ARM SMMUv3
时间轴
2025-10-30
init
参考文档:

技术手册:
- System Memory Management Unit Architecture Specification, SMMU architecture version 3
- MMU-600 System Memory Mangement Unit, Technical Reference Manual
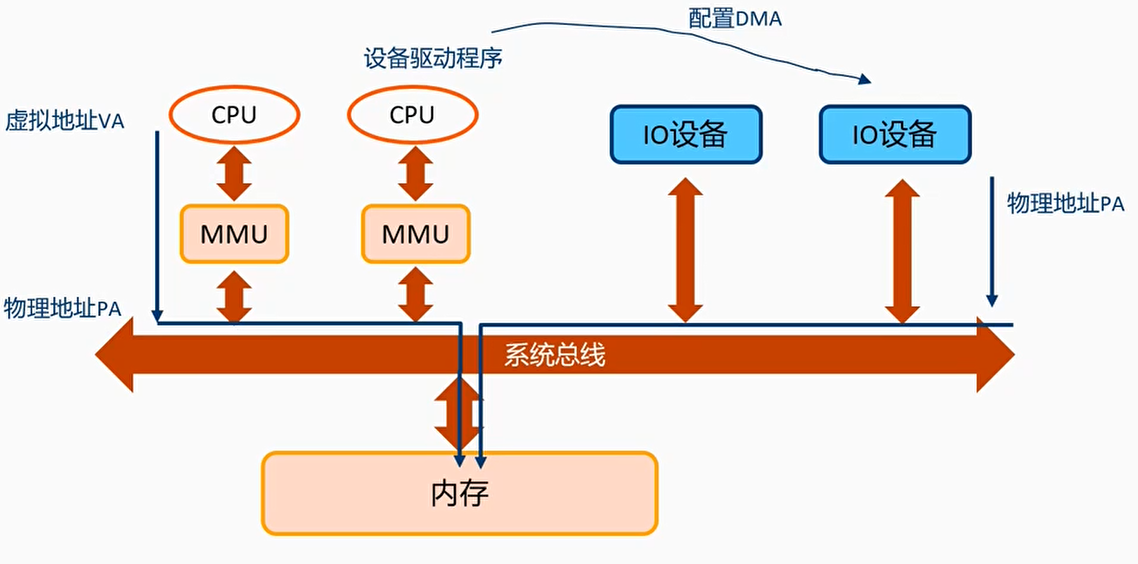
什么是SMMU/IOMMU
- SMMU是ARM公司实现的IOMMU(Input/Output Memory Management Unit),把设备访问的虚拟地址转换成物理地址
- AMD公司IOMMU
- Intel VD-T
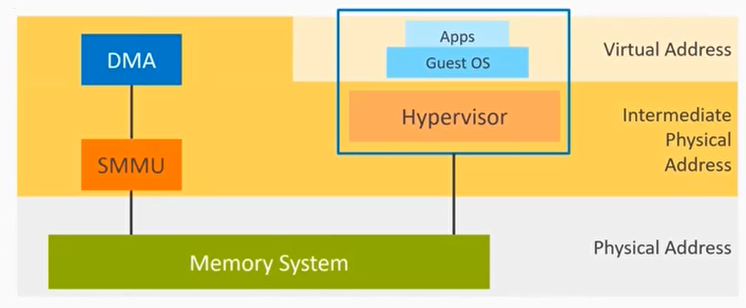
Bare-mental OS场景
IO设备的DMA访问可能会有问题:
- IO设备得到的是物理地址,它可以访问所有的内存地址。所以DMA可以破坏其他的设备或者系统内存,例如恶意的IO设备。
- 对设备驱动程序也没有做保护,例如恶意的驱动程序
- IO设备与IO设备之间容易泄露信息:Side channel attack
虚拟化场景
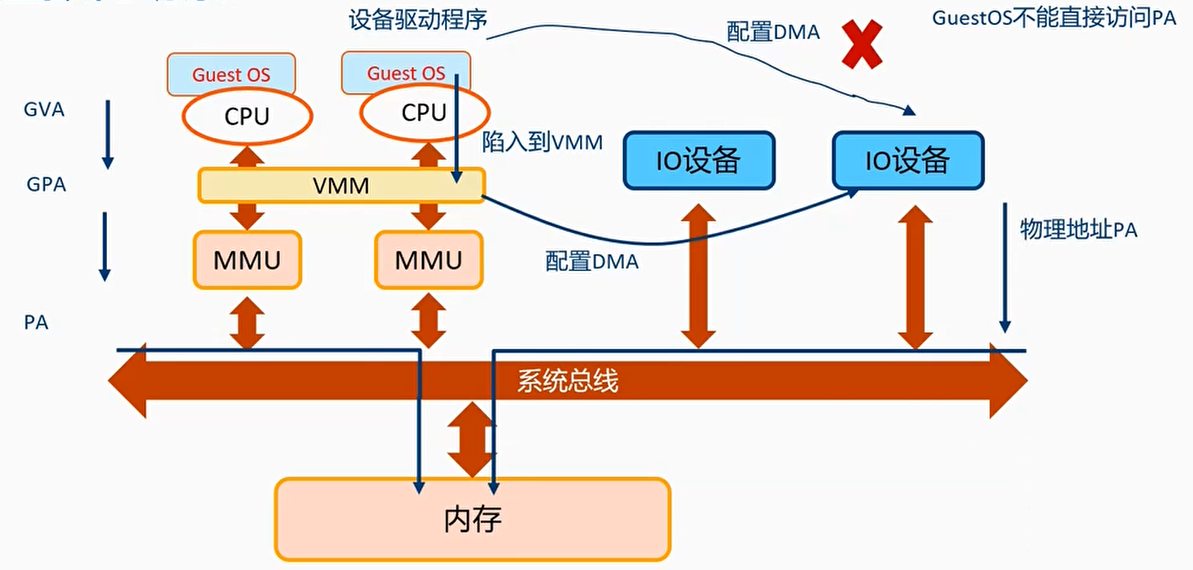
缺点:
每次DMA操作都需要陷入到VMM,来分配物理内存for IO设备,会有性能损失(约20~30%)
解决方案:SMMU
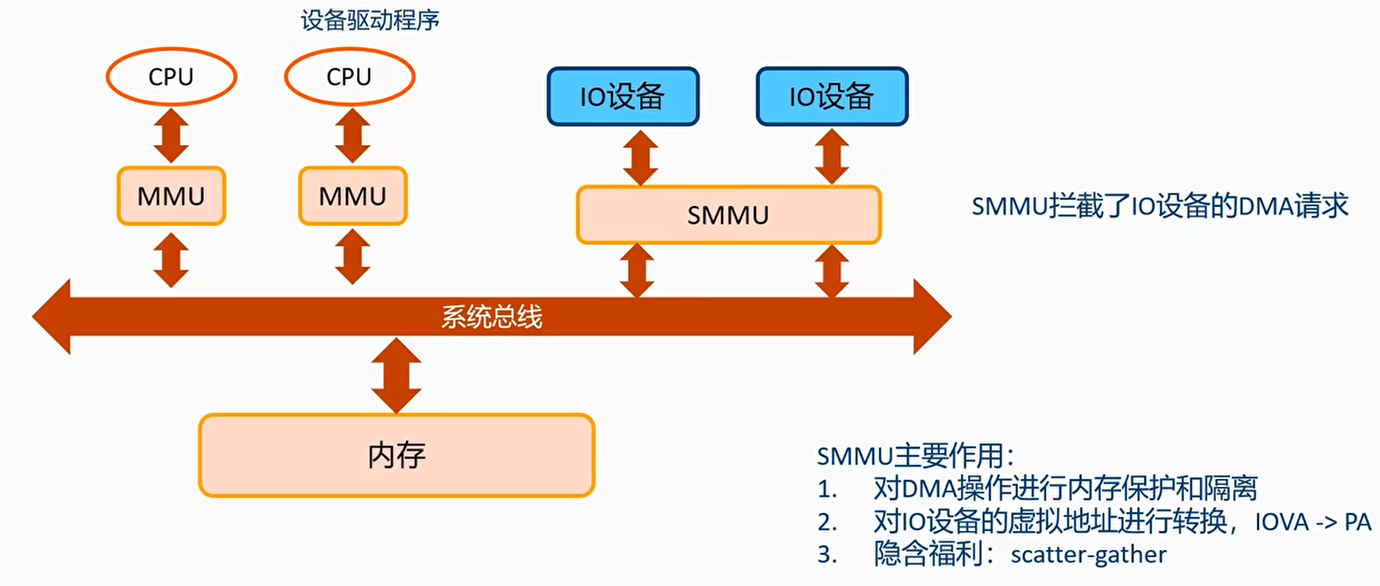
每个IO设备有自己的页表
scatter-gather表示IO设备可以使用一段连续的虚拟地址,但最终翻译的物理地址不一定需要连续
SMMU发展历史

SMMU的使用
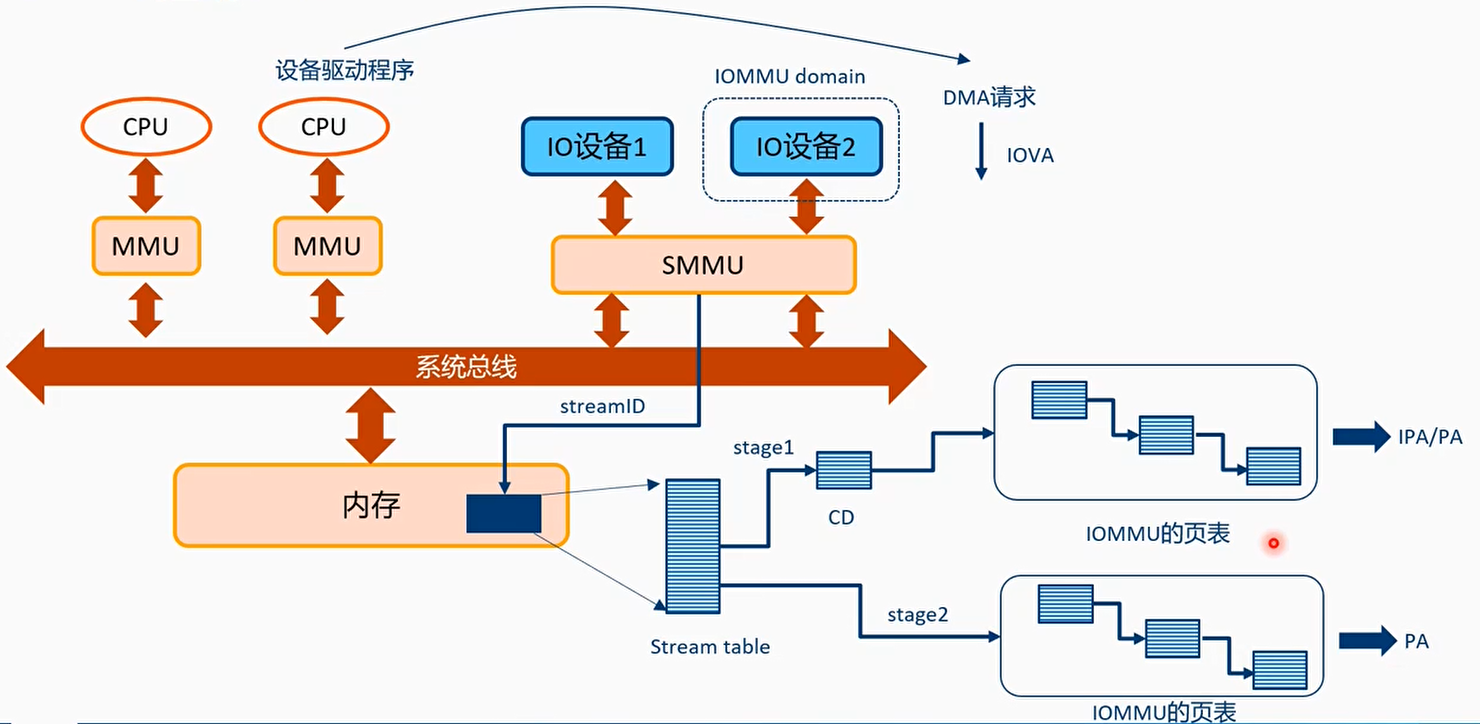
CPU访问设备,使用MMU即可,设备访问Memory需要经过SMMU
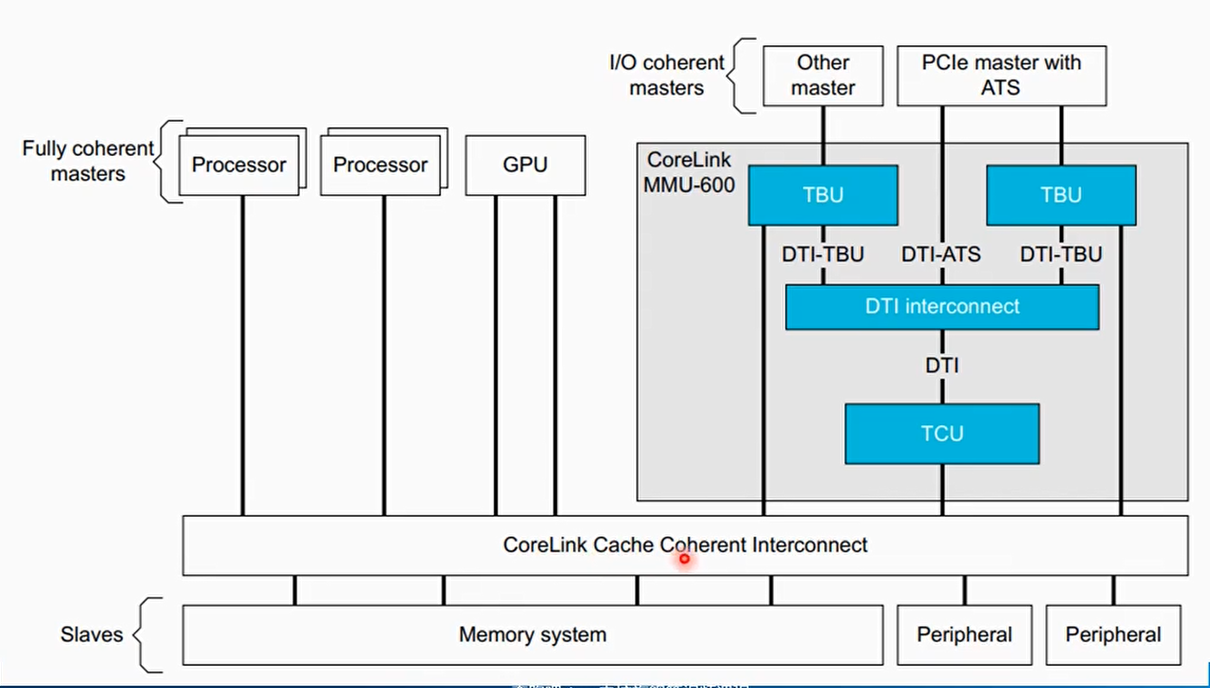
MMU-600控制器
- SMMUv3是spec,MMU-600是基于SMMUv3.1规范实现的控制器
- MMU-600转换设备IOVA到PA,支持2阶段的地址转换或者Bypass模式
- Stage1:转换IOVA->PA或者IOVA->IPA
- Stage2:IPA->PA
- Both: IOVA->IPA->PA
- Bypass 模式(略过SMMU)
- 特性
- 兼容SMMUv3.1
- 支持ARMv8的AArch32和AArch64的页表格式
- 支持4KB,16KB,64KB页
- 支持PCIe,支持ATS和PASIDs
- 支持RPI(Page Request Interface)
- 支持ACE5-Lite原子操作
- 支持translation fault,软件可以实现请求调页
- 支持GICv3集成,支持message-based中断
MMU-600框图
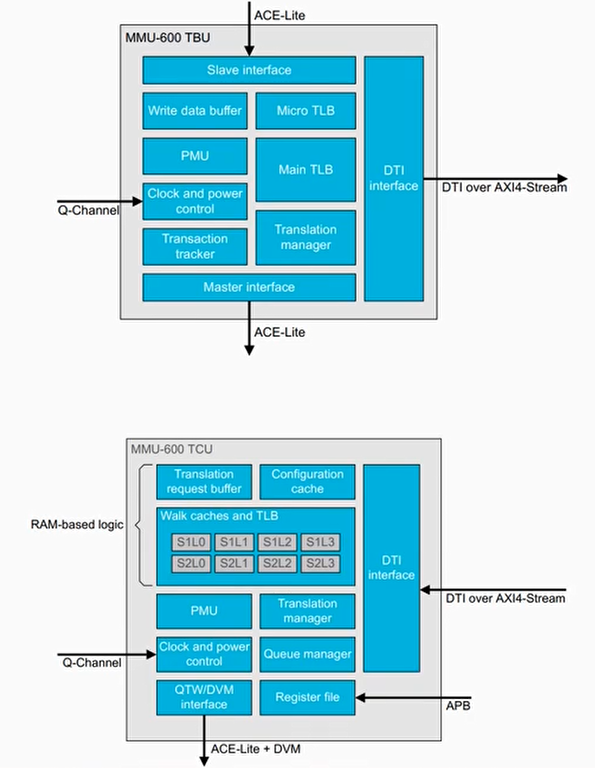
MMU-600内部组成
- TBU (Translation Buffer Unit)
- 包含TLB用来缓存转换结果
- 每个连接的Master至少有一个TBU
- 如果TBU没有找到TLB表项,那么发送请求给TCU
- TCU(Translation Control Unit)
- 进行地址转换的硬件单元
- MMU-600只有一个TCU
- 管理内存请求
- 遍历页表
- 执行配置页表
- Implements backup caching structures
- SMMU编程接口
- DTI
- 用来连接TBU到TCU
- 使用AXI Stream协议
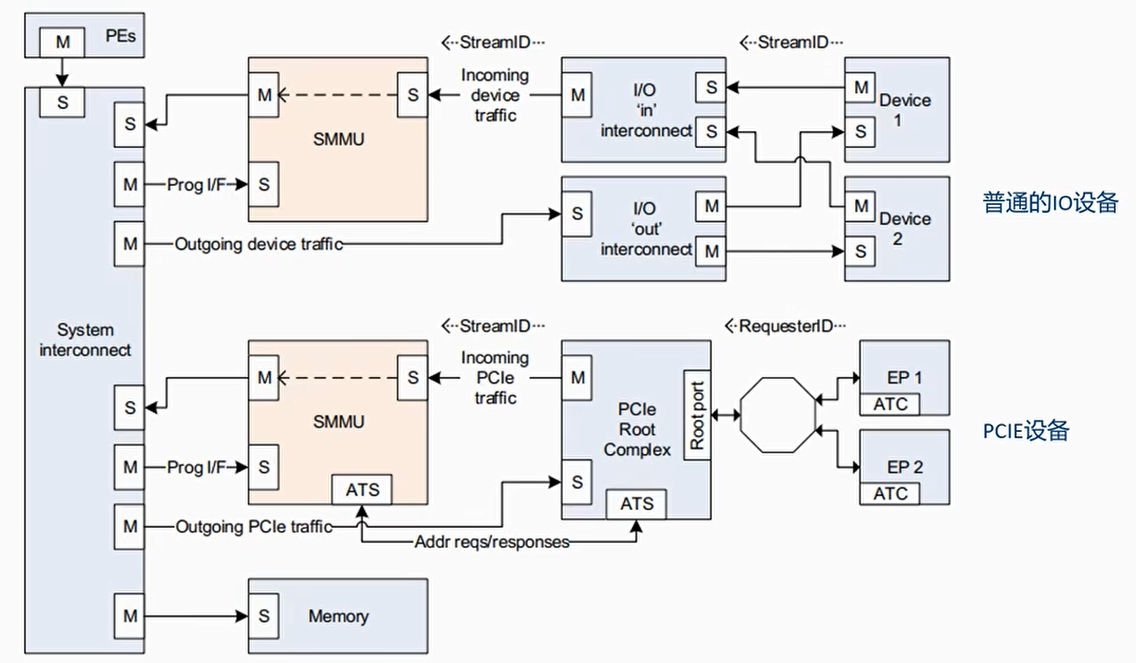
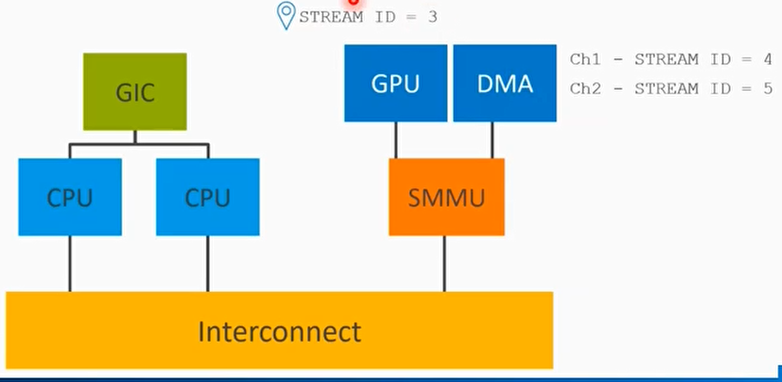
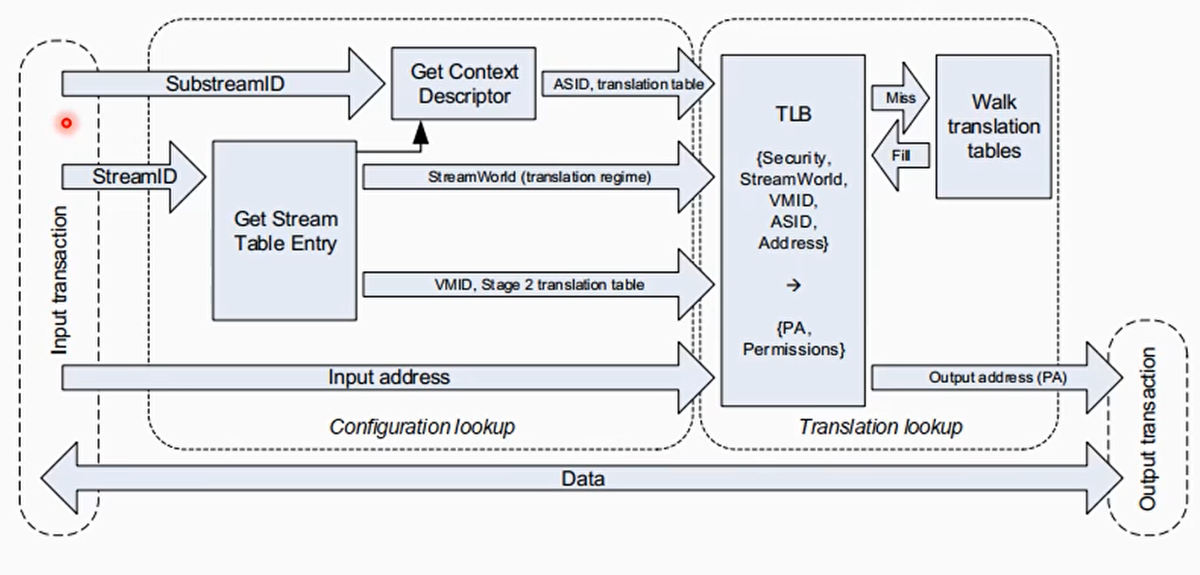
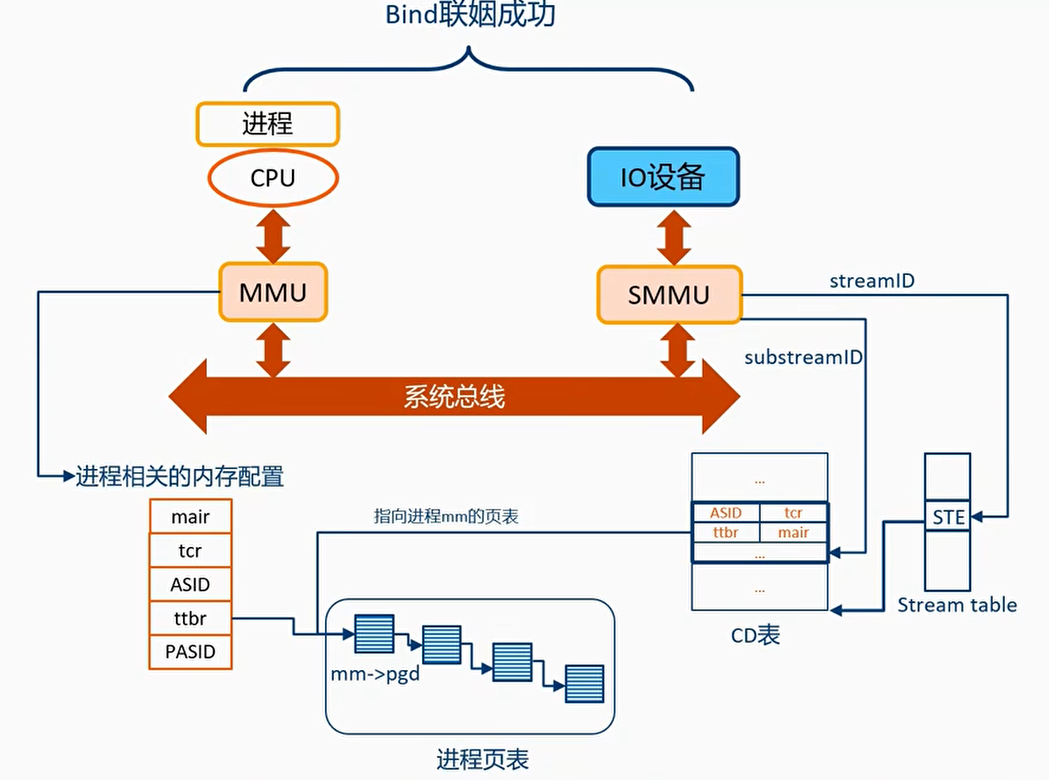
StreamID
- 一次DMA传输包括:目标地址,大小,读写属性,安全属性,共享属性,缓存属性,以及StreamID
- StreamID用来关联一个设备(function)
- StreamID用来索引Stream Table,Stream Table包含per-SMMU相关的页表信息
- 对于PCIe设备,StreamID[15:0]==RequesterID[15:0]等于BDF
- Bits[15:8] Bus number
- Bits[7:3] Device number
- Bits[2:0] Function number
- 对于非PCIe设备,通过DTS来获取StreamID(因此streamID是定死的)
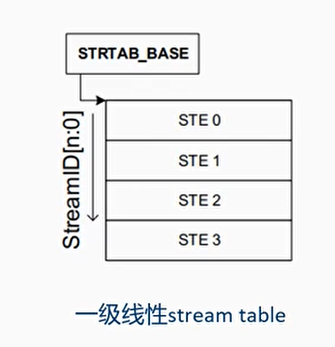
遍历Stream Table
- Stream Table中的每个表项STE包含了:
- Stage2转换的页表基地址
- 指向一个Context Descriptors,里面包含了stage1的转换页表基地址
- 使用StreamID来索引Stream Table
- Stream Table需要OS软件来创建和填充
- STE(Stream Table Entry)数量大于64,必须使用2级表
- streamID[n:x]索引第一级表,streamID[x-1:0]索引第二级表
- N表示streamID的最高位,通常为15
- X是split点,STRTAB_BASE_CFG.SPLIT
- 例如:n=15,x=8,那么StreamID[15:8]索引第一级表,StreamID[7:0]索引第二级表
二级表例子
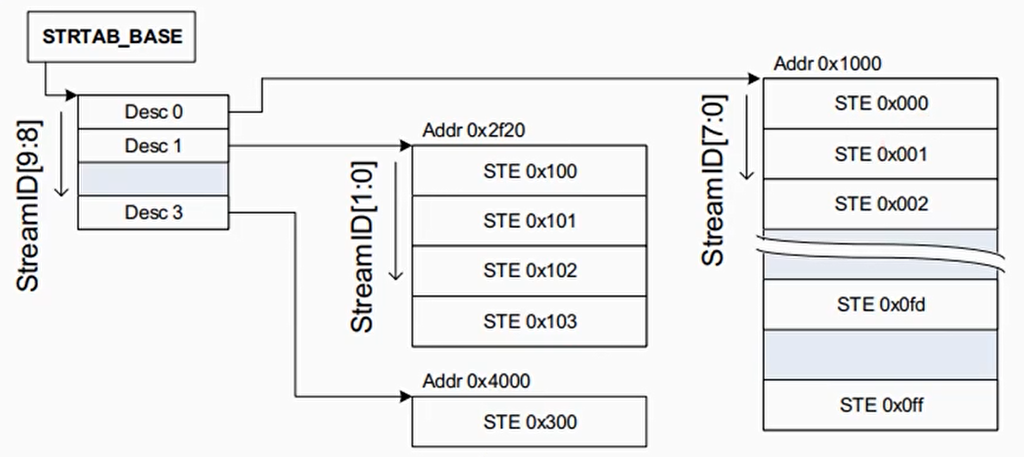
假设StreamID只有10位,即StreamID[9:0],假设x为8,那么使用StreamID[9:8]来索引第一级表,使用StreamID[7:0]来索引第二级表
一级表有4个表项,每个二级表有256个表项
StreamID共10bit,2^10次方是1024,也就说最多索引0~1023个STE
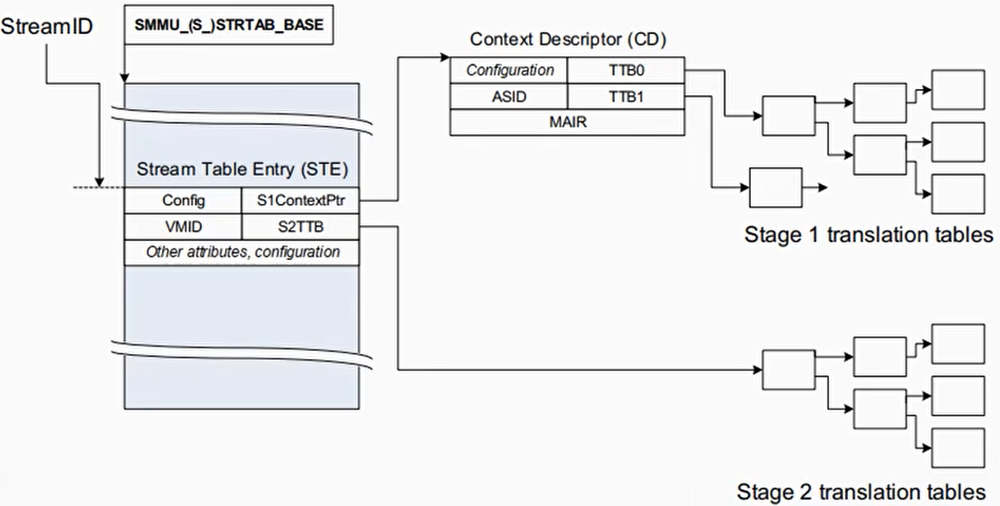
Context Descriptors表
-
CD包含stage1的页表基地址,ASID,页表属性等
-
STE中的S1ContexPtr指向CD
-
Stage2的页表基地址是在STE
-
软件管理:
- 虚拟化:Hypervisor管理Stream Table和stage 2页表,Guest OS管理CD和stage1页表
- Bare-metal OS管理Stream Table和CD

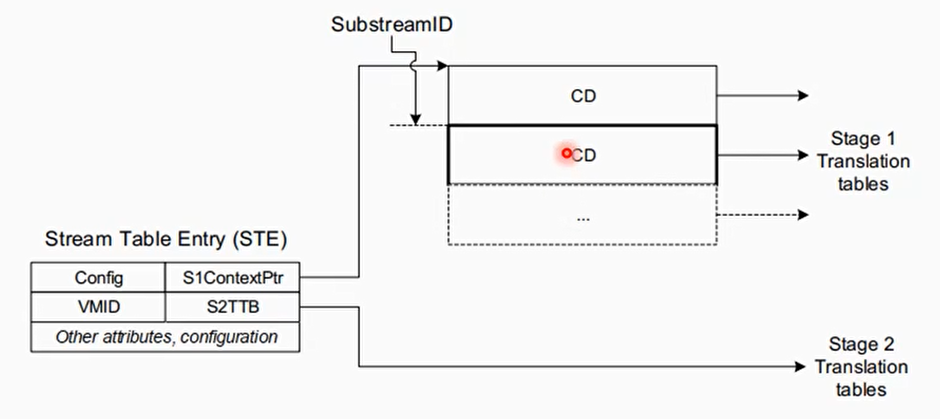
SubstreamID
-
STE中的S1ContextPtr指向一个CD(Context Descriptor)表,SubstreamID用来索引这个表
-
每个CD里都包含了stage1中要用的页表基地址
-
一个设备可能被多个进程使用,SMMU通过substream id来进行区分,可以每个进程一个substreamID
-
对于PCIe设备,使用PASID作为SubstreamID
总结
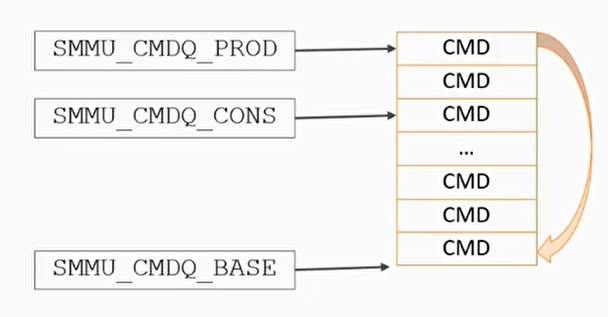
Command and Event queues
- command queue用于输入,event queue用于输出。每个queue都有生产者和消费者
- 输出队列包含由SMMU产生的数据,然后由软件来消费。输入queue是由软件产生数据,然后SMMU来消费
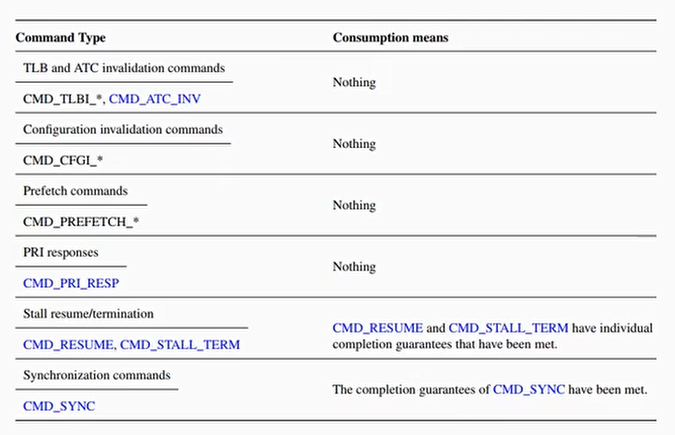
具体每个CMD描述,见SMMUv3手册第四章
Linux IOMMU驱动框架
IOMMU驱动两大作用:
- 为IO设备提供DMA接口和功能
- 为IO设备提供SVA功能(Shared Virtual Addressing),把IO的设备和某个进程共享虚拟地址空间
IOMMU包括:
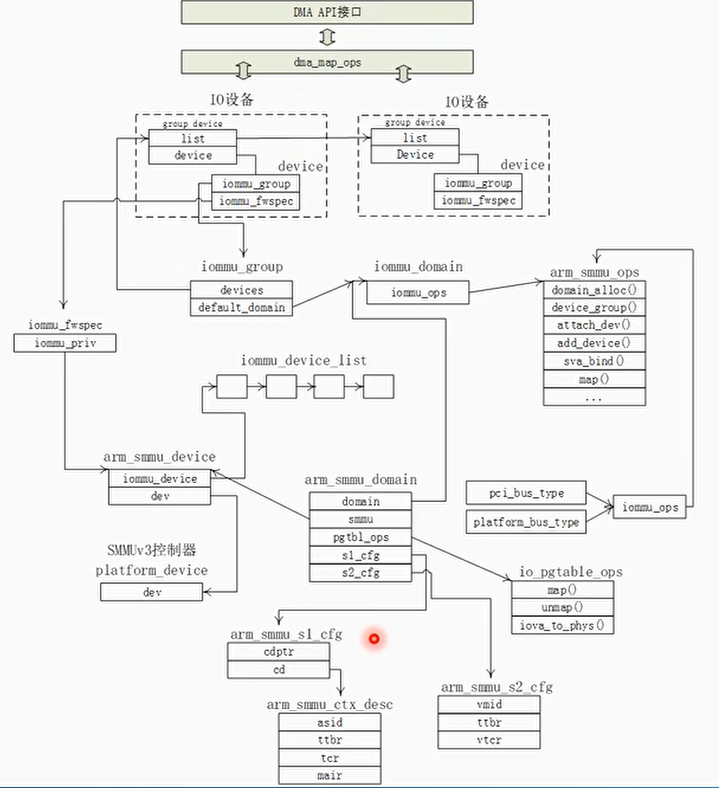
- IOMMU framework
- IOMMU 控制器驱动
- IOMMU dma-mapping
- IOMMU 提供给IO设备的接口
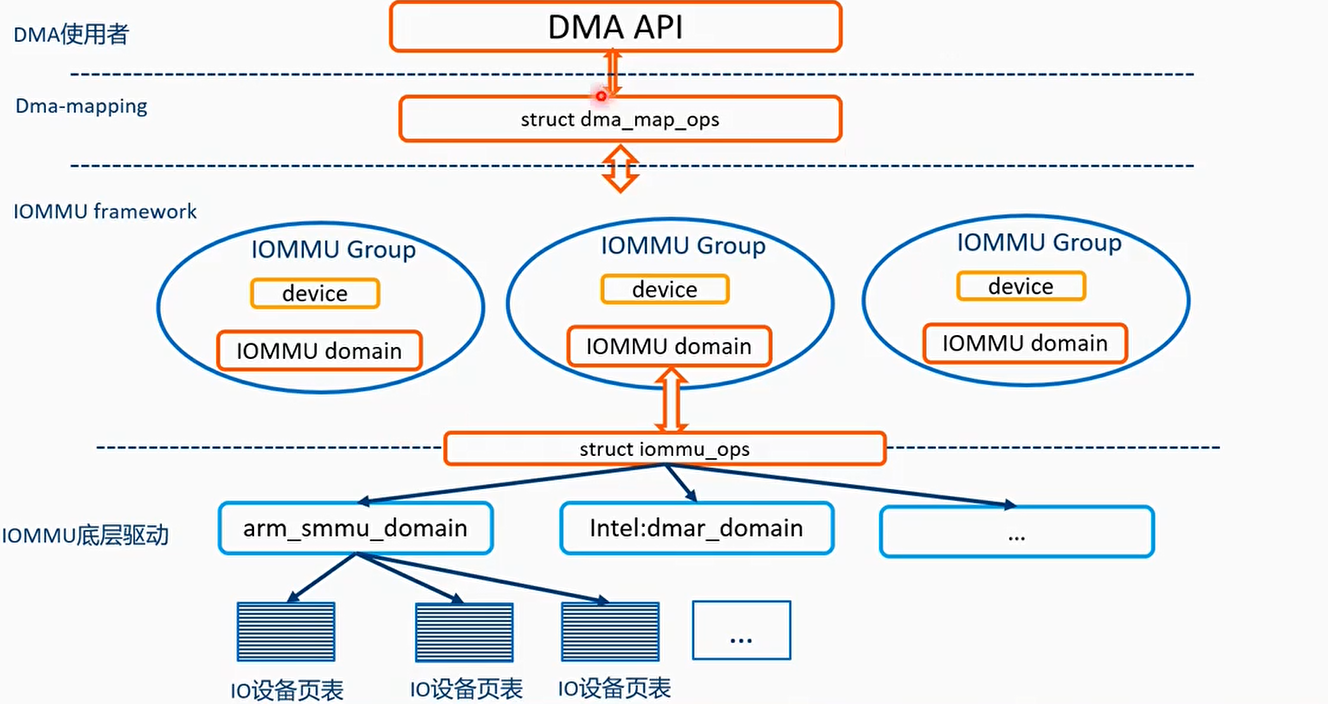
- IOMMU Domain主要是用来提供访问IOMMU控制器的能力
- iommu_group是最小资源隔离单元
- 一般一个设备占用一个iommu_group,基于某种硬件拓扑关系并且安全信任的多个设备或者点对点保护的传输设备,可以添加到一个iommu group
- 服务器系统可能由多个IOMMU控制器

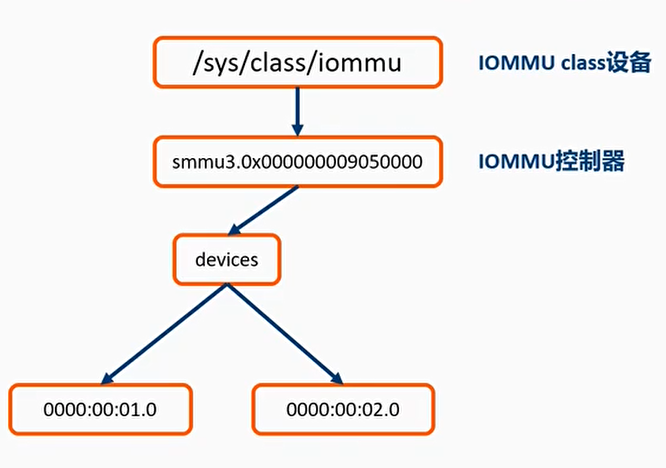
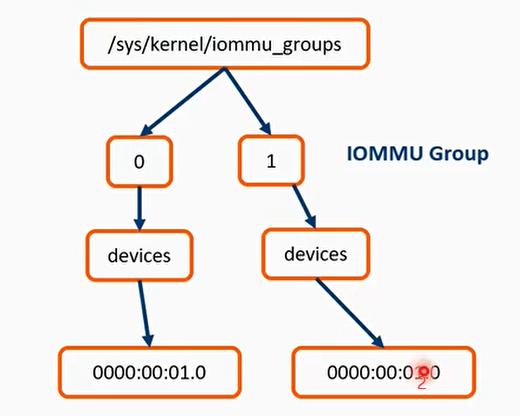
IOMMU domain与SMMU控制器之间的桥梁- iommu_ops
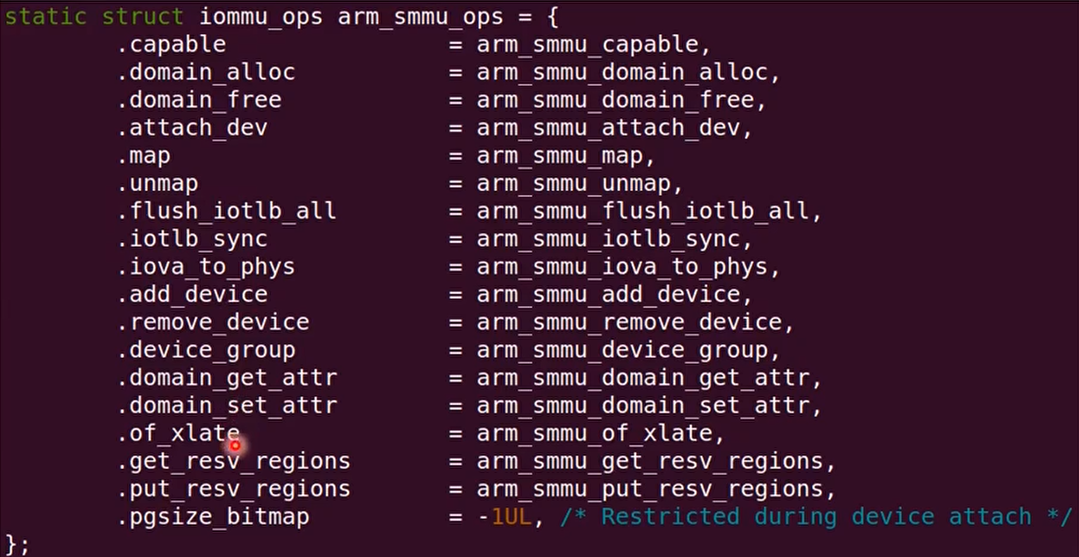
SMMU驱动:DMA
编写一个IOMMU的IO设备驱动
手动设置
- 分配一个IOMMU domain
1 | domain = iommu_domain_alloc() |
- 把设备dev加入到iommu domain里
1 | iommu_attach_device(domain, dev) |
- 建立映射
1 | iommu_map() |

自动设置
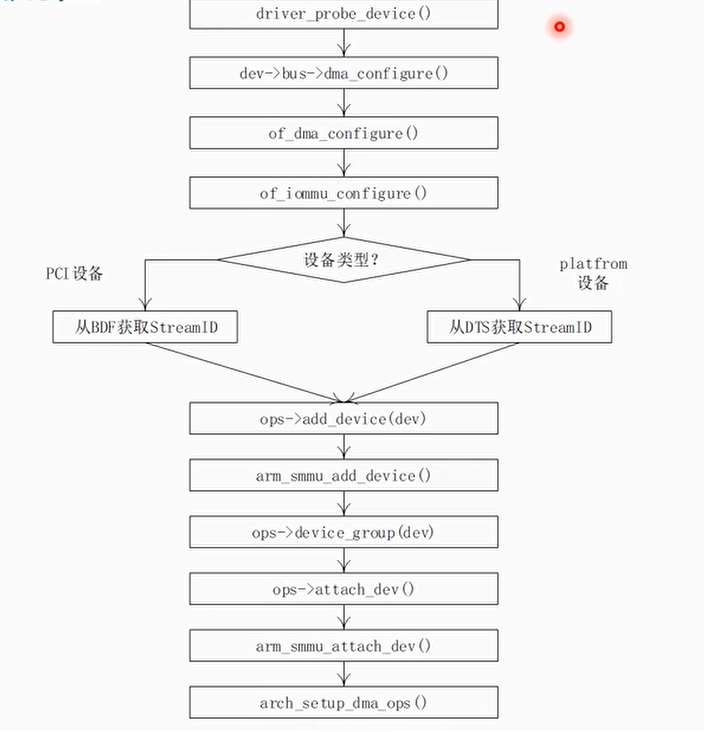
- 对于PCI设备或者Platform device,通过总线扫描的方式自动检测和初始化IOMMU
driver_probe_device()->
dev->bus->dma_configure(dev)->
platform_dma_configure()/pci_dma_configure()->
of_dma_configure()
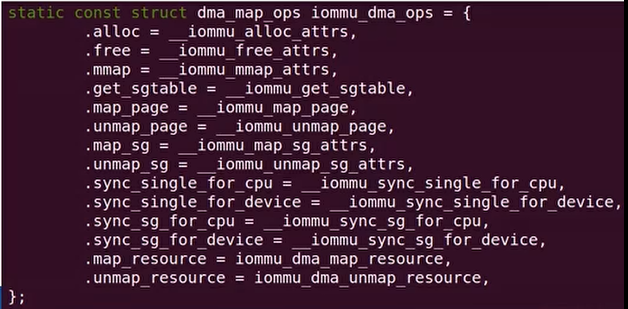
- 自动设置struct dma_map_ops *dma_ops为IOMMU的
对于PCI和platform device可以使用DMA API接口,例如dma_map_page()
of_dma_configure()->
arch_setup_dma_ops()->
dev->dma_ops = &iommu_dma_ops;
- arch/arm64/mm/dma-mapping.c
IO设备SMMU初始化流程
总结
SVA(Shared Virtual Addressing)
进程和设备之间共享进程地址空间
(以Linux5.15内核为参考)
为什么要SVA
传统的DMA模式
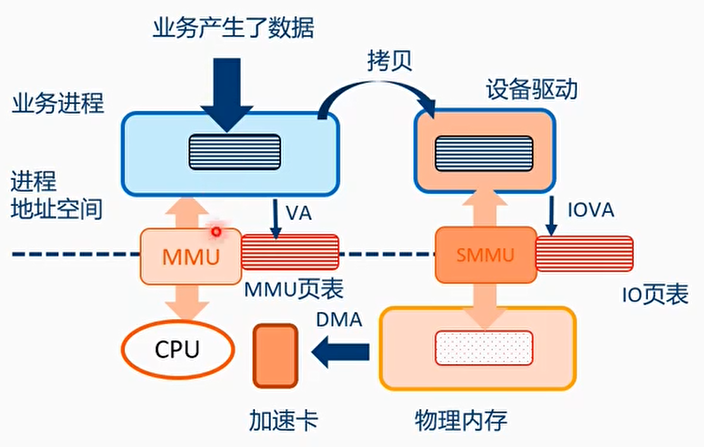
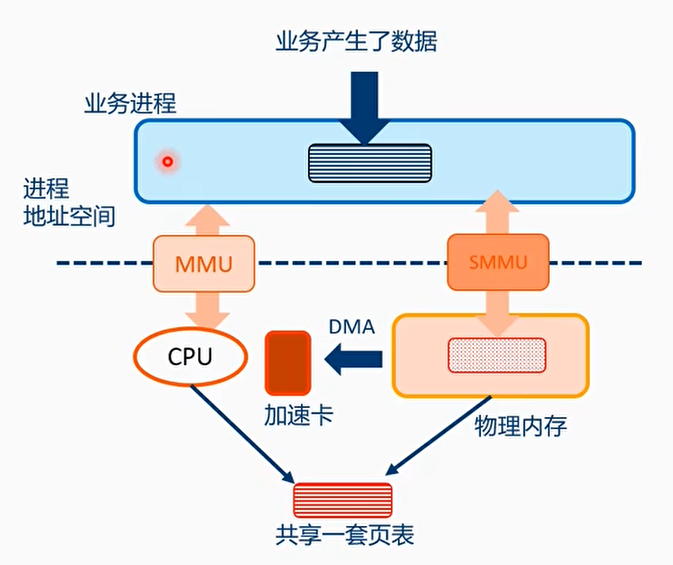
SVA模式
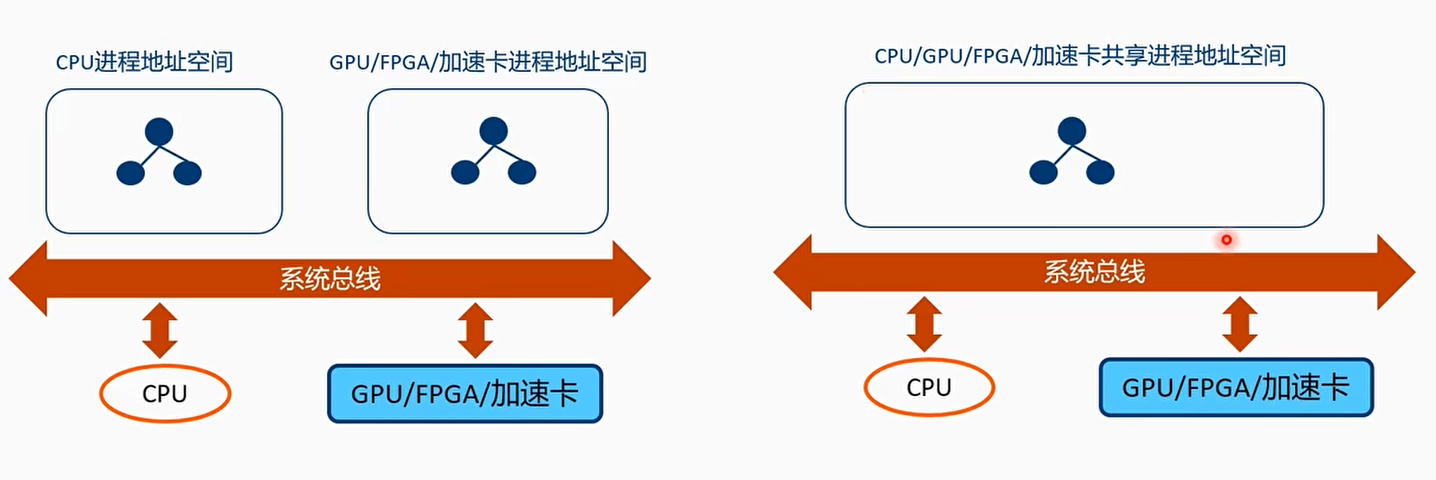
DMA模式下在CPU和GPU/FPGA/加速卡之间很难共享一些复杂度数据结构
Linxu SVA框架
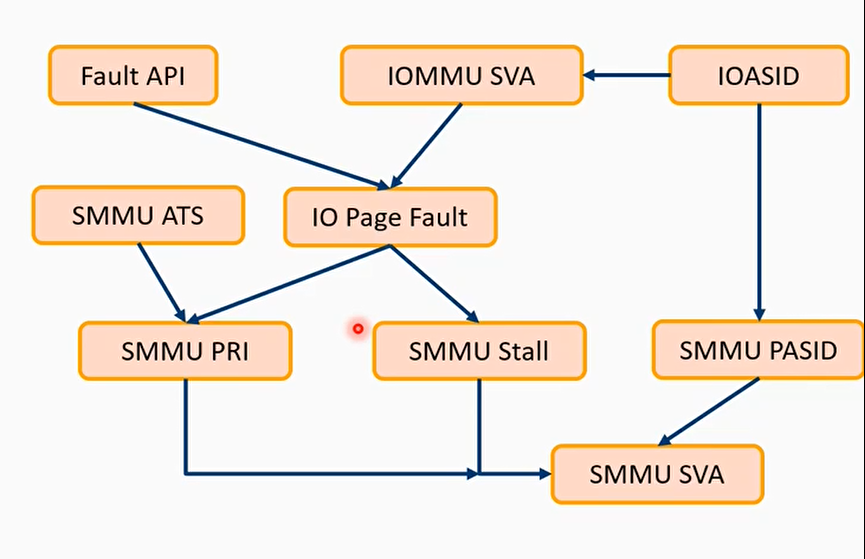
从驱动角度看新增哪些API接口

总结
IO缺页异常
- CPU侧的缺页异常,走CPU的缺页异常,handle_mm_fault
- 设备侧的缺页异常:
- PCIe设备:PRI扩展(Page Request Interface)
- 平台设备:利用SMMU的stall模式
- Stall模式:当IO设备触发异常时,传输事务被暂停,把这个事件记录在even queue里。OS软件需要处理,然后发送CMD_RESUME命令恢复传输事务。
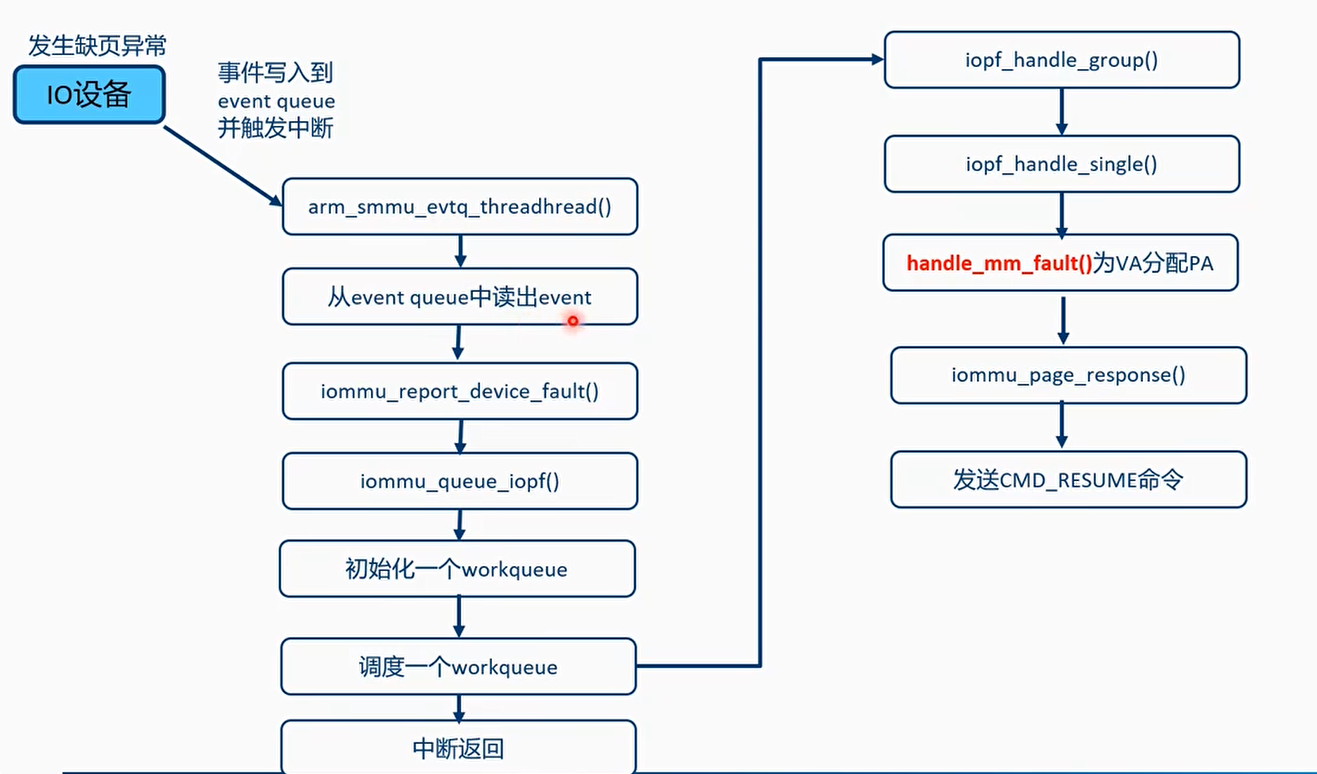
疑问:为什么这里IO设备侧发生缺页异常处理,调用CPU侧的handle_mm_fault()来建立VA->PA的页表项,那IO设备的页表呢?谁来建立?
SVA,共用一套页表
无效TLB操作
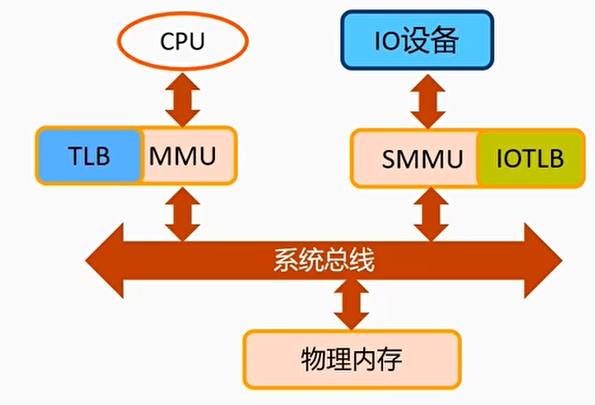
- 当CPU侧修改了mm,或者释放内存
- 调用flush_tlb()来无效CPU侧的TLB
- 通过mmu_notifier注册的回调函数来无效IO设备侧对应的IOTLB以及PCIe ATC的IOTLB

- IO设备有没有可能主动修改了VA->PA的映射关系?
- 非SVA情况下,通过iommu_map和iommu_umap接口来实现分配和释放DMA buffer。iommu_unmap()->iotlb_sync()
- SVA情况下,CPU侧分配的虚拟地址就可以当作IOVA。当IO设备触发缺页异常时,就直接走IO缺页异常处理流程。
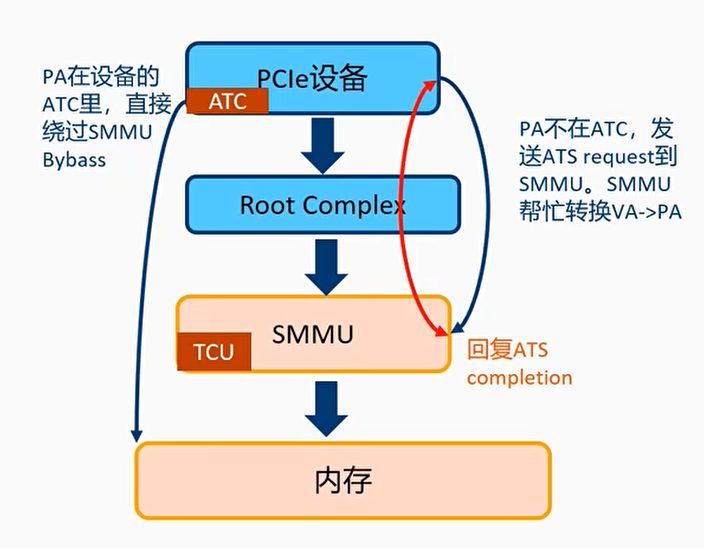
PCIe新增的ATS(Address Translation Services)
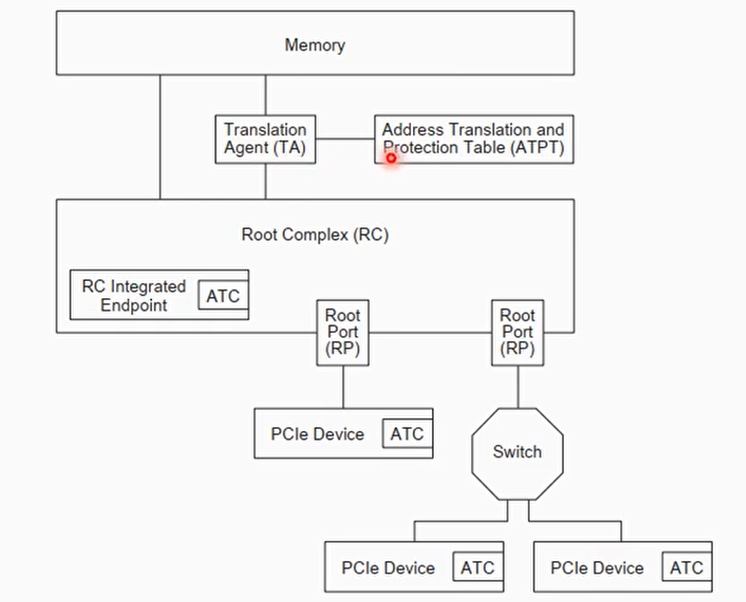
- PCIe中ATS机制:设备中缓存VA对应PA,设备使用pa做内存访问时无需经过IOMMU页表转换
- PCIe设备的ATC(Address Translation Cache)有自己的TLB
- 设备做DMA前,查询ATC是否有VA对应的entry
- 有:直接用PA访问内存
- 无:发送ATS request到SMMU,SMMU找到PA之后,回复ATS completion
- PCIe ATS规范定义了ATS request和completion message包的格式
- Address Translation Services Revision 1.1
- SMMU驱动:
- Enable ATS
- ATS invalidation操作。当SMMU改变了VA->PA时,SMMU需要发送ATS invalidation request到PCIe的ATC
- SMMU提供CMD_ATC_INV命令
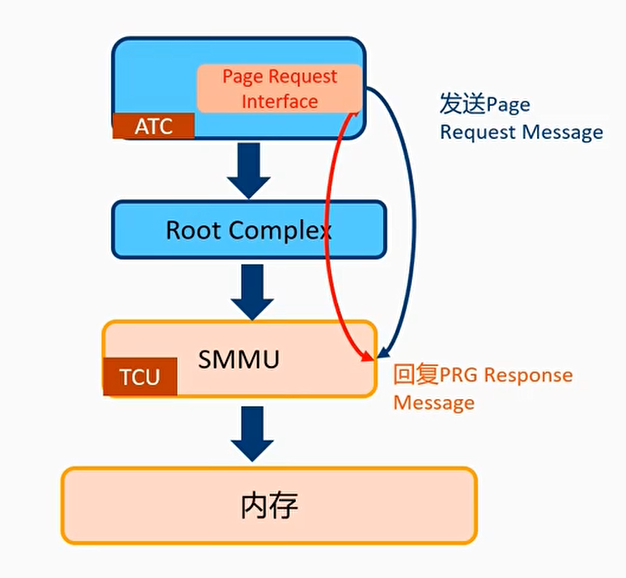
PRI(Page Request Interface)支持
- PRI机制的好处是在准备发起DMA操作的时候,不需要提前把DMA Buffer准备好(pinned)
- 使用场景:高速网卡,在burst情况下,Host不需要提前预留和占用大量的buffer
- PRI机制:
- 当ATC查找TLB miss,发送Page Request Message
- RC把message发送到SMMU
- SMMU缺页请求写入PRI queue,触发PRI中断
- OS软件申请物理内存
- OS软件回复CMD_PRI_RESP命令