ARM Memory Ordering and Memory Barrier
时间轴
2025-10-26
init
参考文档:

ARMv8.6 芯片手册
- B2.3.7 章 Memory barriers
- Appendix K11 Barrier Litmus Tests
内存屏障产生的原因
ARMv8 架构采用弱排序的内存模型。一般来说,这意味着内存访问的顺序不需要与加载和存储操作的程序顺序相同。处理器能够相对于彼此重新排序内存读取操作。写入也可以重新排序(例如,写入组合)。因此,硬件优化(例如缓存和写入缓冲区的使用)以提高处理器性能的方式起作用,这意味着所需的带宽可以减少处理器和外部存储器之间的延迟,并且隐藏与此类外部存储器访问相关的长延迟。
对普通内存的读取和写入可以由硬件重新排序,仅受数据依赖性和显式内存屏障指令的影响。某些情况需要更严格的排序规则。
- 处理器采用超标量技术:乱序发射,乱序执行,提高指令并行进度
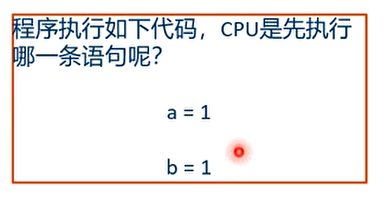
这两条语句先后顺序都有可能,因为没有依赖关系。
内存一致性模型(memory consistency model)
- 原子一致性(atomic consistency)内存模型
- 顺序一致性(sequential consistency)内存模型
- 处理器一致性(processor consistency)内存模型
- 弱一致性(weak consistency)内存模型
编译乱序
弱一致性内存模型
- 1986 年,Dubois 等发表的论文描述了弱一致性内存模型的定义
- 弱一致性内存模型要求同步访问(访问全局同步变量)是顺序一致的,在一个同步访问可以执行之前,之前的所有数据访问必须完成
- 在一个正常的数据访问可以执行之前,所有之前的同步访问必须完成
- 处理器使用内存屏障指令来实现整个同步访问的功能
- 内存屏障指令的基本原则如下:
- 所有在内存屏障指令之前的数据访问必须在内存屏障指令之前完成。
- 所有在内存屏障指令后面的数据访问必须等待内存屏障指令执行完。
- 多条内存屏障指令是按顺序执行的
- 处理器会根据内存屏障的作用范围进行细分
例子

会,因为 CPU0 可能会先执行 b=1

ARMv8 的内存模型
在normal memory实现的是弱一致性的内存模型(weak ordering model)
在device memory实现的是强一致性的内存模型(strong ordering model)
访存的序列可能和代码中的序列不一致
ARMv8 架构支持预测式的访问(speculative accesses)
- 从内存中预取数据或者指令
- 分支预测(Branch prediction)
- 乱序的数据加载(Out of order data loads)
- 预测的 cache line 的填充(Speculative cache line fills)
预测式的数据访问只支持normal memory
指令的预测预取可以支持任意内存类型
什么情况下,我们需要考虑内存屏障指令?
- 在多个不同的 CPU 核心(线程)之间共享数据,例如 mailbox 等
- 和外设共享数据,例如 DMA 操作
- 修改内存管理的策略,例如上下文切换,请求缺页,修改页表
- 修改存储指令的内存区域(instruction memory):例如自修代码,加载一个程序到 RAM
ARMv8 提供的内存屏障指令
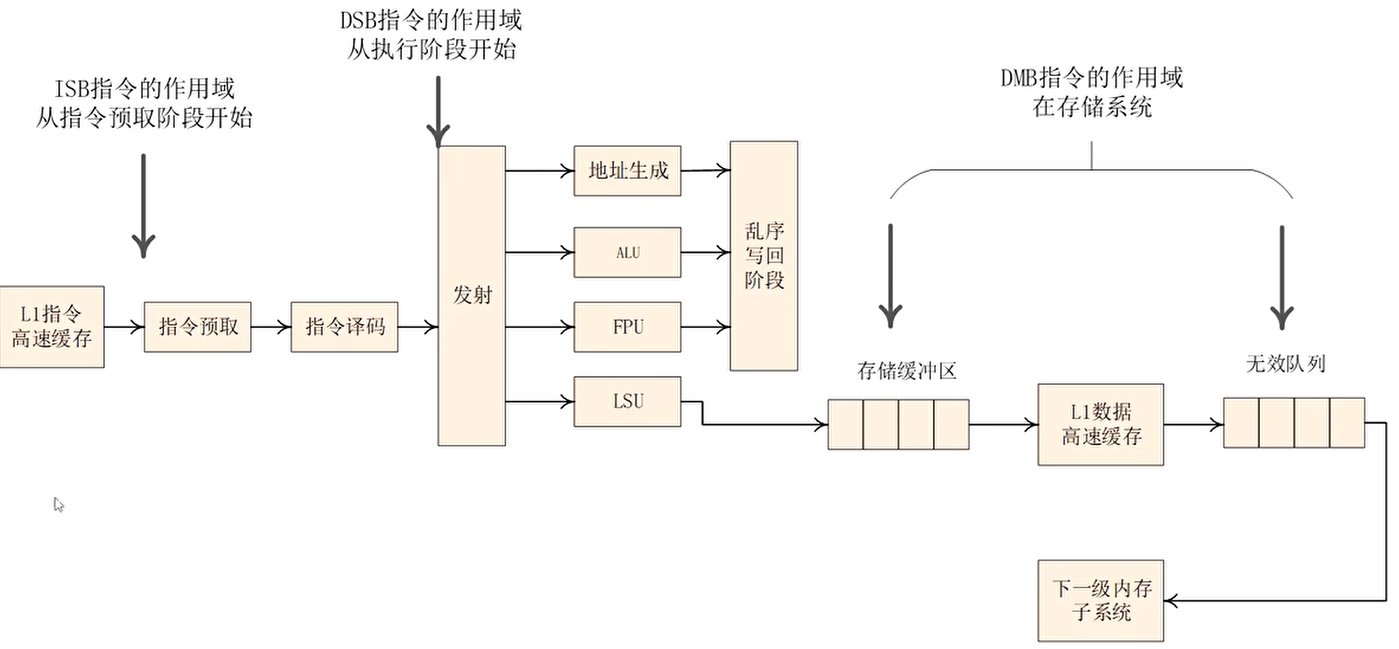
- 数据存储屏障( Data Memory Barrier, DMB )指令
- 数据同步屏障( Data Synchronization Barrier, DSB )指令
- 指令同步屏障( Instruction Synchronization Barrier, ISB )指令
DMB 指令
Ordering of Load/Store instructions
- 仅仅影响数据访问(explicit data accesses,例如 load 和 store)的访问序列
- Data cache 指令也算数据访问
- 保证在DMB 之前的数据访问可以被DMB 后面的数据访问指令观察到
DMB指令需要注意的地方
- DMB 指令关注的是内存访问的序列,不关心数据访问指令什么时候执行完成
- DMB 前面的数据访问指令必须要被 DMB 后面的数据访问指令观察到
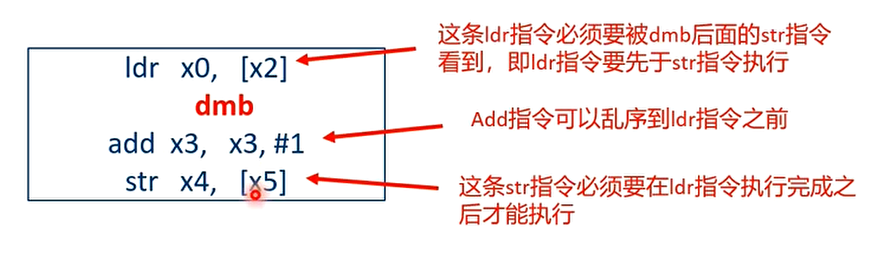
- DMB 前面的 Data/unified cache 指令必须在 DMB 后面的内存访问指令之前执行完成(观察到)
DSB 指令
Completion of Load/Store instructions
- DSB 指令比 DMB 指令严格很多
- 在DSB 指令后面的任何指令,必须等到如下完成了,才能开始执行:
- 在 DSB 指令前面的所有数据访问必须执行完成
- 在 DSB 指令之前的 cache,branch predictor,TLB 等指令必须执行完成
DSB 指令需要注意的地方
- DMB 指令关注的仅仅是数据访问的序列,而 DSB 指令开始关注指令什么时候必须要执行完成
- 在 DSB 指令后面的指令,必须等到:
- DSB 前面的所有数据访问指令都执行完成
- DSB 前面所有的 Cache,TLB 等指令执行完成
dsb 指令更像是 barrier
- 在一个多核系统中,cache 和 TLB 指令会广播到其他 core,所以 DSB 指令会等到这些指令广播并收到回复才算完成
dmb 与 dsb 的区别,例子:


add 指令不是数据访问指令
DMB 和 DSB 指令的参数
可以指定两个维度的参数,一个是Shareability domain,另一个是before-after的访问
Shareability domain
- Full System
- Outer Shareable,前缀为OSH
- Inner Shareable,前缀为ISH
- Non-shareable,前缀为NSH
before-after 的访问(即 memory barrier 指令的前后,进一步细化,读/写 memory barrier)
读 barrier:Load-Load/Store:后缀为LD
This means that the barrier requires all loads to complete before the barrier but
does not require stores to complete. Both loads and stores that appear after the
barrier in program order must wait for the barrier to complete.写 barrier:Store-Store:后缀为ST
This means that the barrier only affects store accesses and that loads can still be
freely re-ordered around the barrier.读写 barrier:Any-Any:后缀为SY
This means that both loads and stores must complete before the barrier. Both
loads and stores that appear after the barrier in program order must wait for the
barrier to complete.

DMB 和 DSB 指令案例 1:mailbox
- 两个 CPU 通过 mailbox 来共享数据:共享内存和 flags

DMB 和 DSB 指令 案例 2:DMA 外设

DSB 指令保证,DMA 引擎在启动前看到了最新的数据已经在 DMA buffer 里。
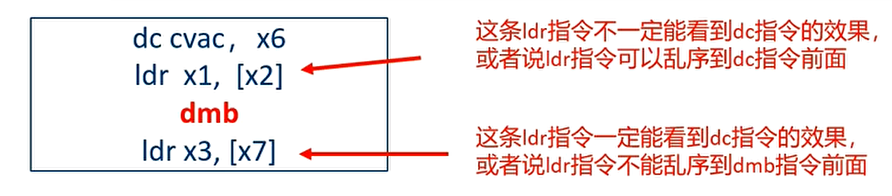
Cache 维护指令的执行顺序
- Cache 维护指令例如 dc 和 ic,它们的执行顺序和其他内存访问指令是一样的,没有特殊性
- 指令单元(instruction interface),数据单元(data interface),MMU walker 等可以看成是不同的观察者(observers)

解决办法:

单方向的内存屏障(one way barriers)
Load-Acquire (LDAR)
All loads and stores that are after an LDAR in program order, and that match the shareability domain of the target address, must be observed after the LDAR.
Store-Release (STLR)
All loads and stores preceding an STLR that match the shareability domain of the target address, must be observed before the STLR.
There are also exclusive versions of the above, LDAXR and STLXR, available.
DMB 和 DSB 都是双向的内存屏障指令,armv8 支持“单方向”的内存屏障原语
获取(acquire)原语:指的是该屏障原语之后的读写操作不能重排到该屏障原语前面,通常该屏障原语与加载指令结合
释放(release)原语:指的是该屏障原语之前的读写操作不能重排到该屏障原语后面,通常该屏障原语和存储指令结合
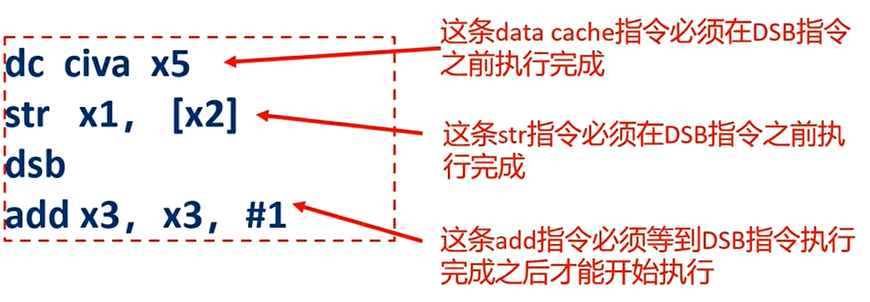
加载-获取(Load-Acquire)屏障原语:普通的读和写操作可以向后越过该屏障指令,但是之后的读和写操作不能向前越过该屏障指令
ARMv8 中的ldar指令
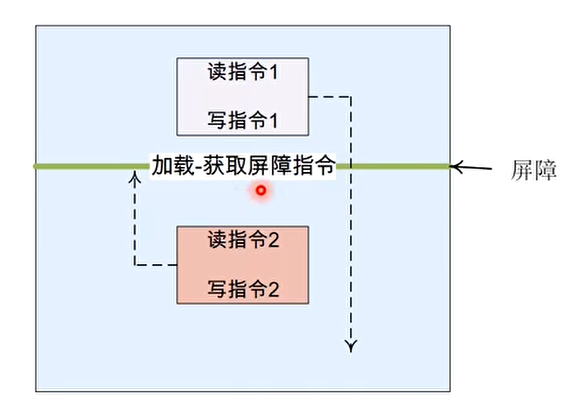
- 存储-释放(Store-Release)屏障原语:普通的读和写可以向前越过存储-释放屏障指令,但是之前的读和写操作不能向后越过存储-释放屏障指令
- ARMv8 中的stlr指令
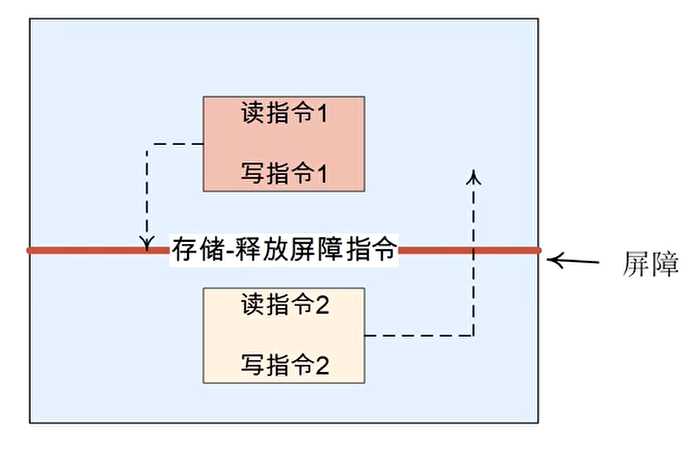
- 加载-获取(Load-Acquire)以及存储-释放(Store-Release)通常需要配对使用
- ldar和stlr配对使用:
- 用于保护一个临界区数据
- 在临界区的指令可以乱序(仅限临界区范围内)
- 比全功能的 DMB 指令性能要好
- 对 data cache 维护指令没有作用,因为它不会去等待 cache 的广播
指令级别的内存屏障指令:ISB 指令
Context synchronization
ISB 指令威力巨大,它会flush 流水线,然后从指令 cache 或者内存中重新预取指令。
ISB 指令保证
- ISB 后面的指令都从指令 cache 或者内存中重新取址
- ISB 指令前面的更改上下文操作(contex-changing operation)都已经完成(这里的 contex 指的是系统寄存器状态等)
更改上下文操作(contex-changing operation)包括:
- Cache,TLB 和 branch predictor 等操作
- 改变系统寄存器,例如 TTBR0
The ARMv8 architecture defines context as the state of the system registers and context-changing operations as things like cache, TLB, and branch predictor maintenance operations, or changes to system control registers, for example, SCTLR_EL1, TCR_EL1, and TTBRn_EL1. The effect of such a context-changing operation is only guaranteed to be seen after a context synchronization event.
更改上下文操作的效果:仅仅在上下文同步事件之后能看到
上下文同步事件(context synchronization event)
- 发生一个异常(exception)
- 从一个异常返回
- ISB 指令
实际上修改系统寄存器后一般都需要 isb 指令,尤其是修改了系统控制寄存器,但例如 PSTATE 等系统寄存器则不需要
ISB 指令例子 1:打开 FPU

改变了系统控制寄存器时需要一条 isb 指令
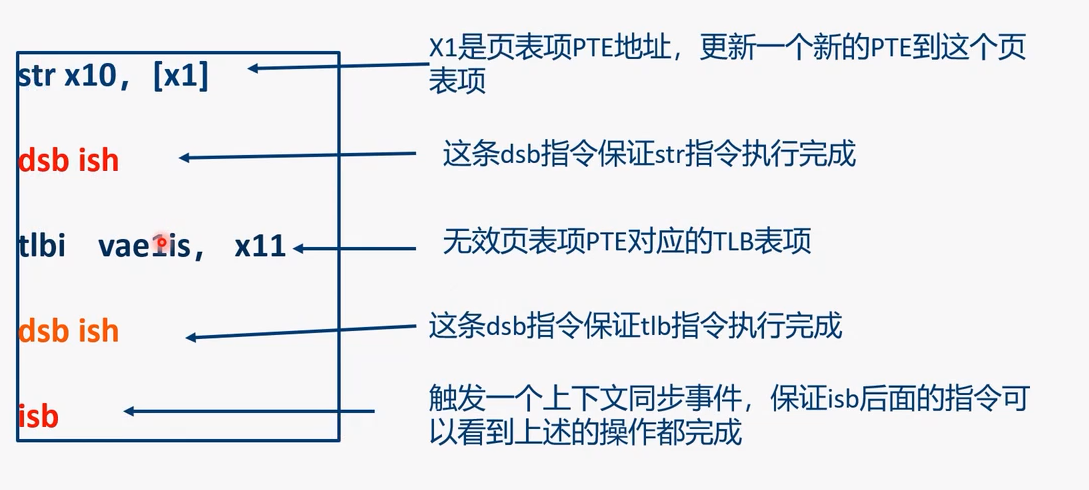
ISB 指令例子 2:改变页表项
ISB 指令例子 3:self-modify code
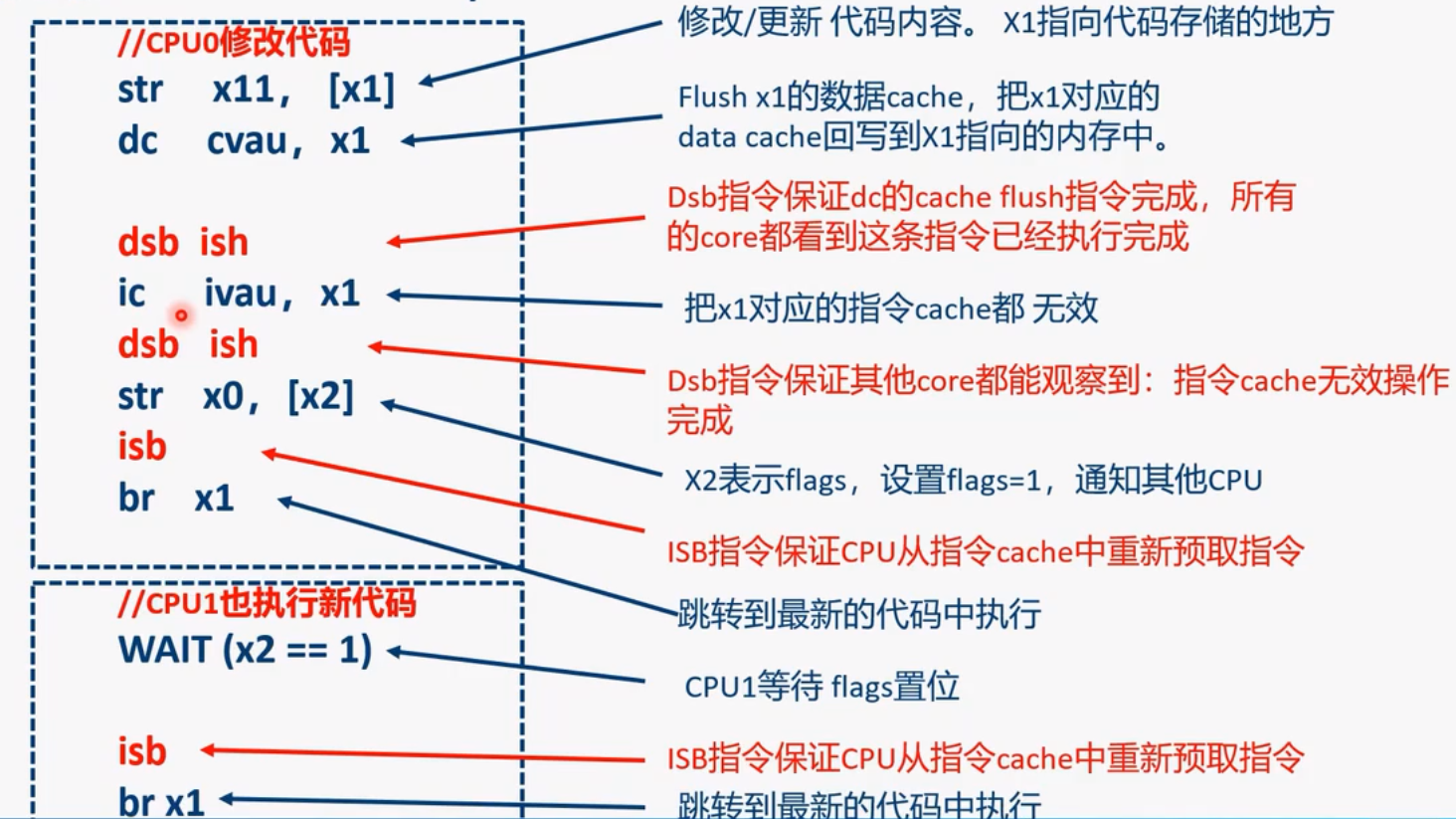
- 在更新新代码内容(str x11,[x1])和 clean 数据 cache 指令之间没有使用内存屏障指令
- 更新代码的内容和 clean 数据 cache 都是操作相同的地址,并且都是数据相关的操作,他们之间有数据依赖性,可以理解为相同的观察者
- 他们之间可以保证程序执行的次序(program order)
- 在 clean 数据 cache 和无效指令 cache 之间需要内存屏障
- 虽然这两条 cache 指令都是操作相同的地址,但是他们是不同的观察者(一个是数据端,另外一个是指令端)
- 这里的 DSB 保证 clean 完数据 cache 之后才去无效指令 cache
- 在一个多核一致性的系统中,DSB 指令能保证 cache 维护指令执行完成,即其他 CPU 都能够观察到 cache 维护指令完成
- ISB 指令不会 broadcast,因此 CPU1 也需要执行 isb 指令
Non-temporal load and store pair
LDNP 和 STNP
LDNP 和 STNP执行读取或写入一对寄存器值的指令。它们还向内存系统提示缓存对这些数据没有用处。该提示不会禁止内存系统活动,例如地址缓存、预加载或收集,而只是表明缓存不太可能提高性能。一个典型的用例可能是流数据,但应该注意,有效使用这些指令需要一种特定于微架构的方法。
非临时加载和存储放宽了内存排序要求。在上述情况下,可能会在前面的 LDR 指令之前观察到 LDNP 指令,这可能导致从 X0 中不可预知的地址读取。例如:
1 | LDR X0, [X3] |
要纠正上述问题,您需要一个明确的负载屏障:
1 | LDR X0, [X3] |
总结:内存屏障指令与 cache/TLB 维护指令
- data cache 或者 unified cache 维护指令
- 可以使用 DMB 指令来保证 cache 维护指令在指定的 shareable domain 中执行完成
- Load-acquire 和 store-release 屏障对 data cache 维护指令没有作用(因为它不会去等待 cache 的广播)
- 指令 cache 维护指令
- 指令 cache 和数据 cache 在内存观察者角度看,是两个不同的观察者
- 在指令 cache 和维护操作完成之后执行一条 DSB 指令,确保 inner shareable domain 里所有的 CPU 核心都能看到这条指令 cache 的执行完成
- TLB 维护指令
- 遍历页表的单元和数据访问的硬件单元,其实是两个不同的内存系统的观察者
- 在 TLB 维护指令后面需要执行一条 DSB 指令,来保证 inner shareable domain 里面的所有 CPU 都能完成
- ISB 指令不会 broadcast,如果需要每个 CPU 核心需要单独调用 ISB 指令
芯片手册阅读 memory barrier
ARM Architecture Reference Manual Armv8, for Armv8-A architecture profile
- B2.3.7 Memory barriers
- (重点) Appendix K11 Barrier Litmus Test
ARM Cortex-A Series Programmer’s Guide for ARMv8-A
- 13.2 Barriers
再谈缓存一致性与内存屏障
问题的引入

下面的执行顺序
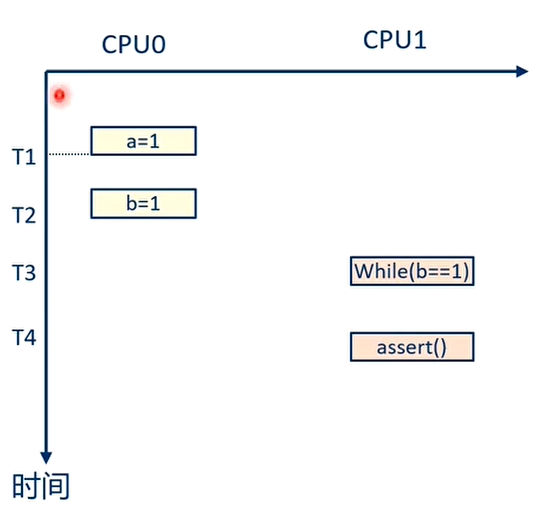
CPU1 的断言仍然可能失败!!!
缓存一致性协议带来的 CPU 停滞现象
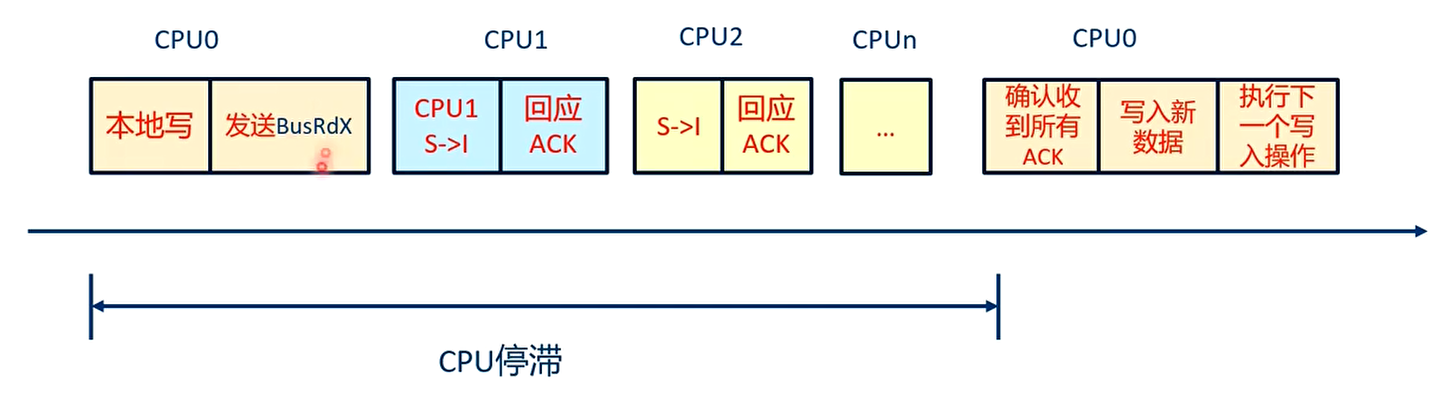
- MESI 协议是一种基于总线侦听和传输的协议,其总线传输带宽和 CPU 之间的负载以及 CPU 核数量有关系
- 高速缓存行状态的变化严重依赖于其他告诉缓存行的应答信号,即必须受到其他所有 CPU 的高速缓存行的应答信号才能进行下一步的状态转换。在一个总线繁忙或者总线带宽紧张的场景下,CPU 可能需要比较长的时间来等待其他 CPU 的应答引号,这会大大影响系统性能,这个现象称为 CPU 停滞(CPU stall)
例子分析:MESI 协议带来的 CPU 停滞
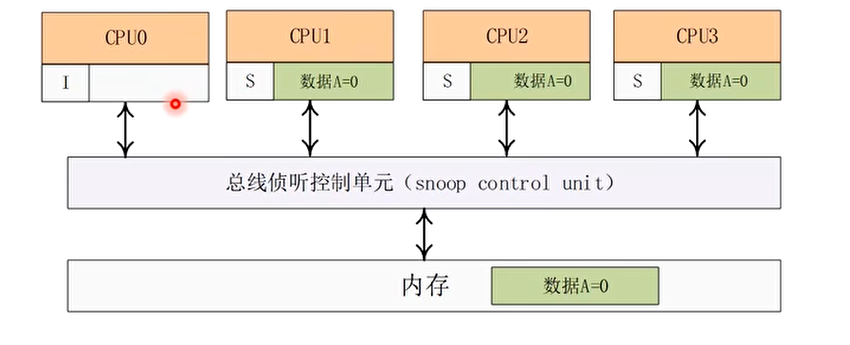
在一个 4 核 CPU 系统中,数据 A 在 CPU1,CPU2 以及 CPU3 上共享,它们对应的高速缓存行的状态为 S(共享),A 的初始值为 0。而数据 A 在 CPU0 的高速缓存中没有缓存,其状态为 I(无效)
此时,CPU0 往数据 A 中写入新值(例如写入 1),那么这些高速缓存行的状态会如何发生变化呢?
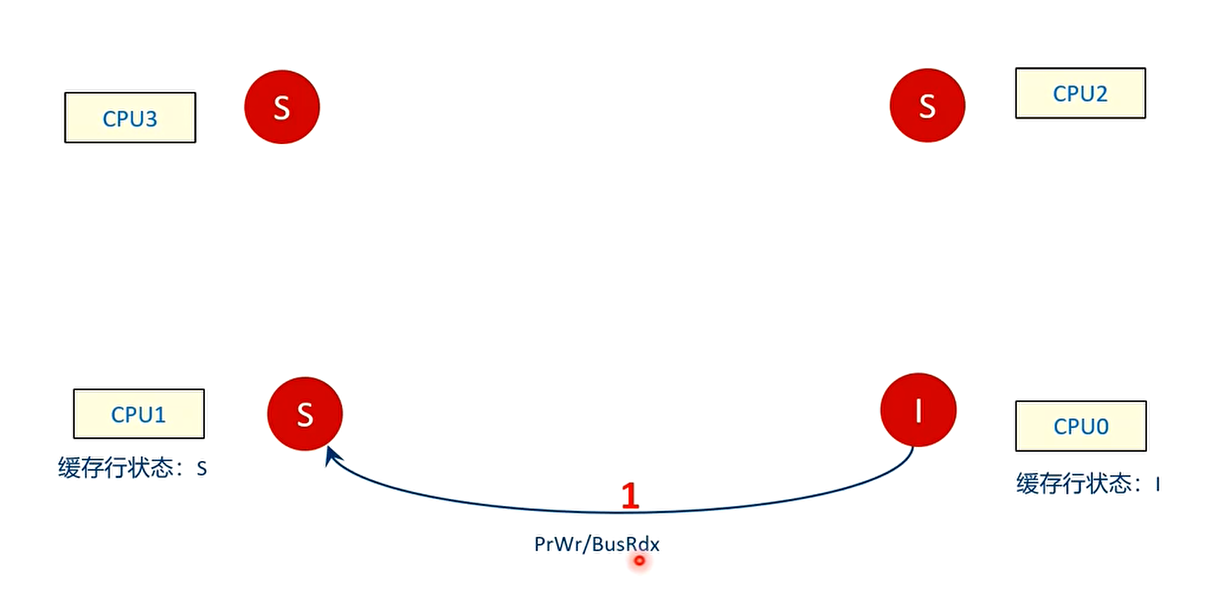
T1 时刻
CPU0 向总线发送一个本地写操作信号
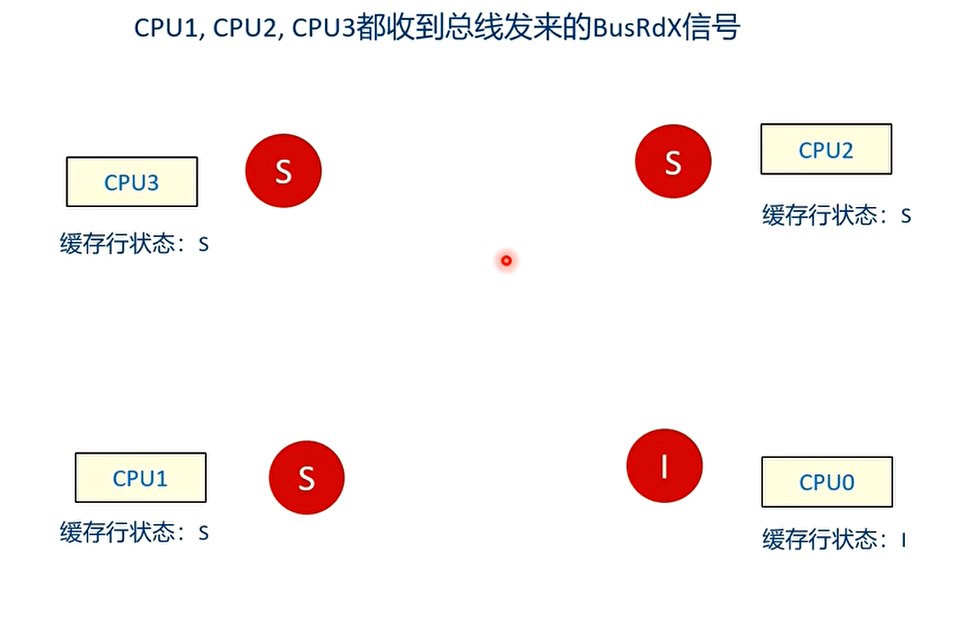
T2 时刻
CPU1,CPU2,CPU3 都收到总线发来的 BusRdX 信号
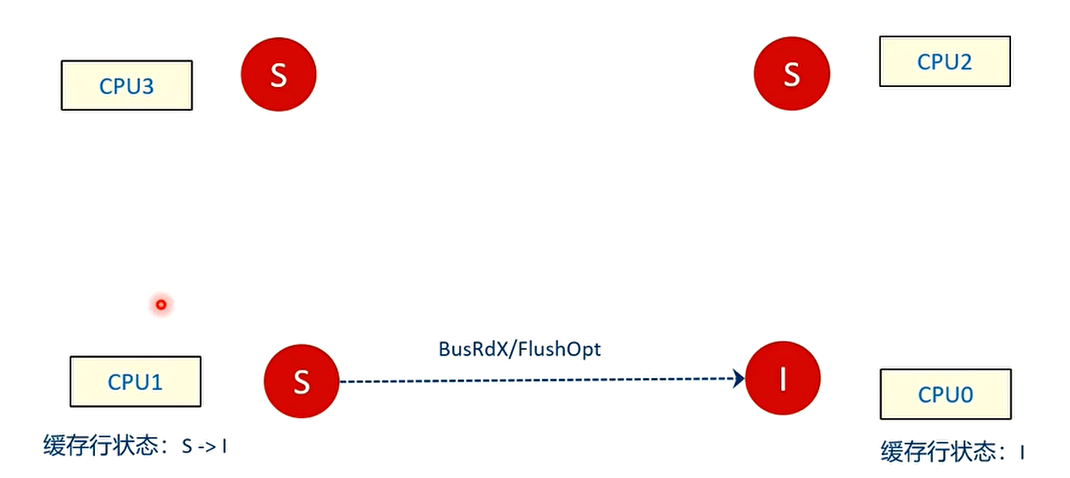
T3 时刻
CPU1 检查自己本地高速缓存中是否有缓存数据 A 的副本。CPU1 回复一个Flushopt信号并且把数据发送到总线上,然后把自己的高速缓存行状态设置为无效,状态变成 I,最后广播应答信号。
T4 时刻
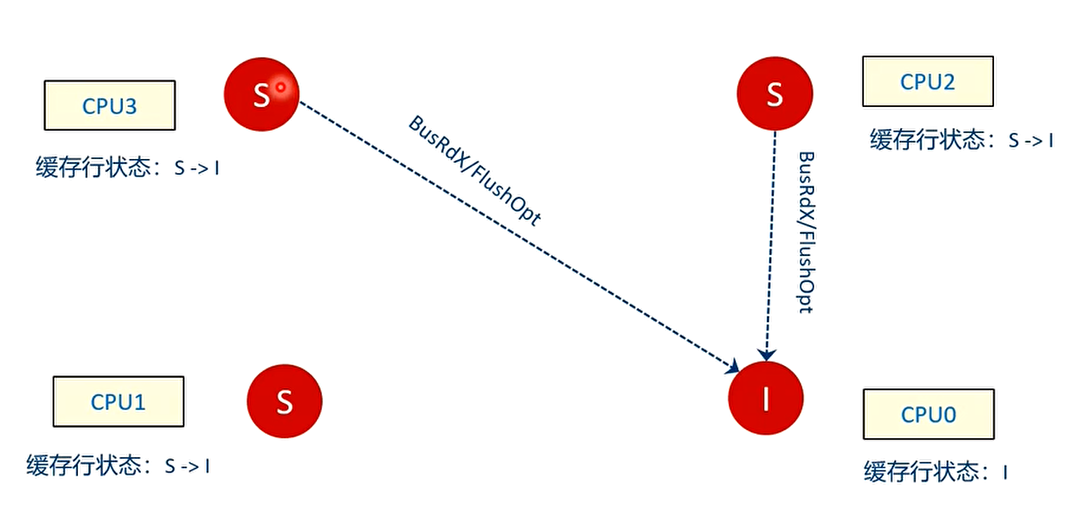
CPU2 和 CPU3 都检查本地 loacl cache,状态从 S 变成 I
T5 时刻
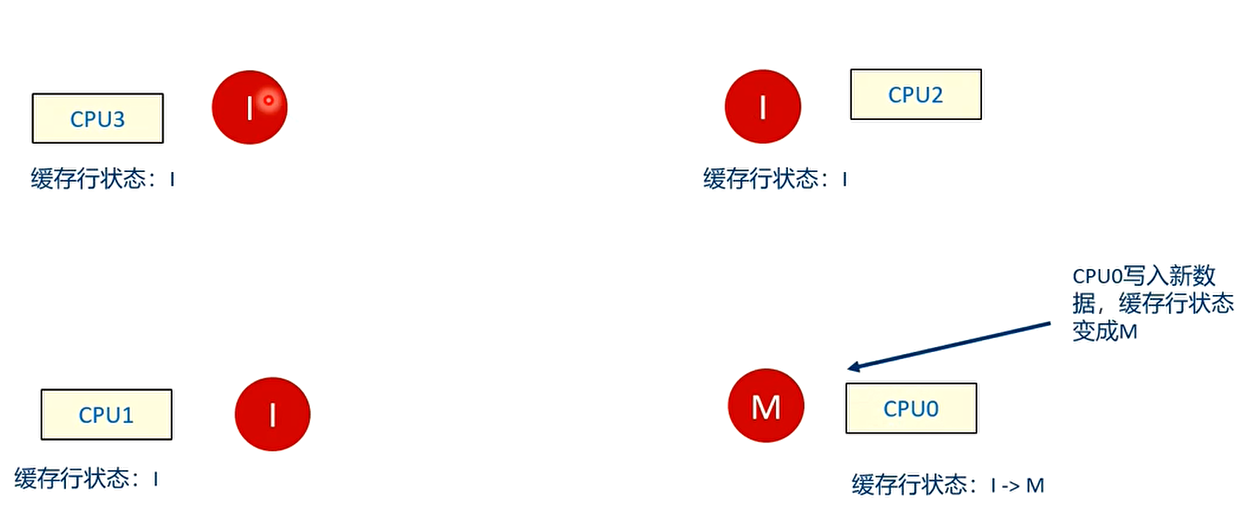
CPU0 接收其他所有 CPU 的应答信号,确认其他 CPU 上没有这个数据的缓存副本或者缓存副本已经被无效之后,才能修改数据 A。最后,CPU0 的高速缓存行状态变成 M。
总结
CPU0 有一个等待的过程,它需要等待其他所有 CPU 的应答信号
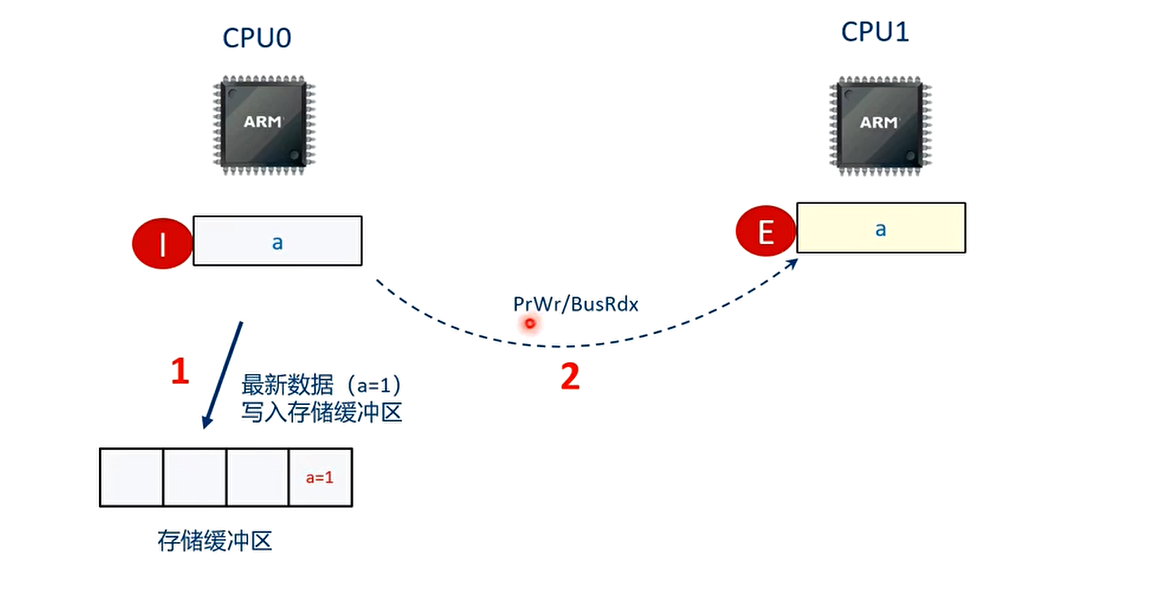
优化办法 1:存储缓冲区(Store Buffer)
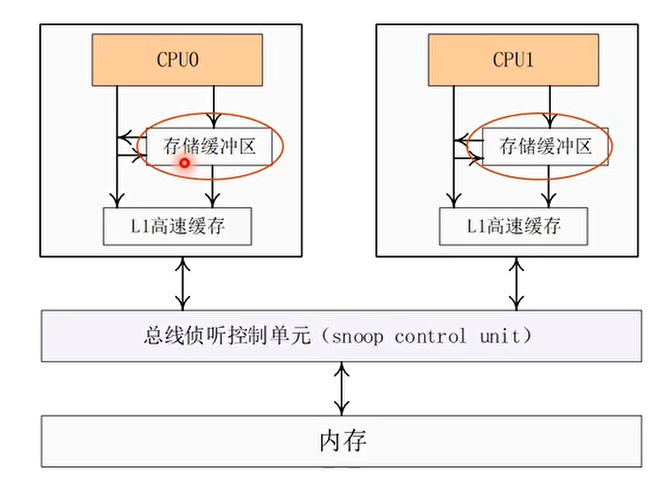
- 不需要等待其他 CPU 的应答信号,可以先把数据写入到存储缓冲区中,继续执行下一条指令
- 当 CPU0 都收到了其他 CPU 都回复的应答信号之后,CPU0 才从缓冲存储区中把数据 A 的最新值写入本地高速缓存行,并且修改高速缓存行的状态为 M
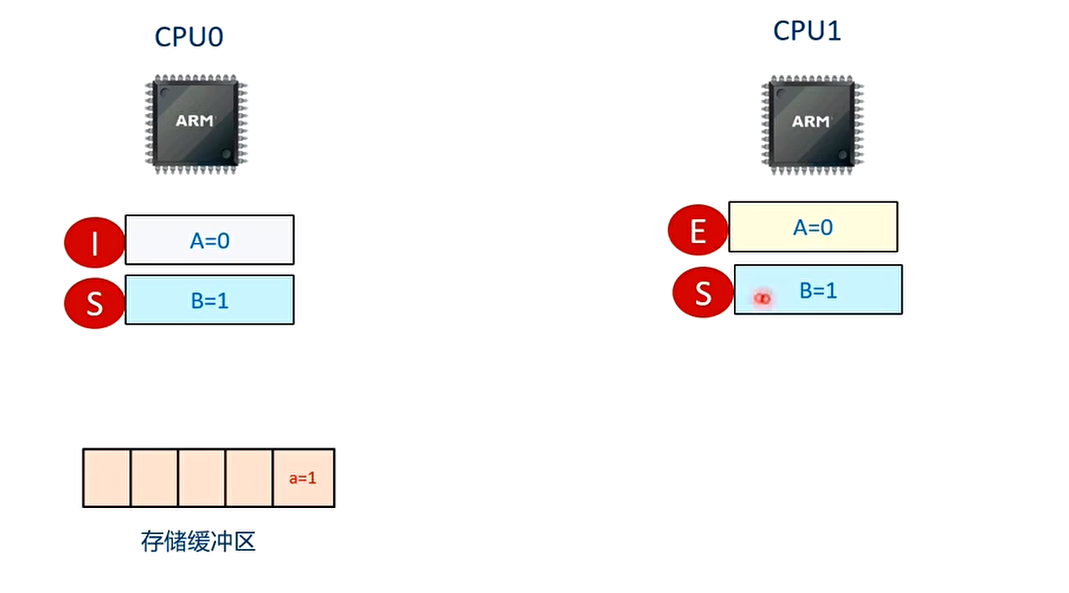
存储缓冲区带来的副作用

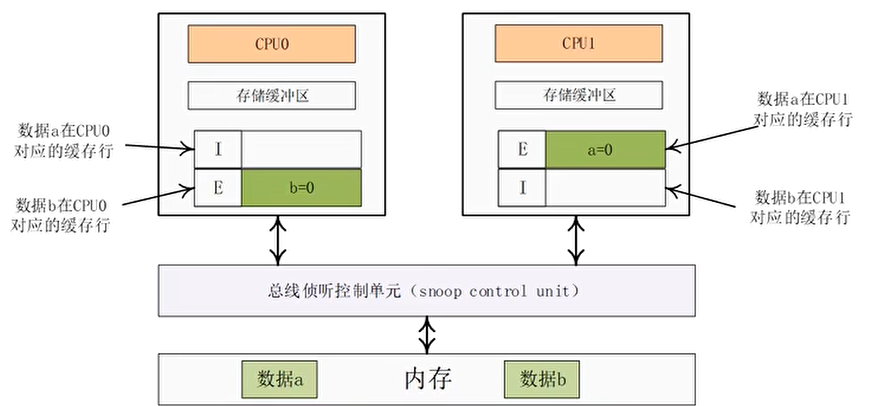
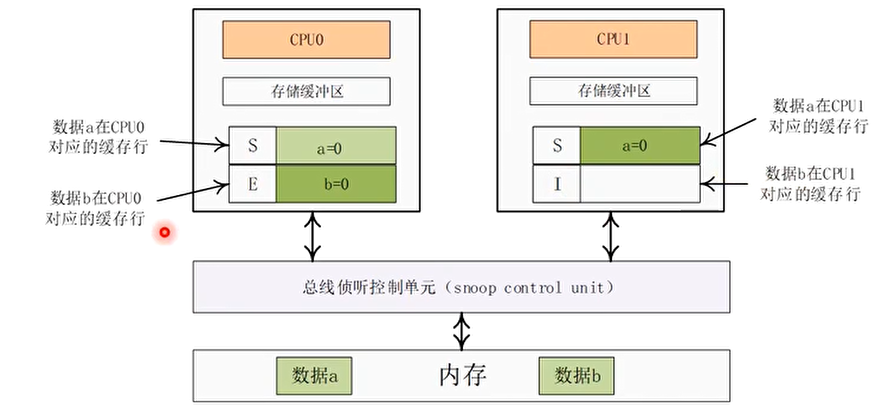
数据 a 在 CPU1 的高速缓存中有缓存副本,且状态为 E
数据 b 在 CPU0 的高速缓存里有缓存副本,且状态为 E
那么在带有缓冲区的系统中,会不会发生 assert 失败?
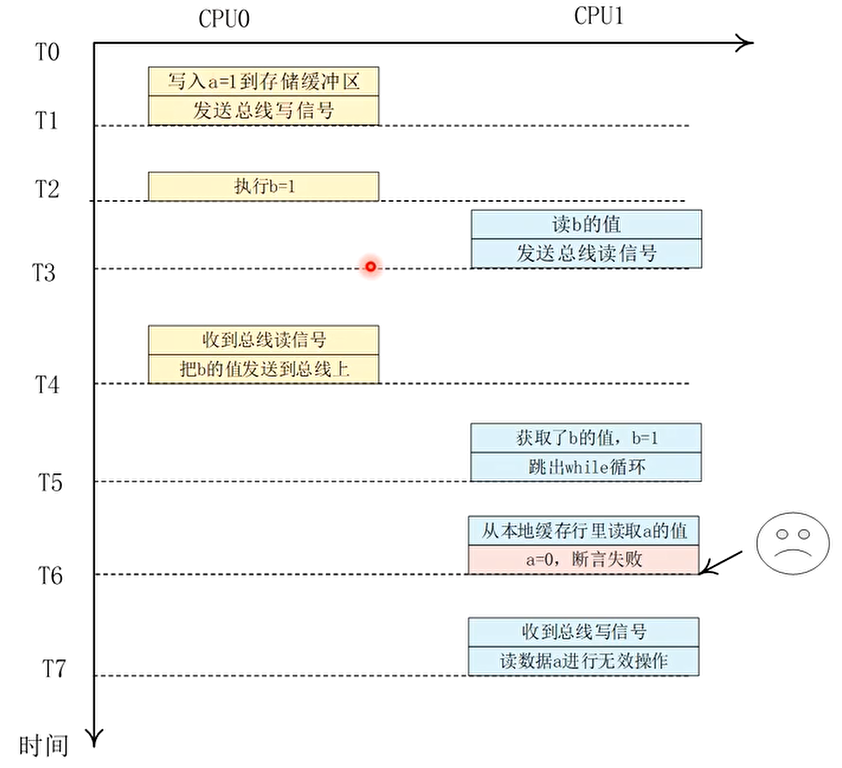
T1 时刻 CPU0 执行”a=1”的语句
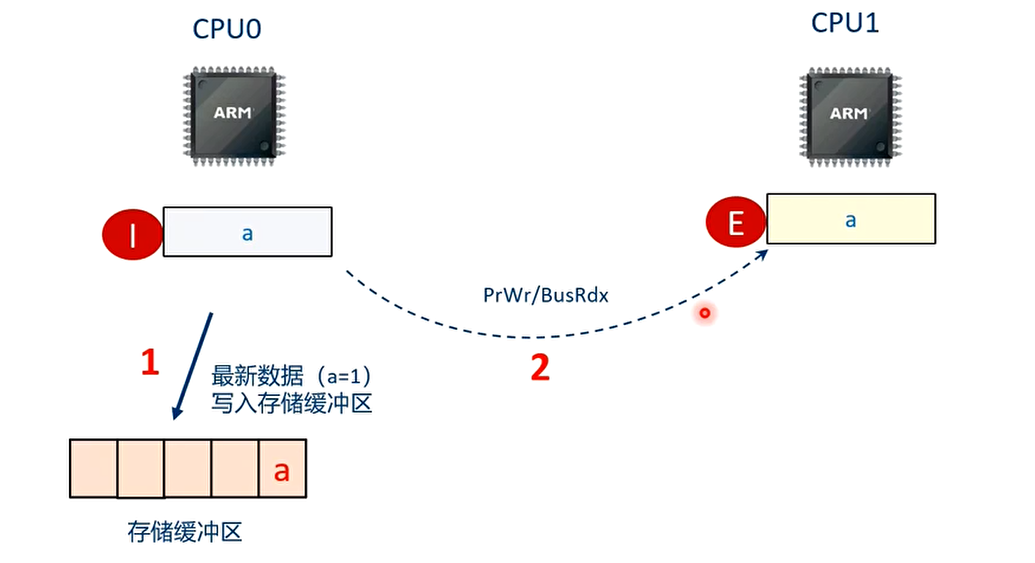
T2 时刻 CPU0 执行”b=1”的语句
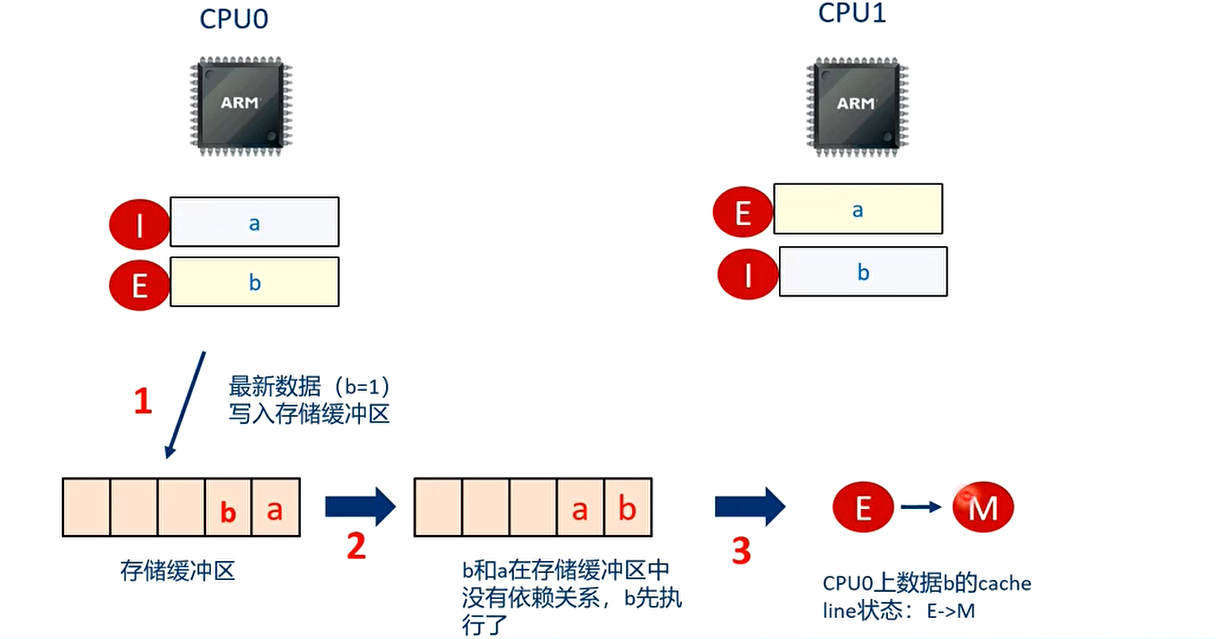
T3 时刻 CPU1 执行”while(b==0)”的语句
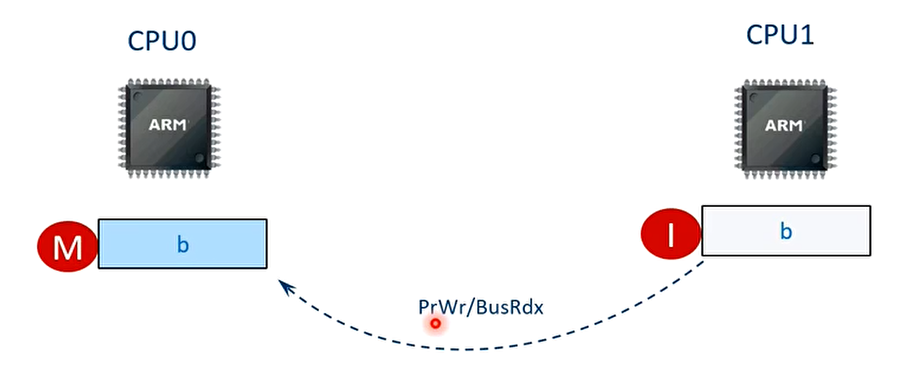
T4 时刻 CPU0 收到总线读信号。
T5 时刻 CPU1 获取了 b 的最新值
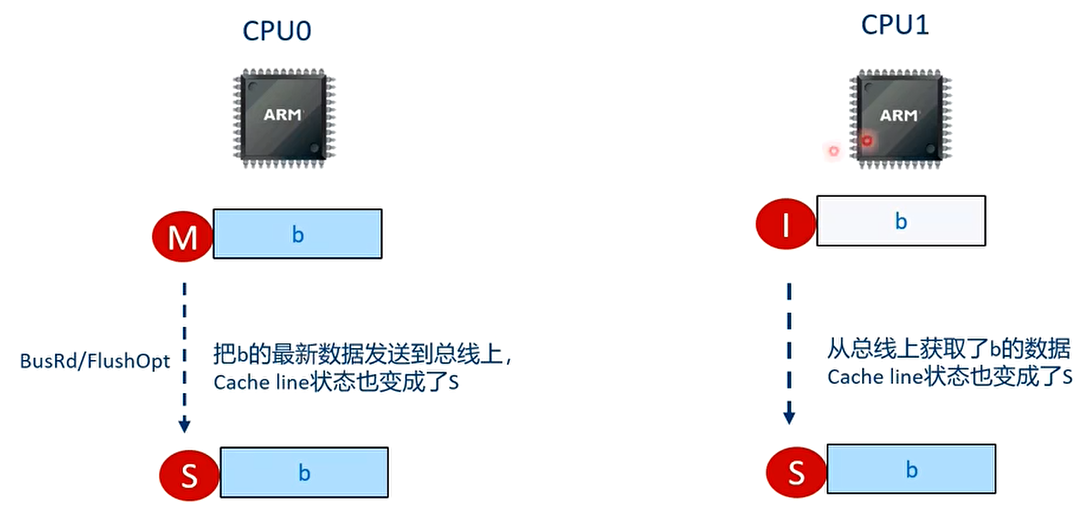
T6 时刻 assert 失败
整个过程的流程图
副作用解决办法:使用写内存屏障指令
- 存储缓冲区,优化了多核处理器之间长时间等待应答信号导致的性能下降。但是,依然无法感知多核 CPU 之间是否存在数据依赖
- 写内存屏障语句(例如 smp_wmb()),把当前存储缓冲区中所有的数据都做一个标记,然后flush 存储缓冲区,保证之前写入到存储缓冲区的数据更新到高速缓存行,然后才能执行后面的写操作
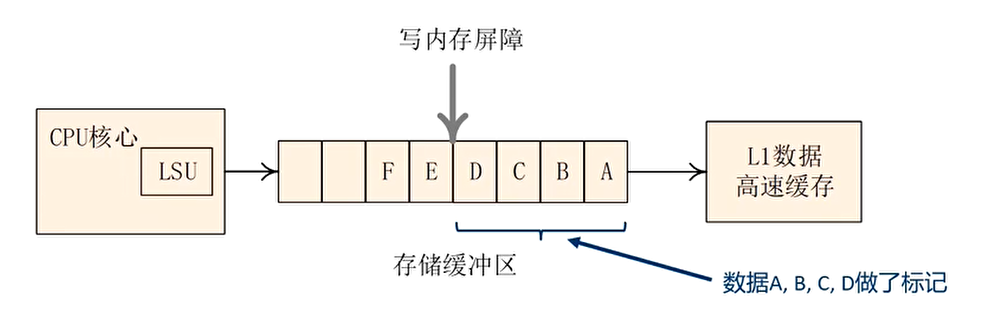
解决办法:加入写内存屏障语句:

**T1 时刻 **CPU0 执行”a=1”语句
T2 时刻 CPU0 执行”smp_wmb()”
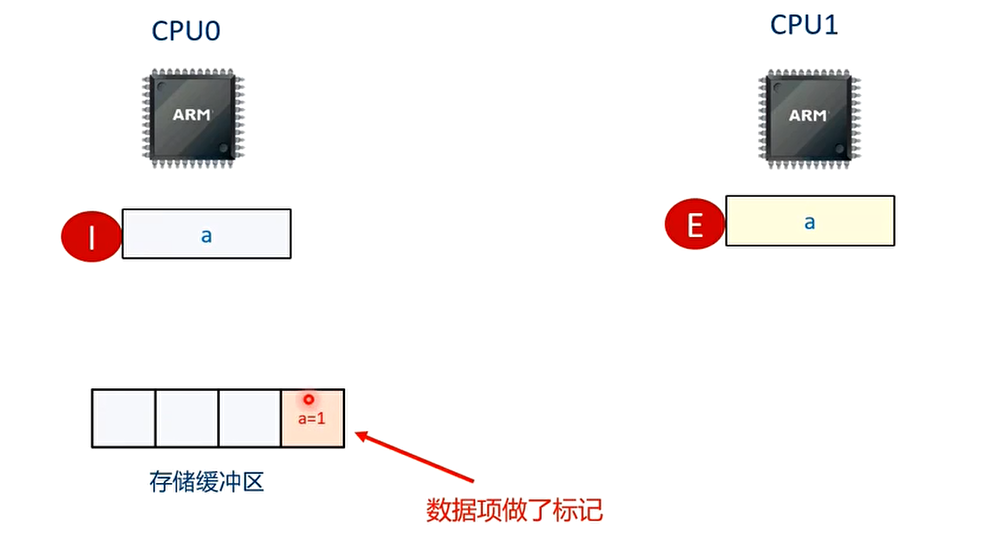
T3 时刻:CPU0 执行”b=1”的语句
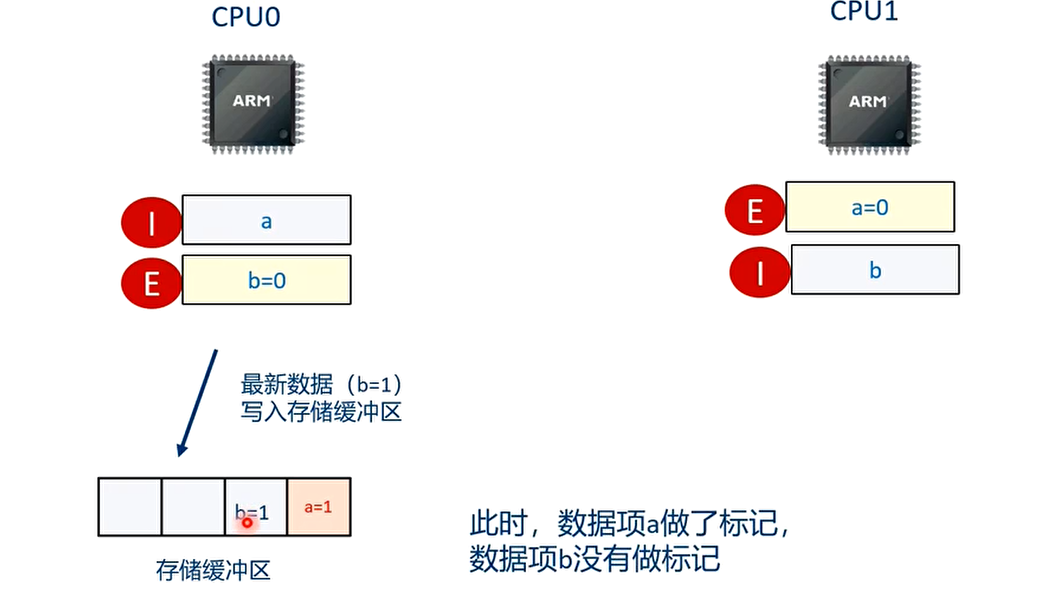
T4 时刻 CPU1 执行”while(b==0)”的语句
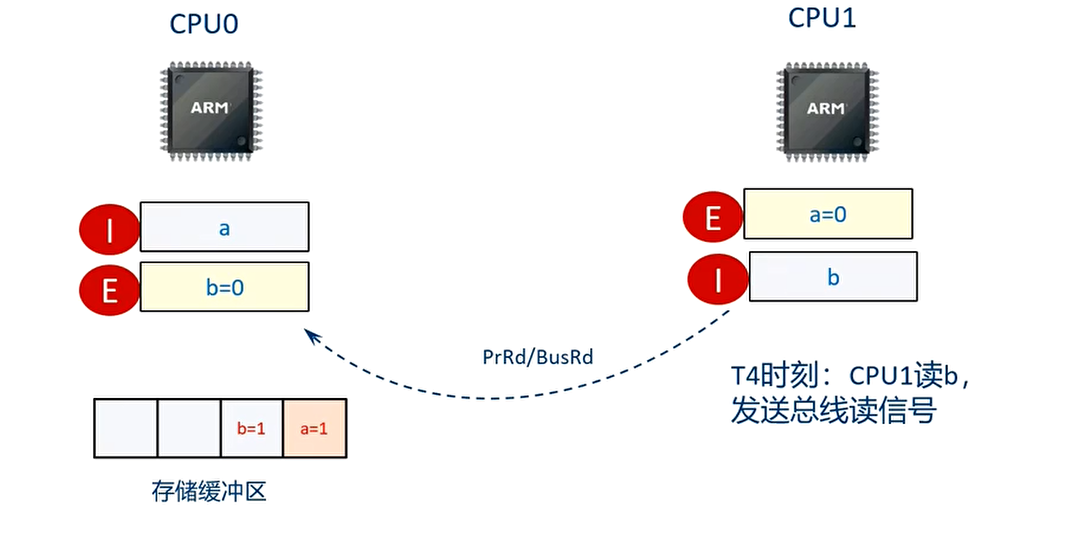
T5 时刻
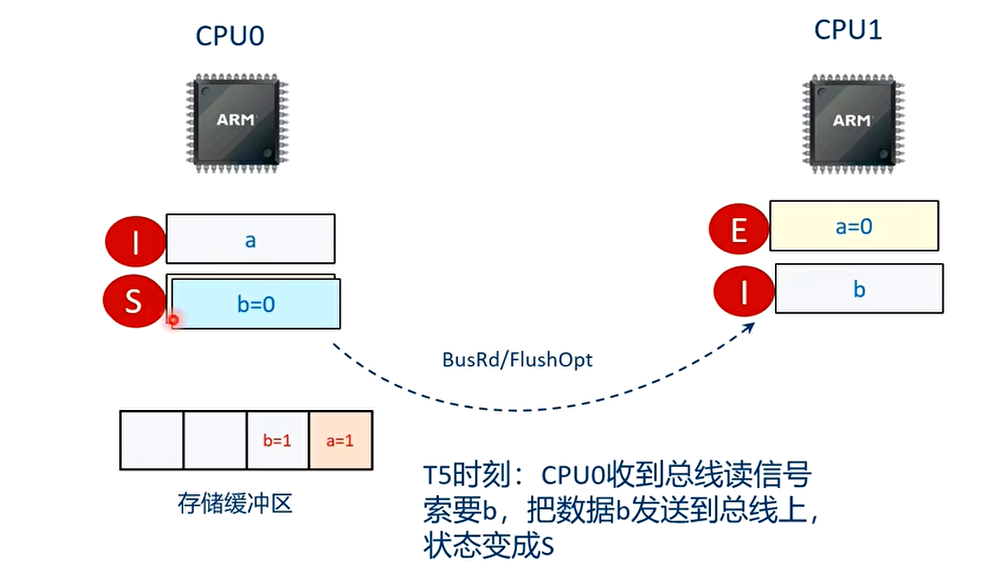
CPU 的数据 b 状态从 E 变为 S
T6 时刻
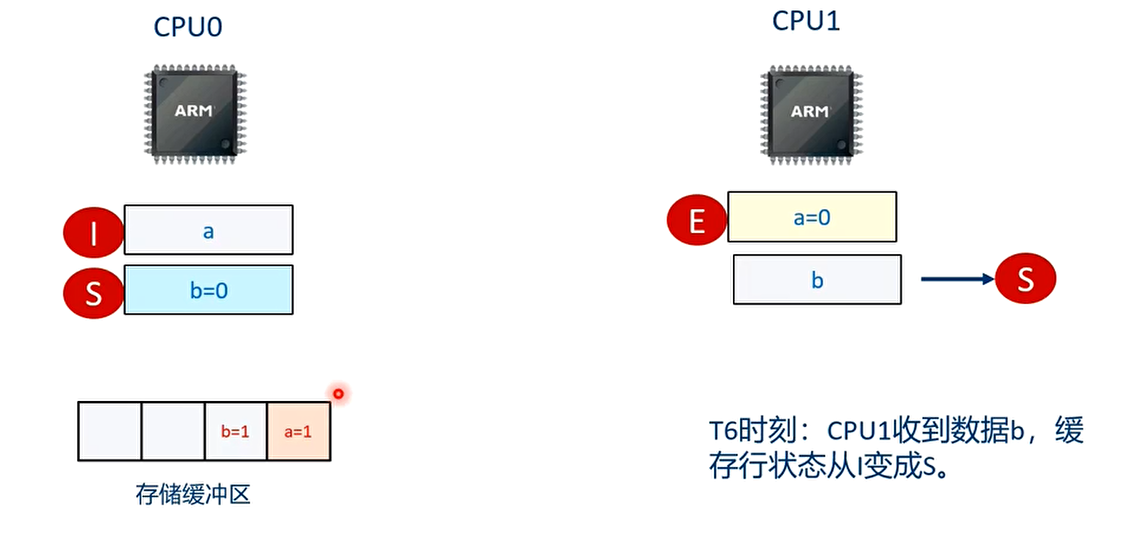
T7 时刻
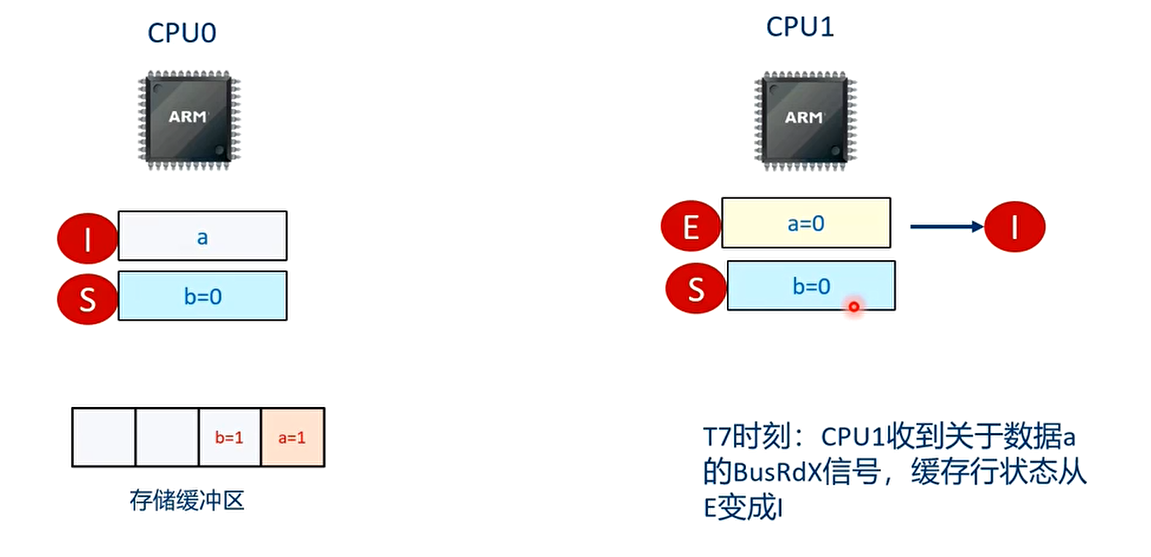
T8 时刻
CPU0 收到关于数据 a 的回应信号。把存储缓冲区的数据 a 写入高速缓存中。
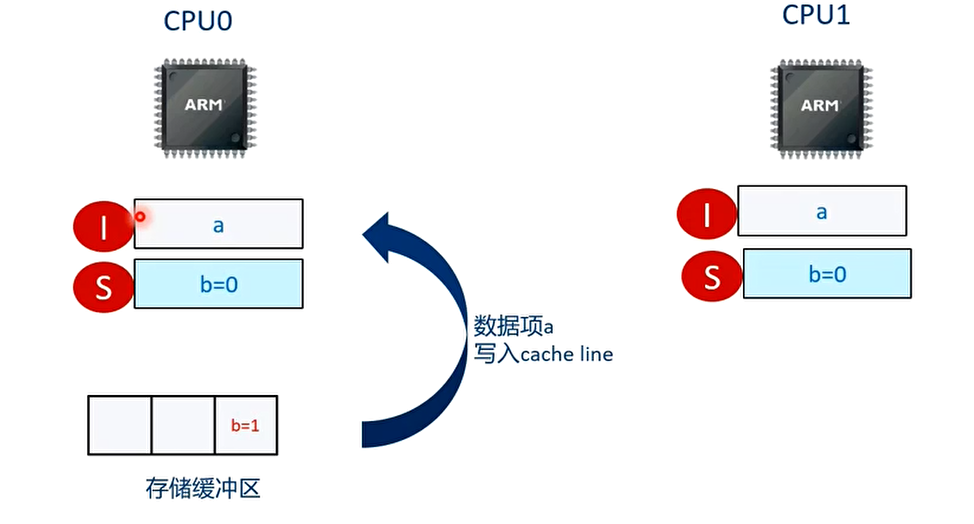
T9 时刻
在存储缓冲区的数据项 b 也写入高速缓存中
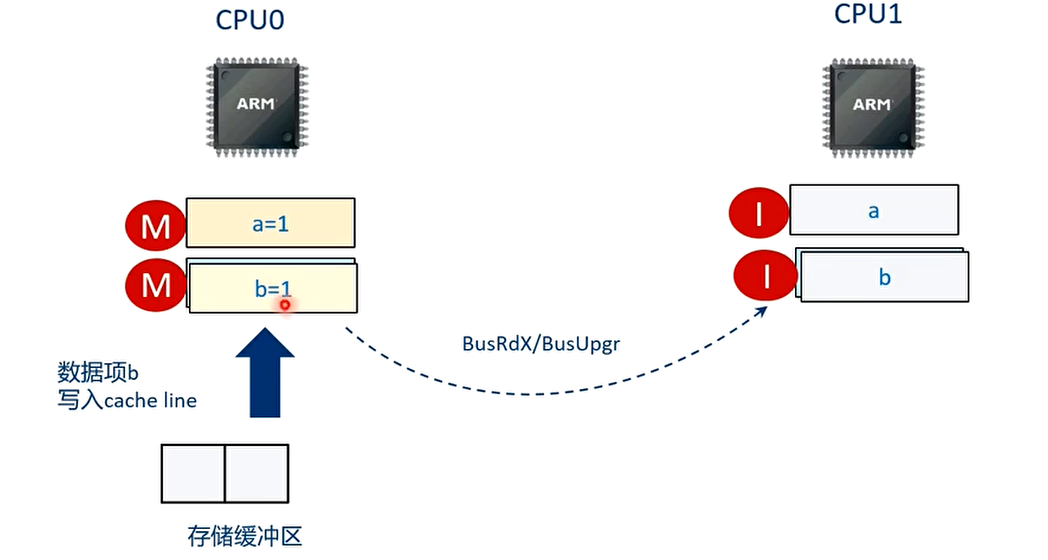
T10 时刻
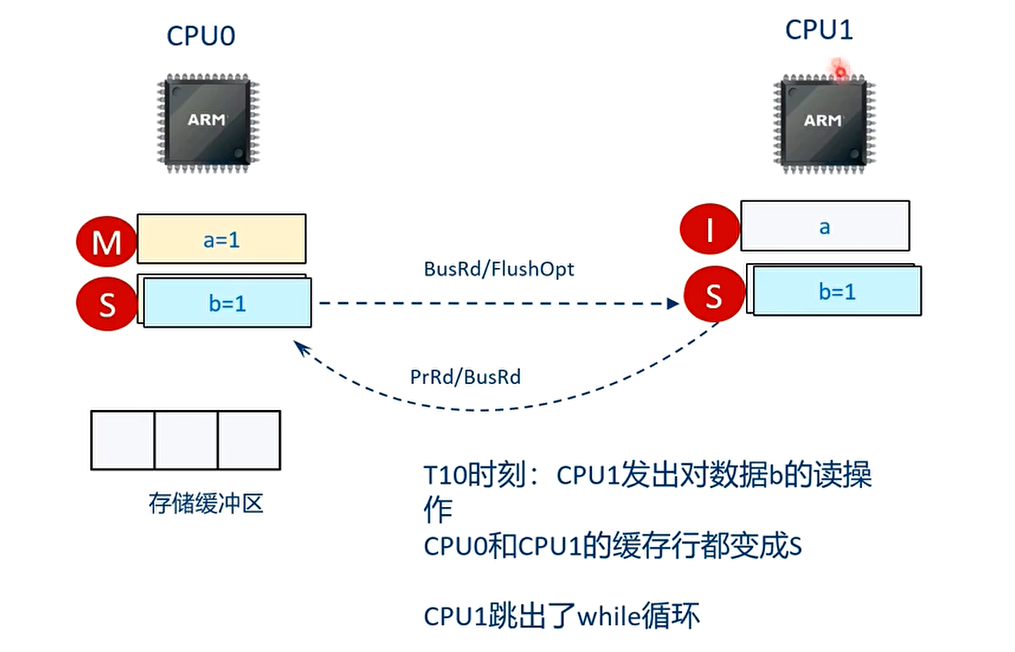
T11 时刻
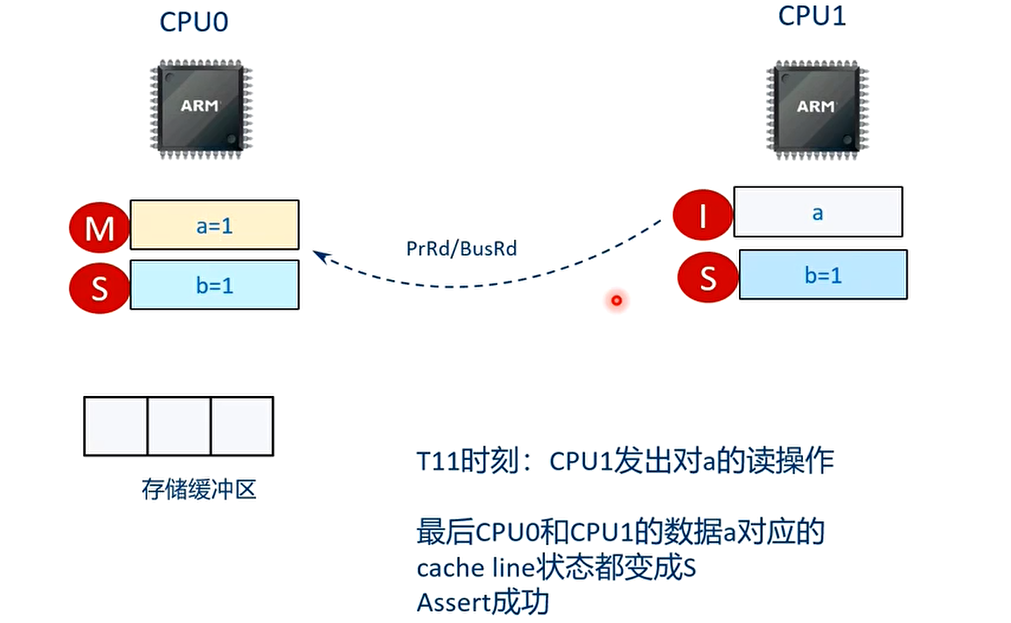
T12 时刻
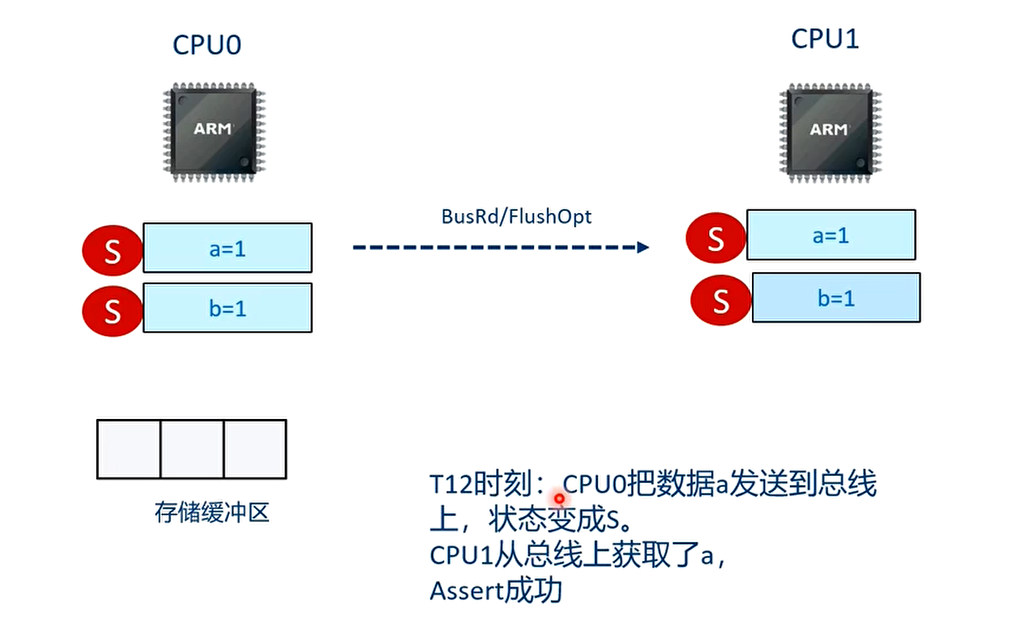
因为 a=1 和 b=1 之间加入了 smp_wmb()指令,因此 b=1 的写入高速缓存的操作必须在 a=1 写入高速缓存后才能执行
优化办法 2:无效队列(Invalidate Queue)
- 优化方法 1 中的存储缓冲区很小,容易填满
- CPU 停滞的一个原因是:等待其他 CPU 做”使无效”的操作(invalidate)而且比较耗时
- 无效队列:把”使无效操作”缓存起来,先给请求者回复一个应答信号,然后再慢慢做无效操作,这样其他 CPU 就不必长时间等待了
回复无效操作的 CPU 本身也不需要这个数据
- 当 CPU 收到总线请求之后,如果需要执行无效本地高速缓存行的操作,那么会把这个请求加入到无效队列里,然后立马给对方回复一个应答信号,而无需把该高速缓存行无效之后再应答
- 如果 CPU 将某个请求加入到无效队列,那么在该请求对应的无效操作完成之前,那么 CPU 不能向总线发送任何与该请求对应的高速缓存行相关的总线消息。
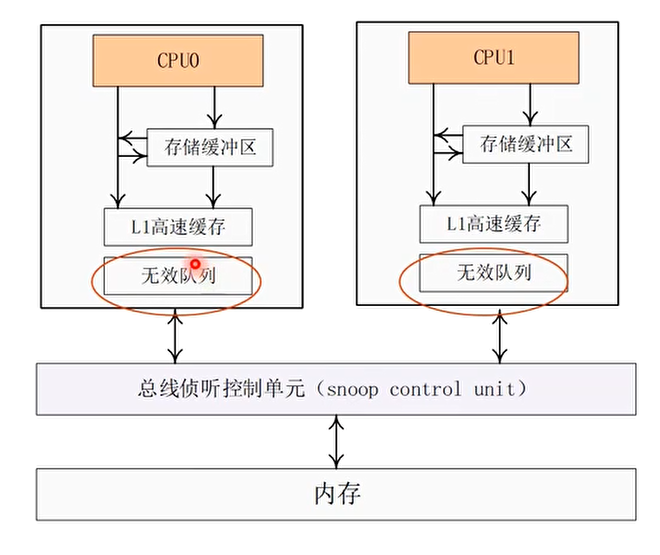
无效队列的副作用

假设数据 a 和数据 b 的初始值为 0,数据 a 在 CPU0 和 CPU1 都有副本,状态为 S,数据 b 在 CPU0 上有缓存副本,状态为 E,那么 assert 会成功吗?
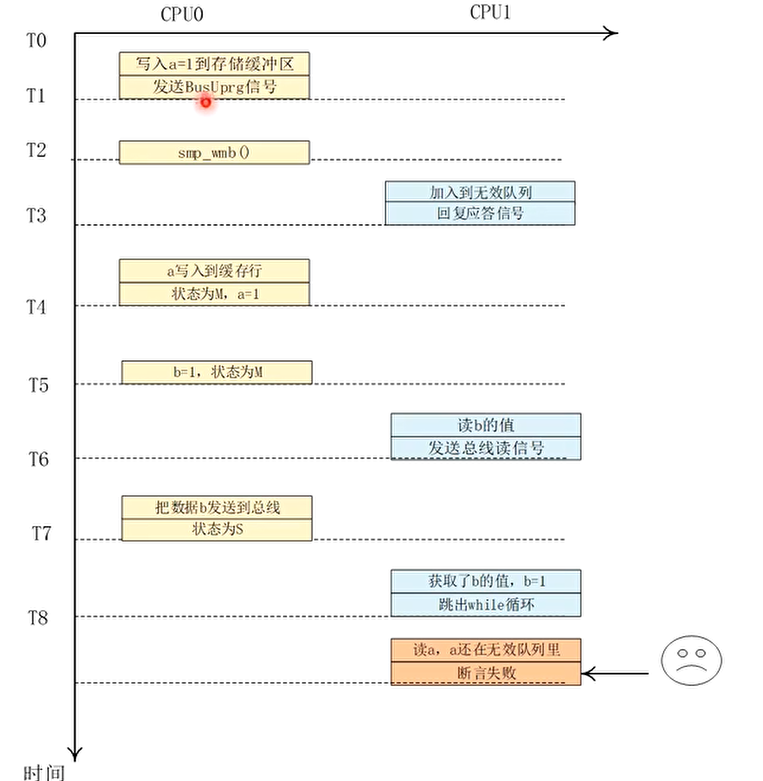
副作用解决办法:使用读内存屏障指令
读内存屏障指令: 读内存屏障指令可以让无效队列里所有的无效操作都执行完成才能执行该读屏障指令后面的读操作。

内存屏障与缓存一致性的总结
在 SMP 中,一条简单的 load 和 store 指令不简单,它的行为需要与 MESI 缓存一致性协议结合来分析
内存屏障需要和 MESI 缓存一致性来结合分析
存储缓冲区和无效队列是一种硬件优化手段,但是也带来一些副作用
读内存屏障指令作用于无效队列,让无效队列中积压的无效操作尽快执行完成才能执行后面的读操作
写内存屏障指令作用域存储缓冲区,让存储缓冲区中数据写入到高速缓存之后才能执行后面的写操作
Linux 内核中提供的内存屏障 API
Linux 内核抽象出一种最小的共同性,在这个集合里,每种处理器体系结构都能支持
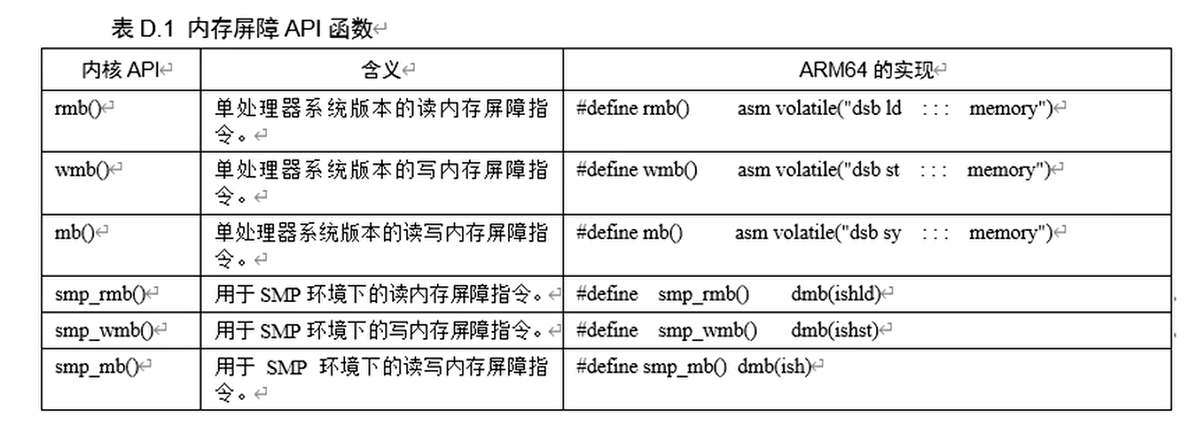
ARM64 内存屏障指令的深入理解