SR-IOV原理与实现
时间轴
2025-05-22
- init
I/O 虚拟化(IOV)
I/O 虚拟化(IOV) 是指多个虚拟机之间共享单一的 I/O 资源。实现 IOV 的方法包括:
- 纯软件实现的共享方式,
- 硬件支持的共享方式,
- 以及 软硬结合的混合方式。
基于纯软件实现的共享
- device emulation(完全虚拟化):
设备仿真模式会模仿那些被广泛支持的真实硬件设备(例如 Intel 的 1Gb 网卡),从而使虚拟机中的操作系统可以继续使用它原本就支持的驱动程序。虚拟机管理程序(VMM,Virtual Machine Monitor)会模拟这个 I/O 设备,以确保兼容性,并在实际 I/O 操作前处理这些操作,然后再把它们转发给实际的物理设备(这个物理设备可能和模拟的设备不一样)。
⚠️ 问题:这样一来,I/O 操作就必须经过两层 I/O 栈——一层在虚拟机内部,另一层在虚拟机管理程序中,这会增加开销,降低性能。 - the split-driver model(半虚拟化):
这种方法和设备仿真类似,但它不再模拟一个传统设备。而是采用一种前后端驱动配合的方式:- 前端驱动运行在虚拟机的客户操作系统中;
- 后端驱动运行在虚拟机管理程序中。
两者配合工作,专门为资源共享进行了优化。相比设备仿真,这种方法的优势在于:不需要模拟整个设备,从而性能更好、开销更小。后端驱动会直接与实际物理设备进行通信。
| 方法 | 优点 | 缺点 |
|---|---|---|
| device emulation | 兼容性好,可使用现有驱动 | 性能较差,要经过两层 I/O 栈 |
| the split-driver model | 性能更好,优化了共享 | 需要专门为前后端编写驱动 |
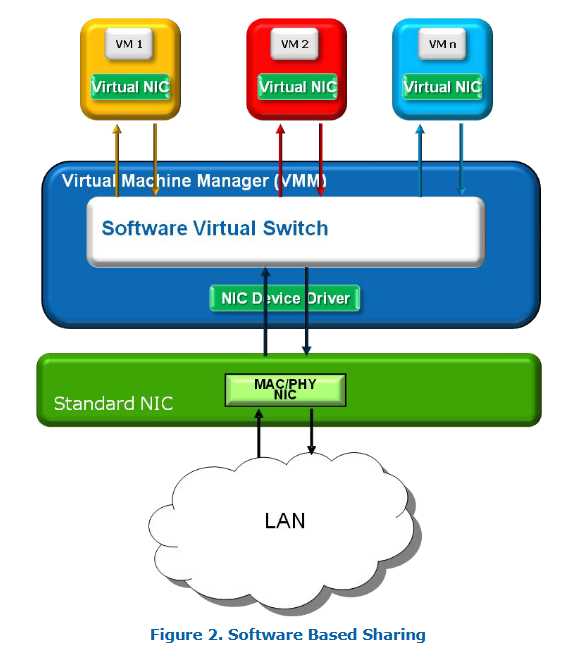
基于软件的共享的缺点
无论是设备仿真还是分离驱动(即半虚拟化驱动),它们通常只能提供物理硬件功能的一部分,因此可能无法利用物理设备提供的高级功能。
此外,虚拟机管理程序(VMM)在实现一个虚拟的软件交换机(用于将数据包在多个虚拟机之间转发)时,可能会消耗大量的 CPU 资源。这种 CPU 开销会(而且通常确实会)降低 I/O 设备的最大吞吐量。
举个例子:如果只使用设备仿真方式,10Gbps 的以太网控制器最大只能达到 4.5 到 6.5Gbps 的吞吐量(这个范围依赖于具体测试服务器的架构)。
其中一个主要原因是:每个数据包都必须通过软件交换机,而这就需要使用 CPU 来处理这些数据包,造成性能瓶颈,无法达到线速(Line Rate)或接近线速的传输能力。
基于软件的 I/O 虚拟化方式虽然兼容性好,但也存在一些明显的性能瓶颈和功能限制,这些缺陷在对性能要求较高的场景(如高频交易、数据中心、网络功能虚拟化等)中尤其明显:
| 缺点 | 说明 |
|---|---|
| 功能不完整 | 无法访问设备的全部高级特性,如硬件加速、QoS、SR-IOV等。 |
| 高 CPU 开销 | 每个 I/O 操作都需要 VMM 介入处理,特别是在网络场景下,包处理要通过软件交换机,会消耗大量 CPU。 |
| 吞吐量受限 | 理论 10Gbps 的网卡实际只有 4.5~6.5Gbps 的吞吐,远低于线速。 |
直接分配(Direct Assignment)
也称设备直通
基于软件的共享方式在每次 I/O 操作中都增加了额外开销,因为在客户机驱动和 I/O 硬件之间存在一个仿真层。这种中间层的存在还带来了另一个影响:无法使用物理设备提供的硬件加速功能。
为了解决这些问题,可以将物理硬件直接暴露给客户操作系统(Guest OS),并让它运行原生设备驱动,从而减少中间层带来的性能损失。
硬件厂商(如Intel)为此引入了一些增强功能,用于支持内存地址转换并确保内存保护,使得设备能够直接进行主机内存的 DMA 操作。这些增强功能可以绕过虚拟机管理程序(VMM)的 I/O 仿真层,从而提升虚拟机的 I/O 吞吐性能。
Intel® VT-x 技术的一个特性是:如果由 VMM 进行配置,虚拟机可以直接访问物理地址。这样,虚拟机中的设备驱动就可以直接写入 I/O 设备的寄存器(例如配置 DMA 描述符等)。
而 Intel® VT-d 技术则提供了类似的能力,使 I/O 设备可以直接写入虚拟机的内存空间,例如进行 DMA 操作。
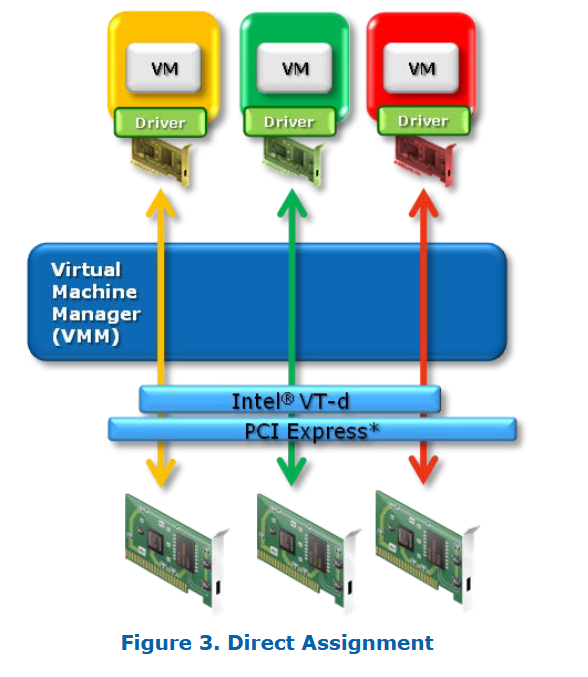
实现直接分配的机制在不同厂商之间有所差异,但其基本思路相同:虚拟机管理程序利用并配置诸如 Intel® VT-x 和 VT-d 这类技术,在数据收发过程中完成地址转换,确保数据可以安全、高效地在虚拟机与 I/O 设备之间传输。
✅ 优势:
- 绕过中间的仿真层,减少 CPU 开销;
- 支持原生驱动,可以启用设备的全部功能(包括硬件加速);
- 大幅提升性能,尤其是吞吐量和延迟方面的改进明显;
- 适合高性能场景,如网络功能虚拟化(NFV)、GPU 加速计算等。
⚠️ 问题:
直接分配的一个主要问题是其可扩展性有限:一个物理设备只能分配给一个虚拟机。
例如,一个双端口的网卡(NIC)只能同时提供给两个虚拟机使用(每个虚拟机占用一个端口)。然而,系统中可插入的 I/O 设备数量存在根本性的限制。
设想一下不久将来的一个相对强大的服务器:
它可能拥有 4 个物理 CPU,每个 CPU 有 12 个核心,总共有 48 个核心。按照“一核一虚拟机”的经验规则,这台服务器可能运行 48 个虚拟机。如果你希望为每个虚拟机都使用 Direct Assignment 的方式分配设备,就需要 48 个物理端口。
单根 I/O 虚拟化(SR-IOV)
以上架构问题根源在于硬件底层原生不支持共享,需要一种新型的原生可共享设备(Navitely Shared Devices),这些设要能为每个虚拟机复制必要的资源,使得虚拟机可以直接连接到 I/O 设备,并且无需 VMM 参与即可完成主要的数据传输。
原生可共享设备通常会为每个虚拟接口提供独立的内存空间、工作队列、中断和命令处理机制,而在主机接口之后共享一些公共资源。这些共享资源仍然需要管理,通常会将一组管理寄存器暴露给 VMM 中的可信分区(Trusted Partition),为每个虚拟机提供独立的工作队列和命令处理能力,这类设备能够同时接收多个来源的指令,并在发送给二级互连(如 Ethernet 或 SAS 链路)之前将其整合,而不再需要虚拟化软件将多个 I/O 请求串行化处理。
这种原生可共享设备可以通过多种方式实现,既有标准化的,也有专有的。由于大多数这类设备是通过 PCI 接口访问的,PCI-SIG(PCI Special Interest Group)决定制定一个标准机制来支持这一功能。
这个标准就是:PCI-SIG 单根 I/O 虚拟化和共享规范(SR-IOV,Single Root I/O Virtualization)
SR-IOV 定义了一个标准机制,使设备能实现原生共享。
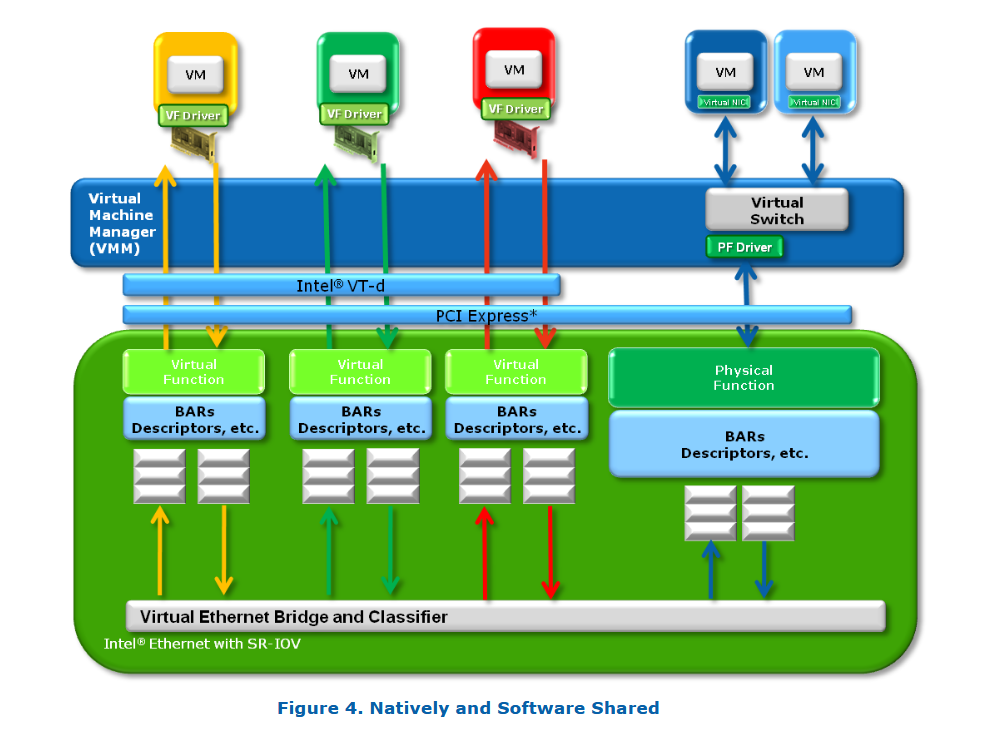
PCI-SIG SR-IOV 规范
PCI-SIG SR-IOV规范的目标可以总结为一句话:规范化一种绕过虚拟机管理程序(VMM)参与数据传输的方式,通过为每台虚拟机提供独立的内存空间、中断通道和 DMA 通道,以实现高效的 I/O 虚拟化。
SR-IOV 的体系结构设计允许一个设备支持多个虚拟功能(VF, Virtual Functions),并在此过程中重点关注每个额外功能的硬件成本最小化。
SR-IOV 引入了两种新的 PCIe 功能类型:
物理功能(PF, Physical Functions):
完整的 PCIe 功能,包含 SR-IOV 扩展能力(Extended Capability)。该能力用于配置和管理 SR-IOV 的相关功能。虚拟功能(VF, Virtual Functions):
轻量级 PCIe 功能,包含完成数据传输所需的资源,但其配置资源经过精简设计,以降低硬件开销。
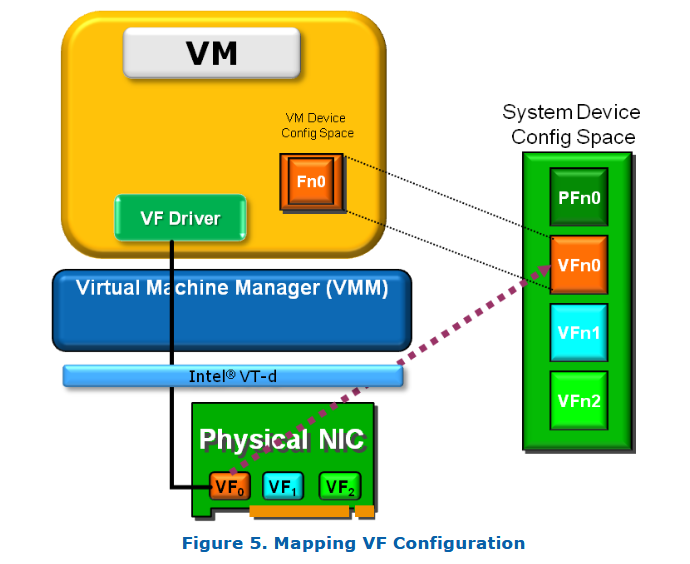
SR-IOV 提供了一种机制,使得一个单一的物理功能(例如一个以太网端口)可以表现为多个独立的“物理设备”。
一个支持 SR-IOV 的设备可以被配置(通常由 VMM 完成),使其在 PCI 配置空间 中呈现为多个功能(Function),每个功能都拥有独立的 配置空间,包括自己的 基地址寄存器(BARs)。SR-IOV 设备可以配置为支持多个独立的虚拟功能(VF),每个 VF 都有独立的 PCI 配置空间。VMM 会将这些 VF 分配给不同的虚拟机。
虚拟机管理程序(VMM)会将一个或多个虚拟功能(VF)分配给某个虚拟机,这个过程涉及将 VF 的真实配置空间映射为该 VM 所能看到的 PCI 配置空间。同时,诸如 Intel® VT-x 和 VT-d 之类的内存地址转换技术提供了硬件加速机制,可以使 DMA 数据直接在 VM 和设备之间传输,从而绕过 VMM 中的软件交换开销。
生态系统依赖
BIOS
- BIOS 在系统启动时负责分配 内存映射I/O(MMIO)空间 和 PCI Express总线号(Bus Numbers) 给主机桥(host bridges)。
- 许多系统中 PCI 资源分配缺乏标准化,软件依赖 BIOS 配置设备,确保有足够的内存空间和总线范围,支持主机桥下面的所有 I/O 设备。
- 需要增强 BIOS 的枚举代码,使其能识别 SR-IOV设备,并分配足够的 MMIO 空间给所有虚拟功能(Virtual Functions,VFs)。
- 具体如何解析 PCI 配置空间并计算 VF 所需最大 MMIO 空间,详见 PCI-SIG SR-IOV 规范。
虚拟机监控器(VMM)
- SR-IOV 定义了两种函数类型:
- PF:完整的 PCIe 功能,包含 SR-IOV 扩展能力,用于管理和配置虚拟功能。
- VFs:轻量级的 PCIe 功能,包含仅用于数据传输的最小配置资源。
- SR-IOV 引入了一个新的软件实体:单根 PCI 配置管理器(Single Root PCI Configuration Manager, SR-PCIM 或 PCIM)。
- PCIM 负责管理和配置 VFs,处理所有对配置空间的访问请求。
- 它基于物理函数的信息,向虚拟机中的客户操作系统呈现完整的 PCI 配置模型。
- PCIM 是一个概念模型,具体实现由各 VMM 厂商负责集成。
- Linux 内核自 2.6.30 版本(2009 年 6 月)开始支持 SR-IOV,多个发行版均已集成。
虚拟功能(VF)创建
- 在设备上电后,VFs 默认不存在,也无法访问其配置空间。
- VFs 必须通过物理函数上的 SR-IOV 功能配置和启用后才能访问。
- 物理函数的 PCI 配置空间内有 SR-IOV 能力结构,其中包含一个 系统页大小字段(System Page Size),由 VMM 设定为平台支持的大小。
- 所有 VF 的内存空间被连续映射在由 VF 基址寄存器(VF Base Address Register)指定的内存范围内。
- 为确保内存空间隔离,VF 的内存资源必须对齐到系统提供的页保护边界。
- ARI(替代路由 ID 解释)能力标志会影响最大 VF 数量的分布,VMM 应启用根端口和交换机上的 ARI,并在 SR-IOV 能力中设置 ARI 能力层级位。BIOS 可能已预先启用 ARI。
VF 发现
- 设置 VF 启用字段后,VFs 被创建并响应配置事务。
- 旧有的枚举软件不会自动发现这些 VF。
- SR-IOV 引入一种新机制:通过物理函数中的 First VF Offset 和 VF Stride 字段形成链表,软件可定位与该物理函数关联的所有 VF。
- SR-IOV 设备可能要求软件分配多个 PCI 总线号以支持超过 256 个功能。
VF 驱动与物理函数驱动通信支持
- VMM 可以支持创建共享内存页,促进虚拟机中的 VF 驱动与主驱动(Master Driver)之间的通信(详细内容在第 6 节)。
VF 分配给虚拟机
- VFs 创建配置后,可被分配给虚拟机,实现虚拟机与硬件设备的直接 I/O 交互。
- SR-IOV 设计假定设备上的所有 VF 是相同的,PCI 配置中均呈现相同的功能。
- 但通过主驱动介入分配,硬件可以根据系统管理员需求,提供不同的功能特性或性能等级(例如,为某些 VF 提供 2Gbps 的以太网性能保证)。
总结
- BIOS 需要支持 SR-IOV 设备的识别和资源分配,尤其是 MMIO 和总线号管理。
- VMM 引入 PCIM 模型管理 VFs,负责配置访问透明化和虚拟化资源管理。
- VF 需要显式创建和启用,且支持大规模虚拟化场景(成百上千 VF)。
- SR-IOV 支持高性能、低延迟的 I/O 直通,同时具备灵活的资源分配和管理能力。
主驱动程序(MD, Master Driver)
主驱动(Master Driver,简称 MD;也称为物理功能驱动 PFD 或 PF Driver)是一个专门的驱动程序,用于管理 SR-IOV 设备的全局功能,并负责配置共享资源。MD 是特定于虚拟机监控器(VMM)的,运行在比一般虚拟机驱动更高权限的环境中。它包含了传统驱动的全部功能,以便 VMM 访问 I/O 资源;同时它还能执行影响整个设备的操作。
MD 必须在一个持续存在的环境中运行,在任何虚拟机驱动加载之前加载,并在所有虚拟机驱动卸载之后才能卸载。所有会影响整个设备的操作只能被 MD 接收和处理。
为了实现这种控制能力,虚拟机中的 VF 驱动需要与 MD 通信。比如,以太网设备的链路状态变化或最大传输单元(MTU)改变,就需要这种通信机制。VF 驱动通过通信通道询问链路状态时,MD 可以返回任意状态。当物理设备的 MTU 发生改变时,MD 可通知所有 VF 驱动,以便网络栈作出相应调整。
VF Drivers
VF 是“轻量级”的 PCIe 功能,只包含执行数据传输所必需的资源,它并不是一个完整的 PCIe 设备,仅提供数据进出机制。
VF 驱动运行于虚拟机中,应为半虚拟化驱动(即意识到它在虚拟化环境中),只能执行其允许的操作。通常,VF 具备发送/接收数据和执行自身复位的能力。该复位操作仅影响该 VF,而不会影响整个物理设备。超出其权限范围的操作需通过与 MD 通信实现。
VF 驱动是一个专门化驱动,它“知道”自身只能执行特定的功能,如配置 DMA 描述符、设置 MAC 地址、VLAN 标签等。每个 VF 都有在 I/O 设备中分配的独立资源。以太网 VF 通常具备独立的发送/接收队列,绑定到对应的 BAR(基地址寄存器)及描述符。
VF 驱动与主驱动的通信
设备共享的关键在于 VF 驱动能够与 MD 通信,请求那些影响全局的操作。这个通信通道需要传递消息并能生成中断。
SR-IOV 并未定义这一通信机制,因此需由主驱动、物理功能驱动和 VMM 设计者共同构建。最简单的方式是使用 VF 专属的设备内邮箱(mailbox)和门铃(doorbell)机制(Intel SR-IOV 网络控制器支持该方式)。目前,各家 VMM 厂商正在实现各自的通信机制,尚未形成统一标准。
workflow 示例
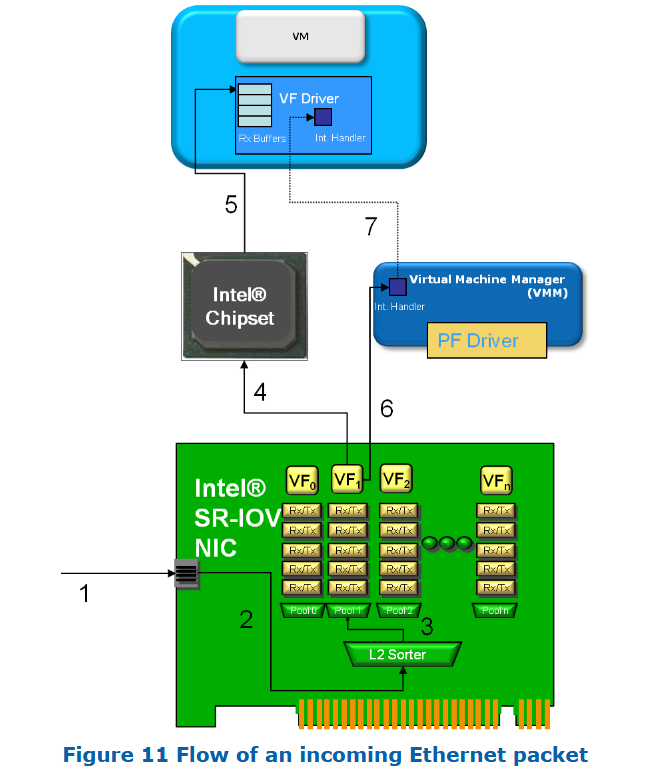
以下是一个接收以太网数据包并通过 VF 转发到虚拟机的典型流程:
- 数据包到达 Intel® 网卡。
- 包被送入由主驱动配置的二层分类器(Layer 2 sorter)。
- 分类后,数据包进入目标 VF 的接收队列。
- 启动 DMA 操作,其目标地址由 VF 驱动配置的描述符决定。
- DMA 到达芯片组。VMM 配置的 Intel® VT-d 将虚拟地址映射为主机物理地址,完成 DMA。
- NIC 发出中断,VMM 捕获。
- VMM 发出虚拟中断通知 VM 数据到达
总结
平台必须支持地址转换(如 Intel® VT-d),才能使设备将数据 DMA 直接写入 VM 的内存。
BIOS 和 VMM 需能解析 PCI 配置空间,尤其是 SR-IOV 的 VF 定位机制。
VMM、PF 驱动、VF 驱动三者必须配合,为 VM 提供完整的 PCI 空间映射和 VF 操作能力。
相关技术
PCIe
PCI(Perpheral Component Interconnect)
PCI曾经是个人电脑中使用最为广泛的接口,几乎所有的主板产品上都带有这种插槽。目前该总线已经逐渐被PCI Express总线所取代。PCI总线是由ISA(Industy Standard Architecture)总线发展而来的,是一种同步的独立于处理器的32位或64位局部总线。从结构上看,PCI是在CPU的供应商和原来的系统总线之间插入的一级总线,具体由一个桥接电路实现对这一层的管理,并实现上下之间的接口以协调数据的传送。
**注:**ISA并行总线有8位和16位两种模式,时钟频率为8MHz,工作频率为33MHz/66MHz。
PCI总线是一种树型结构,并且独立于CPU总线,可以和CPU总线并行操作。PCI总线上可以挂接PCI设备和PCI桥,PCI总线上只允许有一个PCI主设备(同一时刻),其他的均为PCI 从设备,而且读写操作只能在主从设备之间进行,从设备之间的数据交换需要通过主设备中转。
**注:**这并不意味着所有的读写操作都需要通过北桥中转,因为PCI总线上的主设备和从设备属性是可以变化的。比如Ethernet和SCSI需要传输数据,可以通过一种叫做Peer-to-Peer的方式来完成,此时Ethernet或者SCSI则作为主机,其它的设备则为从机。
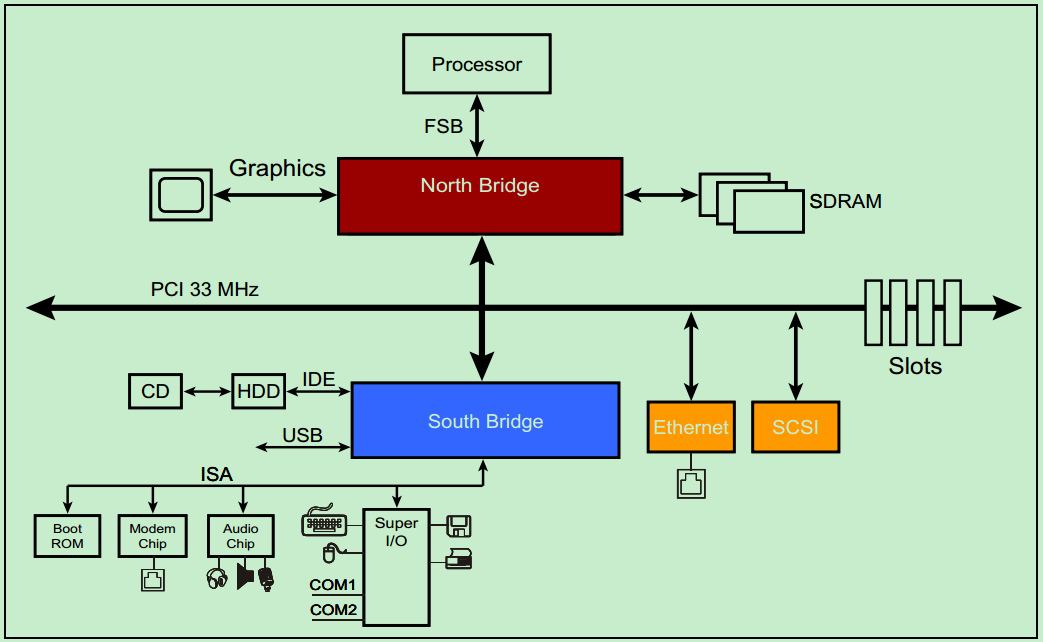
一个典型的33MHz的PCI总线系统如上图所示,处理器通过FSB(Front Side Bus,前端总线,是早期计算机体系结构中,处理器(CPU)与北桥芯片之间通信的主要总线,用于连接 CPU 和内存控制器、显卡、PCI 总线等系统核心组件)与北桥相连接,北桥上挂载着图形加速器(显卡)、SDRAM(内存)和PCI总线。PCI总线上挂载着南桥、以太网、SCSI总线(一种老式的小型机总线)和若干个PCI插槽。CD和硬盘则通过IDE连接至南桥,音频设备以及打印机、鼠标和键盘等也连接至南桥,此外南桥还提供若干的USB接口。
PCI总线是一种共享总线,所以需要特定的仲裁器(Arbiter)来决定当前时刻的总线的控制权。一般该仲裁器位于北桥中,而仲裁器(主机)则通过一对引脚,REQ#(request) 和GNT# (grant)来与各个从机连接。如下图所示:
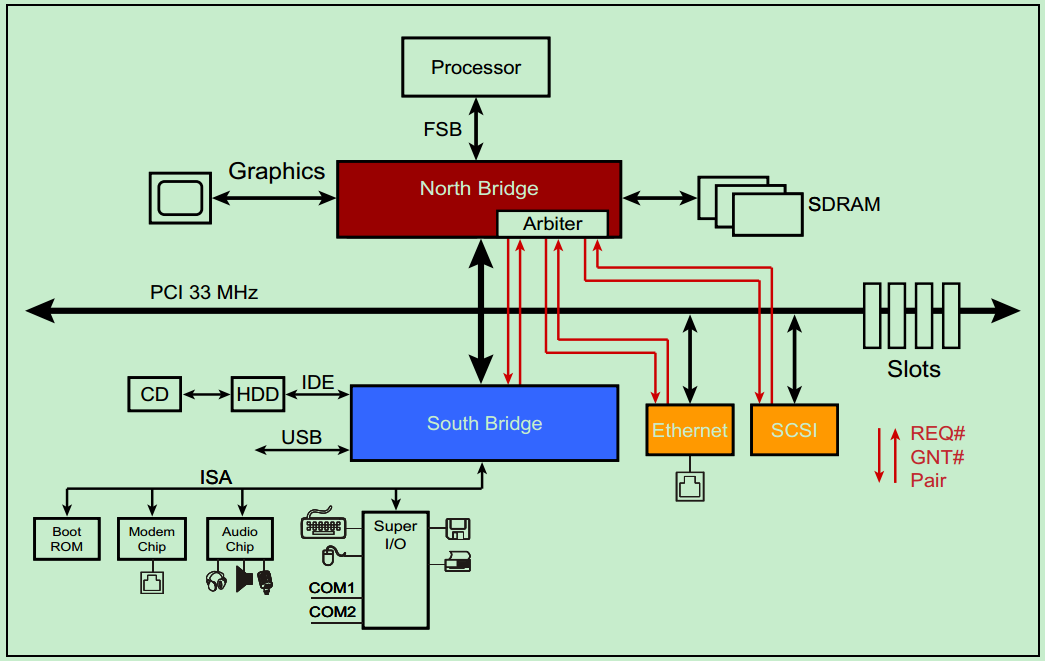
需要注意的是,并不是所有的设备都有能力成为仲裁器(Arbiter)或者initiator 。
最初的PCI总线的时钟频率为33MHz,但是随着版本的更新,时钟频率也逐渐的提高。但是由于PCI采用的是一种Reflected-Wave Signaling信号模型,导致了时钟频率越高,总线的最大负载越少。