个元素的过程分为两部分:
- 计算哈希值并定位到槽位:这一步是一个常数时间操作,通常是 1 次操作,不依赖链表的长度
- 遍历链表查找元素:如果多个元素在同一个槽位上,哈希表会在这个槽位的链表中查找元素。查找的平均次数是链表长度的一半,通常是 loadFactor / 2
- 因此成功可能只需要查找链表的一半即可:1 + loadFactor/2,不成功可能需要将整个链表查询完才知道不成功:1 + loadFactor
- 链地址法相对来说效率是好于开放地址法的,所以在真实开发中使用链地址法的情况较多,它不会因为添加了某元素后性能急剧下降,比如在 Java 的 HashMap 中使用的就是链地址法
- 当用链地址法实现哈希表时,查找一个元素的过程分为两部分:

开放地址法
开放地址法的主要工作方式是当发生哈希冲突时,寻找数组中的下一个空槽来存储冲突的元素,有三种探索空槽的方式:
-
线性探测
- 线性探测(
Linear Probing)是每次发生冲突时,检查下一个空白的槽index = (hashFunc(key) + i) % tableSize其中 i 是冲突次数 - 效率

-
问题:线性有一个比较严重的问题就是聚集
-
比如在没有任何数据的时候,插入的是22-23-24-25-26,那么意味着下标值:0-1-2-3-4的位置都有元素,这种一连串填充单元就叫做聚集
-
聚集会影响哈希表的性能,无论是插入/查询/删除都会影响,比如我们插入一个38,会发现连续的单元都不允许放置数据,并且在这个过程中需要探索多次
-
- 线性探测(

-
二次探测
- 二次探测(
Quadratic Probing)根据冲突次数的平方来确定下一个槽的位置index = (hashFunc(key) + i^2) % tableSize - 优化线性问题:
- 线性探测可以看成是步长为
1的探测,比如从下标值x开始,那么线性测试就是x+1,x+2,x+3依次探测 - 二次探测对步长做了优化,比如从下标值
x开始x+1²,x+2²,x+3²,这样就可以一次性探测比较长的距离,比避免那些聚集带来的影响
- 线性探测可以看成是步长为
- 效率:
- 问题:
- 二次探测依然存在问题,比如连续插入的是
32-112-82-2-192,那么依次累加的时候步长的相同的 - 也就是这种情况下会造成步长不一样的一种聚集,还是会影响效率
- 二次探测依然存在问题,比如连续插入的是
- 二次探测(
-
再哈希法
- 再哈希(
Double Hashing)使用第二个哈希函数计算步长,确定下一个槽的位置index = (hashFunc1(key) + i \* (constant - (hashFunc2(key) % constant))) % tableSize - 优化二次探测问题:
- 二次探测的算法产生的探测序列步长是固定的: 1-4-9-16依此类推,而再哈希法把键用另外一个哈希函数,再做一次哈希化,用这次哈希化的结果作为步长
- 第二次哈希化需要具备如下特点:
- 和第一个哈希函数不同(不要再使用上一次的哈希函数了, 不然结果还是原来的位置)
- 不能输出为0(否则将没有步长,每次探测都是原地踏步,算法就进入了死循环)
- 计算机专家已经设计出一种工作很好的哈希函数:
stepSize = constant - (hanshFunc(key) % constant),constant是质数,且小于数组的容量
- 效率
- 再哈希(

扩容/缩容
- 扩容:随着数据量的增多,每一个index对应的bucket会越来越长,也就造成效率的降低,所以在合适的情况对数组进行扩容,比如扩容两倍
扩容可以简单的将容量增大两倍,但是这种情况下所有的数据项一定要同时进行修改(重新调用哈希函数,来获取到不同的位置),比如hashCode = 12的数据项,在arraySize = 8的时候放index = 4的位置,在arraySize = 16的时候放index = 12的位置
- 缩容:当哈希表的装填因子(元素数量与哈希表容量的比值)低于某个阈值时,会考虑缩容以节省空间并提高内存利用效率
缩容时通常将哈希表容量减小为当前容量的一半,并重新计算并分配所有现有元素的位置
什么情况下扩容/缩容?
比较常见的情况是 loadFactor > 0.75 的时候进行扩容,比如Java的哈希表就是在装填因子大于0.75的时候,对哈希表进行扩容
通常会设置一个下限装填因子,比如 0.25,低于此值时触发缩容,但也要避免过度缩容:通常会设置一个较小的、合理的最小容量,比如 7 或 8,以保证哈希表即使在元素很少时也保持一定的容量,从而避免频繁地扩容和缩容
哈希表的实现
1 |
|
常用算法
哈希
| 题目 | 链接 |
|---|---|
| P1 两数之和✨✨✨ | |
| P49 字母异位词分组 | |
| P128 最长连续序列✨✨✨ | |
| P383 赎金信 | |
| P205 同构字符串 | |
| P290 单词规律 | |
| P242 有效的字母异位词 | |
| P49 字母异位词分组 | |
| P202 快乐数 | |
| P219 存在重复元素 II✨✨✨ | |
| P966 元音拼写检查器 | |
| P3484 设计电子表格 | |
| P380 O(1) 时间插入、删除和获取随机元素✨✨✨ | |
| P3289 数字小镇中的捣蛋鬼 | |
| P13 罗马数字转整数 |
双指针
快慢指针
| 题目 | 链接 |
|---|---|
| P234 回文链表 | |
| P142 环形链表 II | |
| P80 删除有序数组中的重复项 II ✨✨✨ | |
| P287 寻找重复数 ✨✨✨ | |
| P19 删除链表的倒数第 N 个结点 | |
| P160 相交链表 |
左右指针
| 题目 | 链接 |
|---|---|
| P283 移动零 | |
| P125 验证回文串 | |
| P27 移除元素 | |
| P167 两数之和 II - 输入有序数组 | |
| P88 合并两个有序数组 | |
| P392 判断子序列 | |
| P75 颜色分类 | |
| P31 下一个排列 | |
| P15 三数之和 ✨✨✨ | |
| P11 盛水最多的容器 ✨✨✨ | |
| P611 有效三角形的个数 | |
| P42 接雨水 ✨✨✨ |
链表
| 题目 | 链接 |
|---|---|
| P3217 从链表中移除在数组中存在的节点 | |
| P141 环形链表 | |
| P2 两数相加 | |
| P21 合并两个有序链表 | |
| P138 随机链表的复制 | |
| P92 反转链表 II | |
| P25 K 个一组翻转链表✨✨✨ | |
| P19 删除链表的倒数第 N 个结点 | |
| P82 删除排序链表中的重复元素 II✨✨✨ | |
| P61 旋转链表 | |
| P86 分割链表 | |
| P146 LRU缓存✨✨✨ | |
| P148 排序链表 | |
| P160 相交链表 | |
| P206 反转链表✨✨✨ | |
| P234 回文链表✨✨✨ | |
| P142 环形链表 II✨✨✨ | |
| P24 两两交换链表中的节点 |
树
二叉树遍历
先序遍历(深度优先),中序遍历,后序遍历,层次遍历,Morris遍历
| 题目 | 链接 |
|---|---|
| P104 二叉树的最大深度 | |
| P100 相同的树 | |
| P226 翻转二叉树 | |
| P101 对称二叉树 | |
| P105 从前序与中序遍历序列构造二叉树✨✨✨ | |
| P106 从中序与后序遍历序列构造二叉树✨✨✨ | |
| P117 填充每个节点的下一个右侧节点指针 II | |
| P114 二叉树展开为链表✨✨✨ | |
| P112 路径总和 | |
| P129 求根节点到叶节点数字之和 | |
| P124 二叉树中的最大路径和✨✨✨ | |
| P173 二叉搜索树迭代器 | |
| P222 完全二叉树的节点个数✨✨✨ | |
| P236 二叉树的最近公共祖先✨✨✨ | |
| P199 二叉树的右视图 | |
| P637 二叉树的层平均值 | |
| P102 二叉树的层序遍历 | |
| P103 二叉树的锯齿形层序遍历 | |
| P530 二叉搜索树的最小绝对差 | |
| P98 验证二叉搜索树 | |
| P230 二叉搜索树中第 K 小的元素 | |
| P94 二叉树的中序遍历 | |
| P543 二叉树的直径✨✨✨ | |
| P437 路径总和 III✨✨✨ |
字典树
一个string作为一个节点
1 | struct TrieNode { |
一个char作为一个节点
1 | struct TrieNode{ |
| 题目 | 链接 |
|---|---|
| P14 最长公共前缀 | |
| P208 实现Trie(前缀树) | |
| P211 添加与搜索单词 - 数据结构设计 | |
| P212 单词搜索 II✨✨✨ | |
| P139 单词拆分✨✨✨ |
图
DFS 和 BFS,拓扑排序
| 题目 | 链接 |
|---|---|
| P200 岛屿数量✨✨✨ | |
| P130 被围绕的区域 | |
| P133 克隆图 | |
| P399 除法求值 | |
| P207 课程表✨✨✨ | |
| P210 课程表 II✨✨✨ | |
| P909 蛇梯棋✨✨✨ | |
| P443 最小基因变化 | |
| P127 单词接龙✨✨✨ | |
| P994 腐烂的橘子✨✨✨ |
栈
| 题目 | 链接 |
|---|---|
| P20 有效的括号 | |
| P71 简化路径 | |
| P155 最小栈✨✨✨ | |
| P150 逆波兰表达式求值✨✨✨ | |
| P224 基本计算器✨✨✨ | |
| P394 字符串解码✨✨✨ | |
| P2197 替换数组中的非互质数✨✨✨ | |
| P32 最长有效括号✨✨✨ |
单调栈
单调栈的核心规则就是:往栈里压元素时,如果破坏了单调性,就弹出栈顶直到恢复单调。
假设我们要维护“单调递减栈”(栈顶最小)要么 push,要么 pop 若干次,再 push,永远保持“单调递减”。
| 类型 | 栈里从栈底到栈顶 | 作用 |
|---|---|---|
| 单调递增栈 | 值越来越大 | 适用于找「下一个更大元素」 |
| 单调递减栈 | 值越来越小 | 适用于找「下一个更小元素」 |
它的核心思想是:
用单调性过滤掉无用元素,保证“最近的有效元素”在栈顶
| 题目 | 链接 |
|---|---|
| P3542 将所有元素变为 0 的最少操作次数✨✨✨ | |
| P739 每日温度✨✨✨ | |
| P84 柱状图中的最大矩形✨✨✨ |
队列
单调队列
| 题目 | 链接 |
|---|---|
| P239 滑动窗口最大值 |
矩阵
| 题目 | 链接 |
|---|---|
| P73 矩阵置零 ✨✨✨ | |
| P54 螺旋矩阵 | |
| P48 旋转图像✨✨✨ | |
| P240 搜索二维矩阵 II✨✨✨ | |
| P36 有效的数独 | |
| P289 生命游戏✨✨✨ |
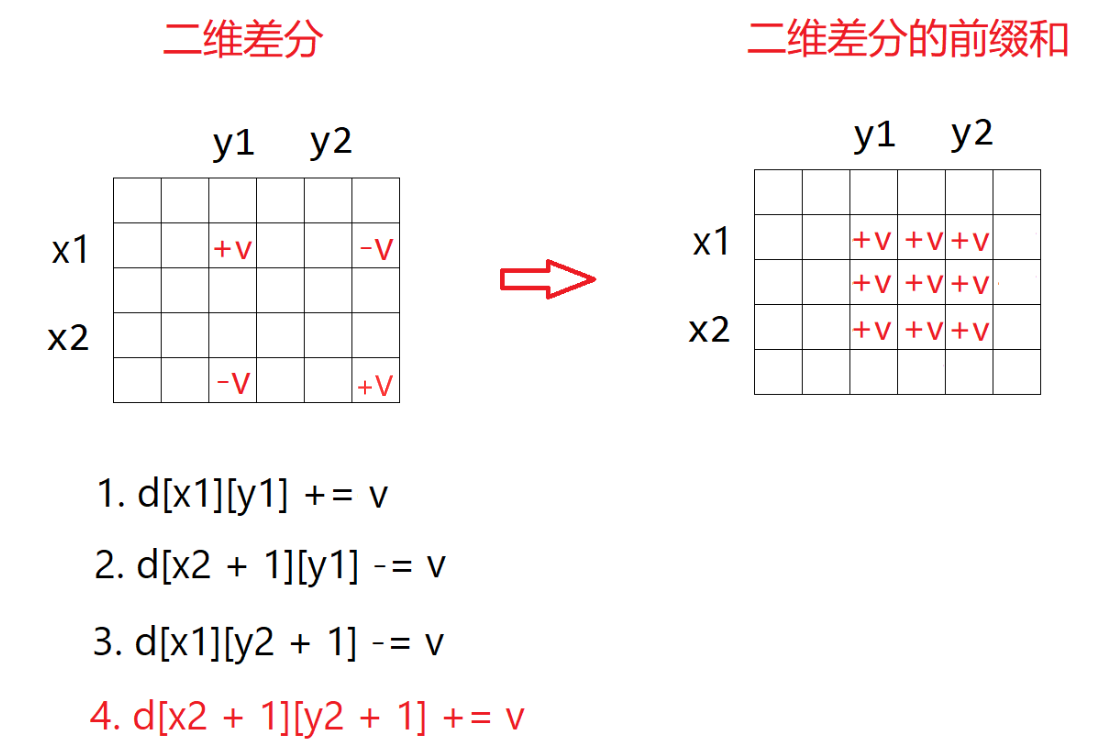
差分与前缀和
| 题目 | 链接 |
|---|---|
| P2536 子矩阵元素加一✨✨✨ |
滑动窗口
经典模板
1 | int left=0, right=0; |
| 题目 | 链接 |
|---|---|
| P3 无重复字符的最长子串 | |
| P438 找到字符串中所有字母异位词 | |
| P209 长度最小的子数组 | |
| P30 串联所有单词的子串 ✨✨✨ | |
| P76 最小覆盖子串 ✨✨✨ | |
| P3186 施咒的最大总伤害 |
回溯
解决⼀个回溯问题,实际上就是⼀个决策树的遍历过程。
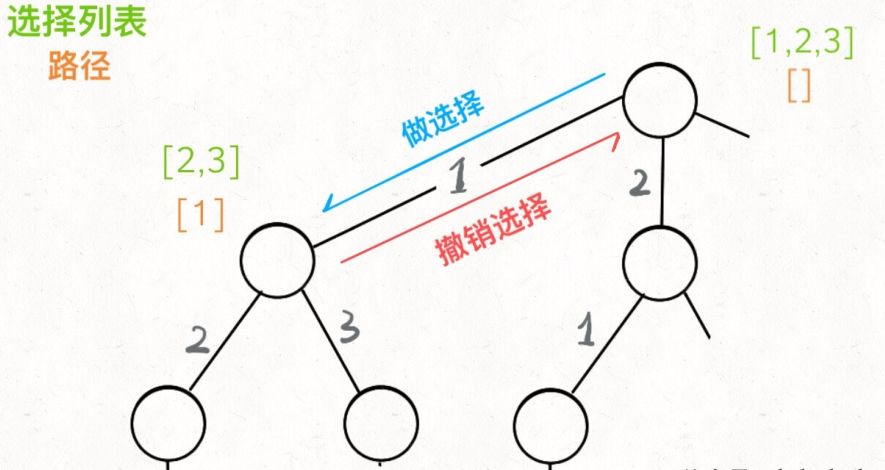
你只需要思考个问题:
- 路径:也就是已经做出的选择。
- 选择列表:也就是你当前可以做的选择。
- 结束条件:也就是到达决策树底层,⽆法再做选择的条件。
经典模板框架
1 | result = [] |
| 题目 | 链接 |
|---|---|
| P46 全排列 | |
| P78 子集 | |
| P17 电话号码的字母组合 | |
| P39 组合总和 | |
| P22 括号生成✨✨✨ | |
| P79 单词搜索 | |
| P212 单词搜索 II | |
| P51 N皇后✨✨✨ | |
| P52 N皇后 II | |
| P77 组合 | |
| P131 分割回文串✨✨✨ |
动态规划
| 题目 | 链接 |
|---|---|
| P120 三角形最小路径和 | |
| P1039 多边形三角剖分的最低得分 | |
| P122 买卖股票的最佳时机 II | |
| P55 跳跃游戏 | |
| P45 跳跃游戏II | |
| P3147 从魔法师身上吸取的最大能量 | |
| P3186 施咒的最大总伤害 | |
| P3539 魔法序列的数组乘积之和 | |
| P392 判断子序列 | |
| P474 一和零 | |
| P70 爬楼梯 | |
| P53 最大子数组和 | |
| P918 环形子数组的最大和 | |
| P198 打家劫舍 | |
| P322 零钱兑换 | |
| P300 最长递增子序列 | |
| P139 单词拆分 | |
| P64 最小路径和 | |
| P63 不同路径 II | |
| P5 最长回文子串 | |
| P221 最大正方形 | |
| P72 编辑距离 | |
| P97 交错字符串 | |
| P123 买卖股票的最佳时机 III | |
| P188 买卖股票的最佳时机 IV | |
| P131 分割回文串 | |
| P118 杨辉三角 | |
| P279 完全平方数 | |
| P152 乘积最大子数组 | |
| P416 分割等和子集 | |
| P32 最长有效括号 | |
| P62 不同路径 | |
| P1143 最长公共子序列 |
贪心
| 题目 | 链接 |
|---|---|
| P55 跳跃游戏✨✨✨ | |
| P45 跳跃游戏II✨✨✨ | |
| P134 加油站✨✨✨ | |
| P135 分发糖果✨✨✨ | |
| P1578 使绳子变成彩色的最短时间 | |
| P3228 将 1 移动到末尾的最大操作次数 | |
| P763 划分字母区间 | |
| P121 买股票的最佳时机 | |
| P976 三角形的最大周长 |
排序
归并排序,计数排序,快速排序,堆排序
| 题目 | 链接 |
|---|---|
| P148 排序链表 | |
| P2785 将字符串中的元音字母排序 | |
| P3541 找到频率最高的元音和辅音 | |
| P274 H指数 | |
| P3005 最大频率元素计数 |
快速排序
Lomuto partition
每次partition确定一个值的位置。
1 |
|
Hoare partition
它并不要求 pivot 最终落在正确位置,而是保证:
1 |
|
也可以这样写(推荐写法)
1 | // 快速排序函数(Hoare 分区方案实现) |
参考题目
| 题目 | 链接 |
|---|---|
| P215 数组中的第K个最大元素 |
堆排序
对完全二叉树结点进行编号,有如下关系
| 项目 | 1-based 编号(根=1) | 0-based 编号(根=0) |
|---|---|---|
| 左孩子 | ||
| 右孩子 | ||
| 父节点 | ||
| 至少有左孩子的条件 | ||
| 右孩子存在条件 | ||
| 叶节点条件 | 或 | |
| 只有左孩子条件 | 且 | |
| 深度(root 层=1) | ||
| 深度(root 层=0) |
1 |
|
| 题目 | 链接 |
|---|---|
| P3408 设计任务管理器 | |
| P407 接雨水II✨✨✨ | |
| P215 数组中的第K个最大元素 | |
| P373 查找和最小的K对数字 | |
| P295 数据流的中位数✨✨✨ | |
| P239 滑动窗口最大值 | |
| P347 前 K 个高频元素 | |
| P502 IPO |
分治
二分法的本质是:寻找序列中第一个满足某条件的元素的位置。
二分法中通常让人迷惑的地方在于:while中什么时候写小于等于,什么时候不写等于;
首先考虑升序排列的元素(降序等价),应当分为两种情况:
- 没有重复元素;
这种情况下的问题一般是:查找某个元素target在序列中是否出现,如果出现则返回出现的序号,如果不出现,则该元素应该插入的位置。
也就是确定一个区间[x,x],target就是x位置的元素,如果没有这个元素,那么确定出来的区间是[x+1,x],左边界大于右边界,也就是区间中不存在元素。
1 |
|
- 有重复元素。后者是前者的一般化,也就是说后者的算法也同样适用于前者。
这种情况下的问题则是,确定第一个大于等于target的元素序号,和第一个大于target的元素序号,两个子问题。
(1)查找下界(第一个大于等于target的元素的序号,[x,y) 的x )
1 | int LowerBound(const std::vector<int>& a, int target) |
(2)查找上界(第一个大于target的元素的序号,[x,y)的y)
1 | int UpperBound(const std::vector<int>& a, int target) |
以下面这题为例:
1 |
|
找end时需要使用 右中位数 (upper mid):mid = left + (right - left + 1) / 2; 这样保证 mid > left,区间一定缩小。
| 题目 | 链接 |
|---|---|
| P34 排序数组中查找元素的第一个和最后一个位置✨✨✨ | |
| P108 将有序数组转换为二叉搜索树 | |
| P148 排序链表 | |
| P427 建立四叉树 | |
| P23 合并K个升序链表 | |
| P35 搜索插入位置 | |
| P74 搜索二维矩阵 | |
| P240 搜索二维矩阵 II✨✨✨ | |
| P162 寻找峰值 | |
| P33 搜索旋转排序数组 | |
| P153 寻找旋转排序数组中的最小值 | |
| P4 寻找两个正序数组的中位数 |
并查集
| 题目 | 链接 |
|---|---|
| P3607 电网维护 |