ARM Cache Coherency
时间轴
2025-10-26
init
参考文档:

为什么要cache一致性(cache coherency)?
- 系统中各级cache都有不同的数据备份,例如每个CPU核心都有L1 cache
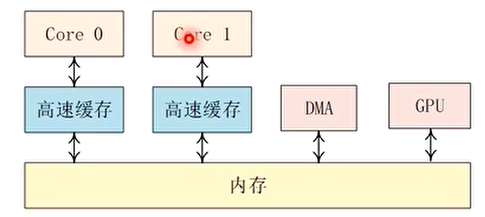
- cache一致性关注的是同一个数据在多个高速缓存和内存中的一致性问题,解决高速缓存一致性的方法主要是总线监听协议,例如MESI协议
- 需要关注cache一致性的例子:
- 驱动中使用DMA(数据cache和内存不一致)
- Self-modifying code(数据cache的数据可能比指令cache新)
- 修改了页表(TLB里保存的数据可能过时)
ARM的cache一致性的演进
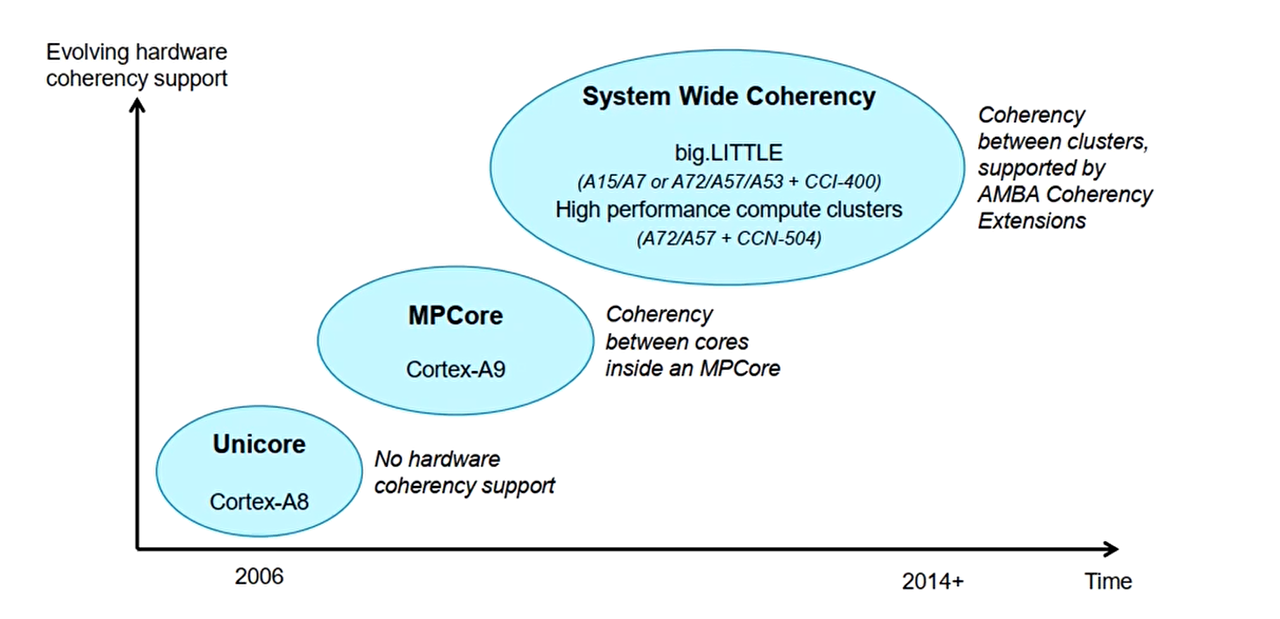
Cortex-A8是单核架构,没有核心之间的cache一致性问题,但是存在DMA和cache之间的一致性问题
Cortex-A9的多核版本(MPCore)存在核心之间的cache一致性问题,通常的做法是在硬件上实现一个MESI协议
Cortex-A15出现了大小核架构(big.LITTLE),比如一个cluster全部是大核另一个全部是小核,因此cluster和cluster之间也需要cache的一致性,需要AMBA Coherency Extension来处理,在ARM中有现成的IP(在 IC 设计 里,IP 核 = 已经设计好、验证过的电路模块,可以作为“积木”直接拿来复用)可以使用,比如CCI-400和CCI-500
单核处理器(Cortex-A8)
- 单核,没有cache一致性问题
- Cache管理指令仅仅作用于单核
多核处理器(Cortex-A9 MP以及之后的处理器)
- 硬件上支持cache一致性
- Cache管理指令会广播到其他CPU核心
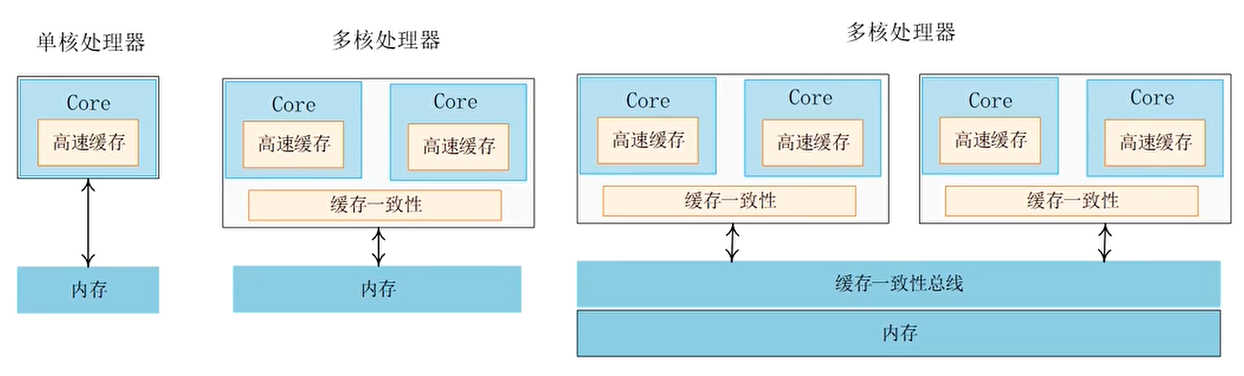
系统级别的cache一致性
- 系统cache一致性需要cache一致性内部总线(cache coherent interconnect)
- AMBA 4协议有ACE(AXI Coherency Extensions)
- AMBA 5协议有CHI
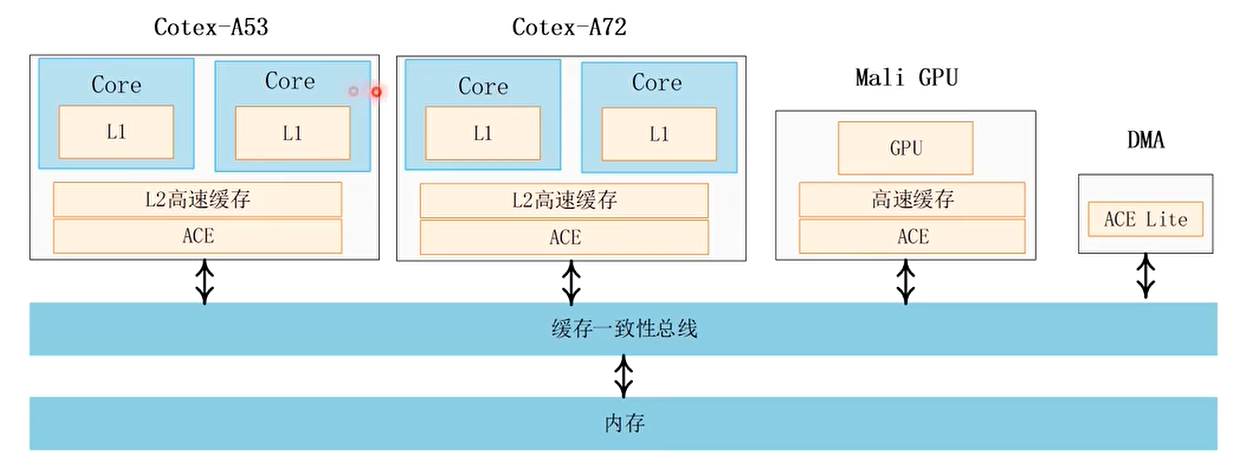
Cache一致性的解决方案
关闭cache
- 优点:简单
- 缺点:性能低下,功耗增加
软件维护cache一致性
- 优点:硬件RTL实现简单
- 缺点:
- 软件复杂度增加。软件需要手动clean/flush cache或者invalidate cache
- 增加调试难度
- 降低性能和增加功耗
硬件维护cache一致性
MESI协议来维护多核cache一致性。ACE接口来实现系统级别的cache一致性
- 优点:对软件透明
- 缺点:增加了硬件RTL实现难度和复杂度
多核之间的Cache一致性
多核CPU产生cache一致性的原因:同一个内存数据在多个CPU核心的L1 cache中存在多个不同的副本,导致数据不一致
维护cache一致性的关键是跟踪每一个cache line的状态,并根据处理器的读写操作和总线上的相应传输来更新cache line在不同CPU内核上的cache的状态,从而维护cache一致性
Cache一致性协议
监听协议 (snooping protocol),每个高速缓存都要被监听或者监听其他高速缓存的总线活动
目录协议 (directory protocol),全局统一管理高速缓存状态
MESI协议:
- 1983年,James Goodman提出Write-Once总线监听协议,后来演变成目前最流行的MESI协议
- 所有总线传输事务对于系统所有的其他单元是可见的,因为总线是一个基于广播通信的介质,因而可以由每个处理器的高速缓存来进行监听
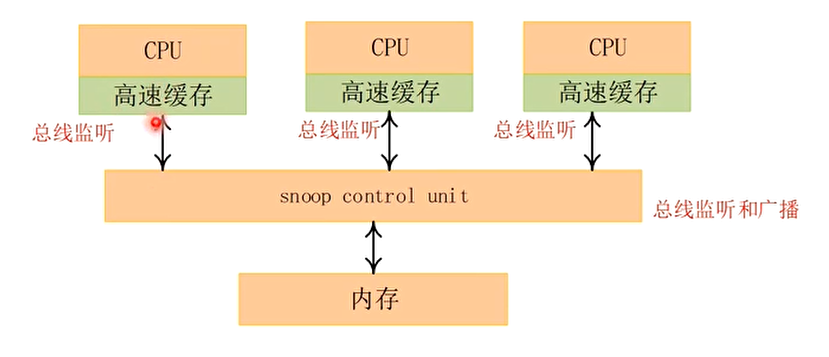
Snoop control unit单元实现总线监听和广播
每个CPU的L1 cache也实现了总线监听功能
MESI协议
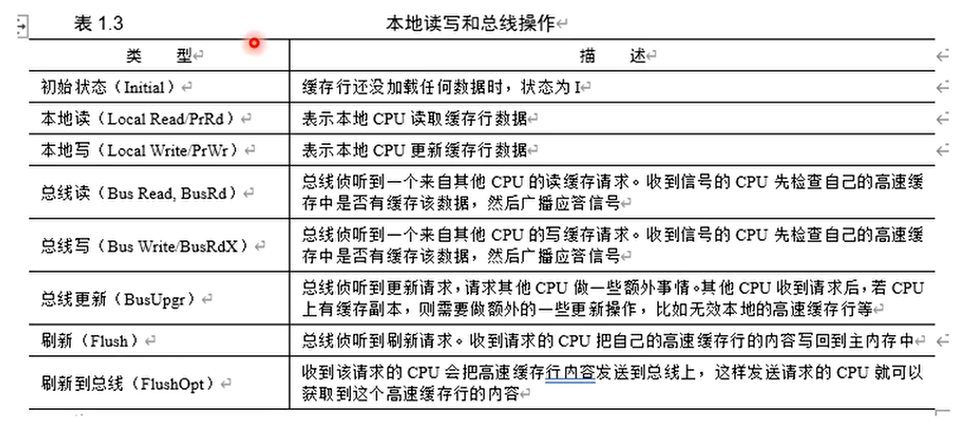
- 每个cache line有四个状态
- 修改(Modified)
- 独占(Exclusive)
- 共享(Shared)
- 失效(Invalid)

- 修改M和独占状态E的cache line,数据都是独有的,不同点在于修改状态的数据是脏的,和内存不一致,而独占态的数据是干净的和内存一致。脏的cache line会被回写到内存,其后的状态变成共享态。
- 共享状态S的cache line,数据和其他cache共享,只有干净的数据才能被多个cache共享
- I状态表示这个cache line无效
MESI的操作
MESI状态图
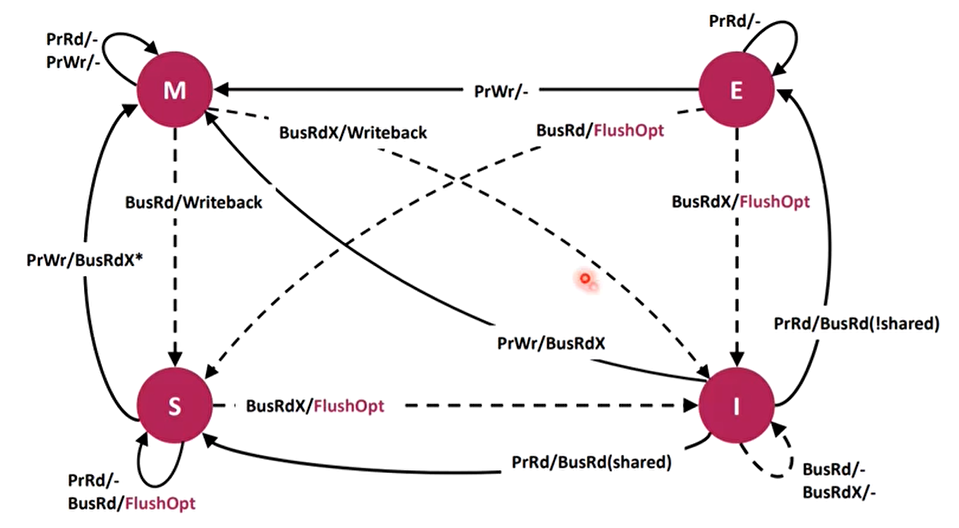
MESI主要解决的是每个CPU中的local cache之间的一致性问题
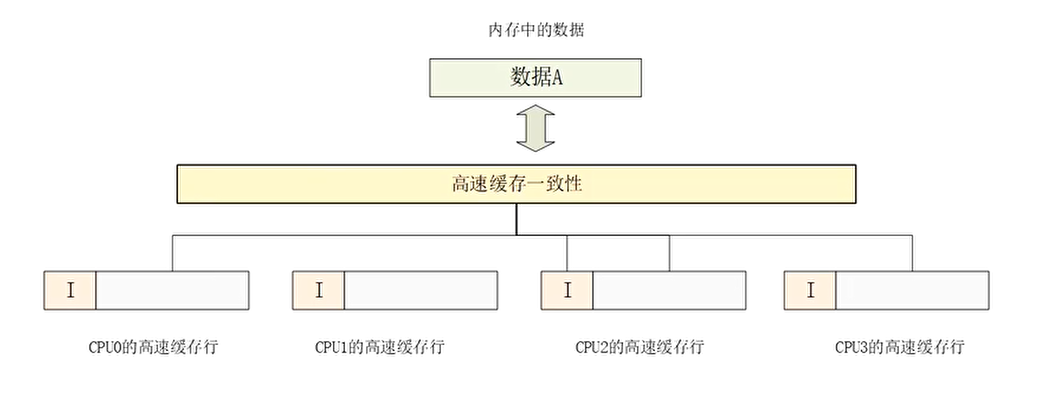
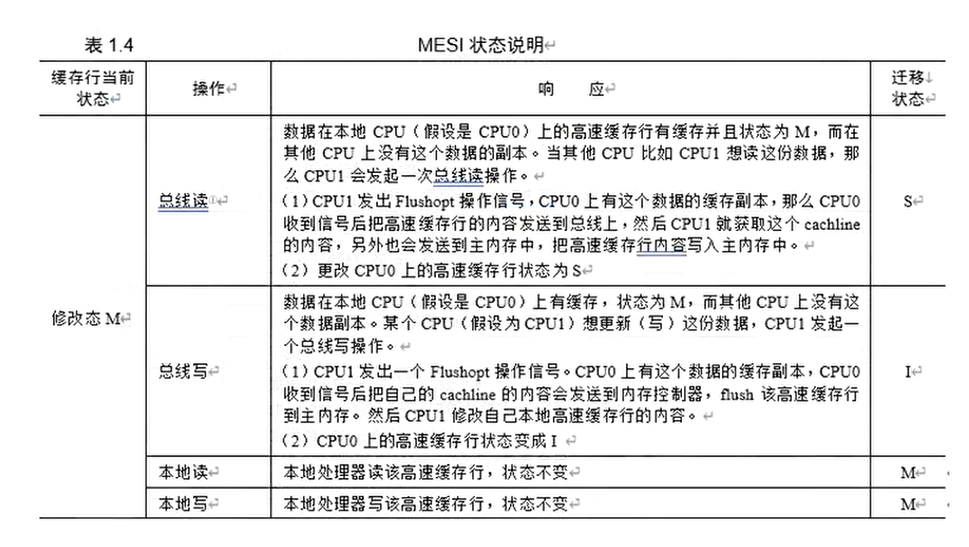

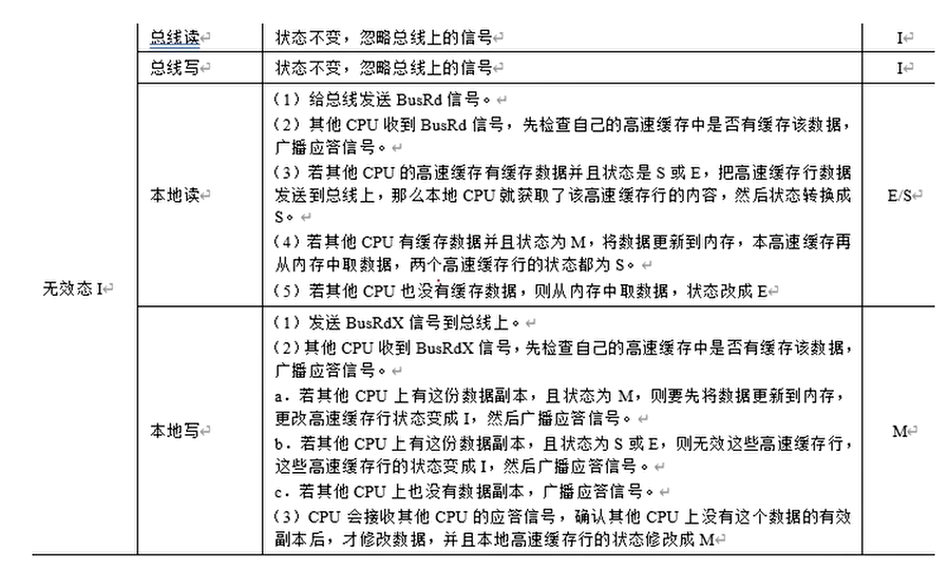
MESI协议分析的一个例子
- 假设系统中有4个CPU,每个CPU都有各自一级缓存,它们都想访问相同地址的数据A,大小为64字节。
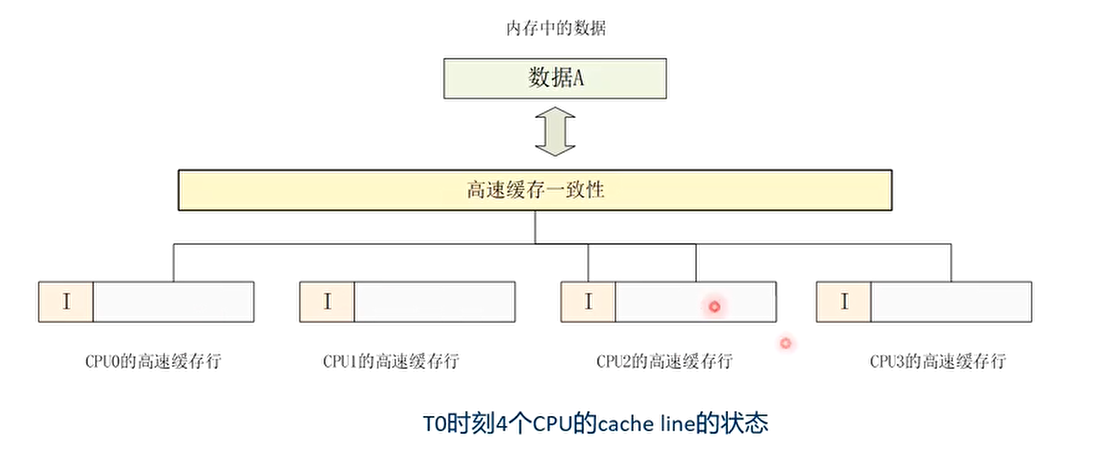
- T0时刻:4个CPU的L1 cache都没有缓存数据A,cache line的状态为I(无效的)
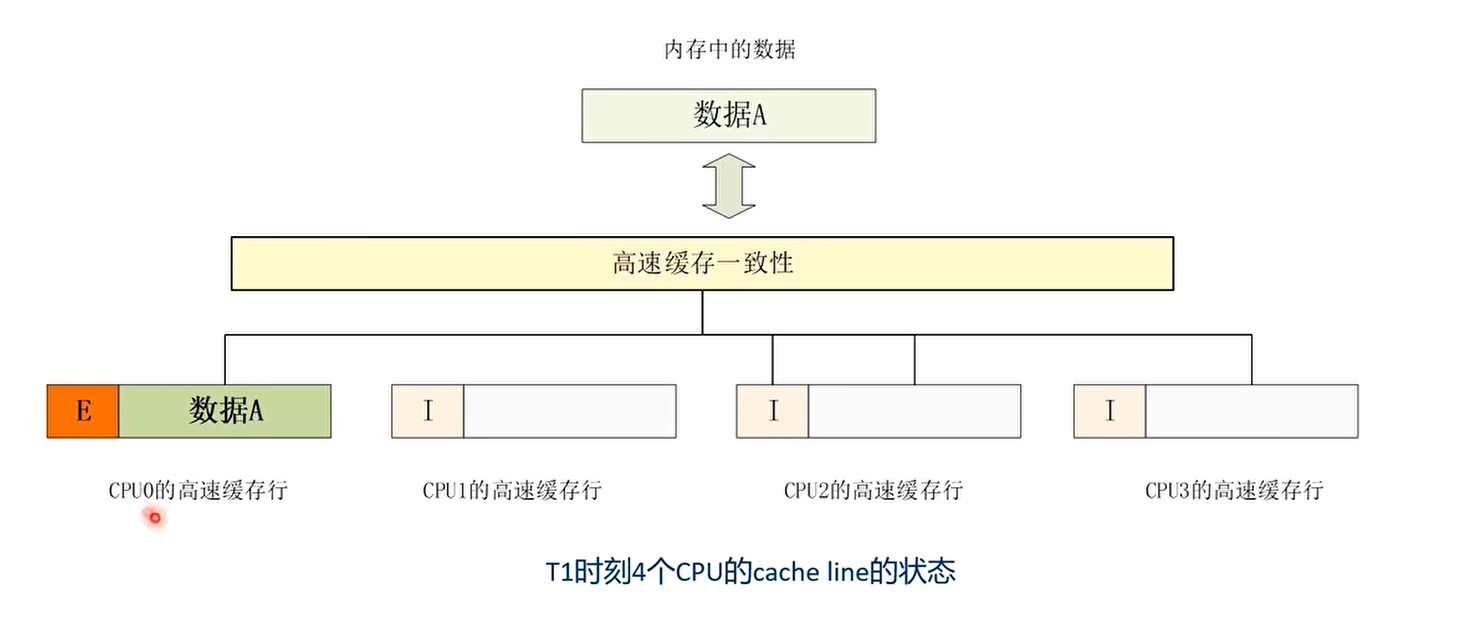
- T1时刻:CPU0率先发起访问数据A的操作
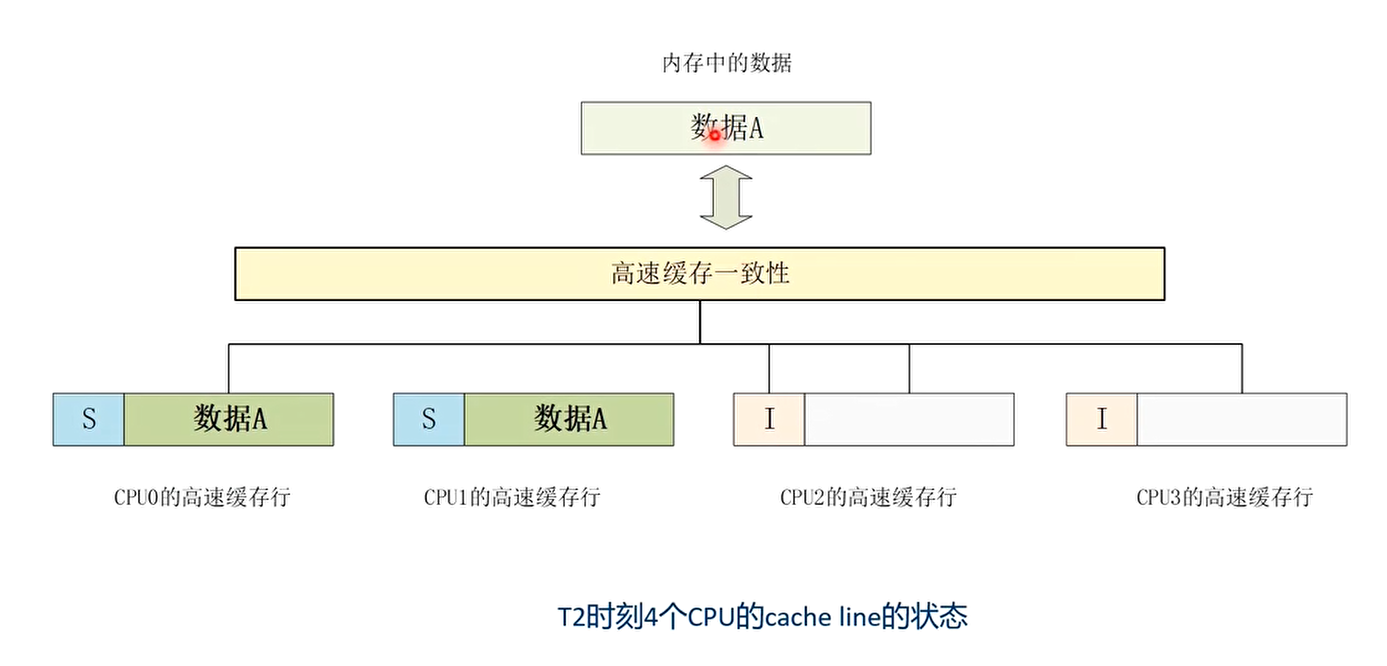
- T2时刻:CPU1也发起读数据操作
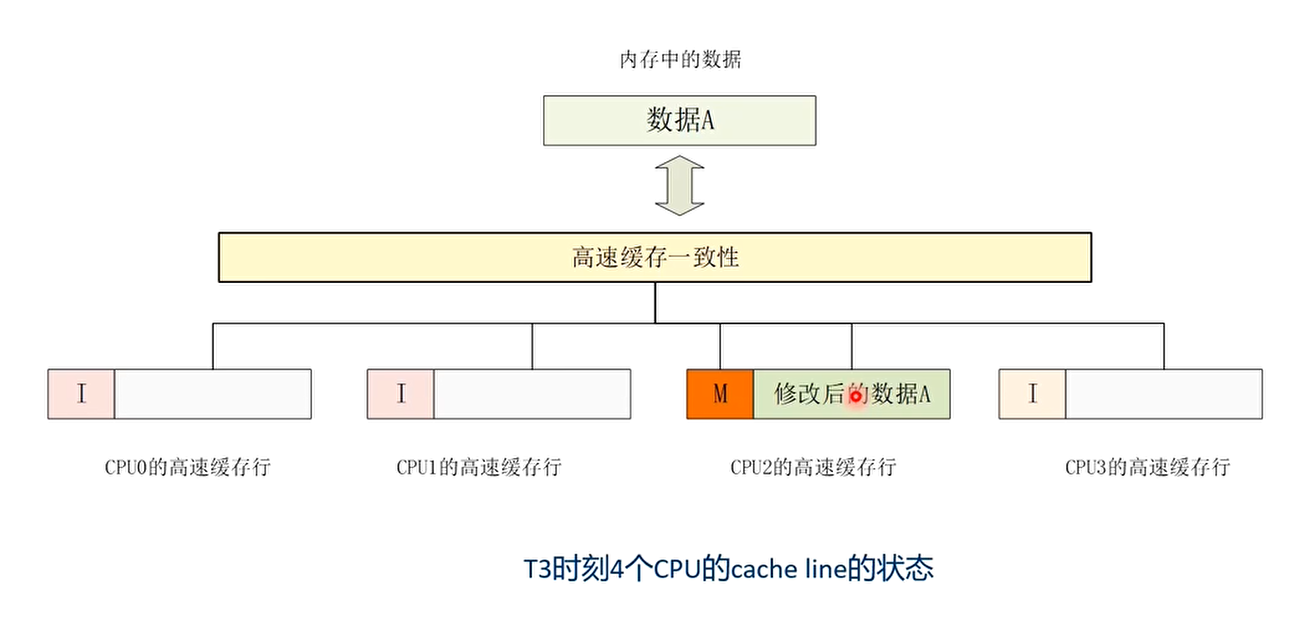
- T3时刻:CPU2的程序想修改数据A中的数据
- 请分析上述过程中,MESI状态的变化
T0时刻 4个CPU的L1 cache都没有缓存数据A,cache line的状态为I
T1时刻 CPU0率先发起访问数据A的操作
T2时刻 CPU1也发起读数据操作
T3时刻 CPU2的程序想修改数据A中的数据
高速缓存伪共享(False Sharing)
- 如果多个处理器同时访问一个缓存行中不同的数据时,带来了性能上的问题
- 举个例子:假设CPU0上的线程0想访问和更新struct data数据结构中的x成员,同理CPU1上的线程1想访问和更新struct data数据结构中的y成员,其中x和y成员都被缓存到同一个缓存行里。
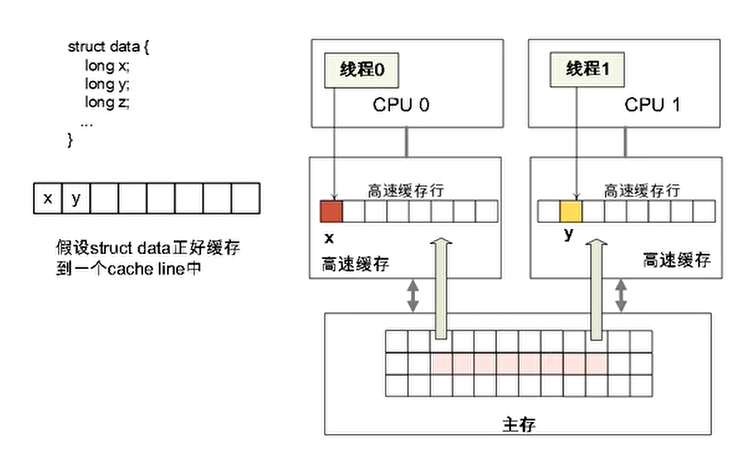
分析:
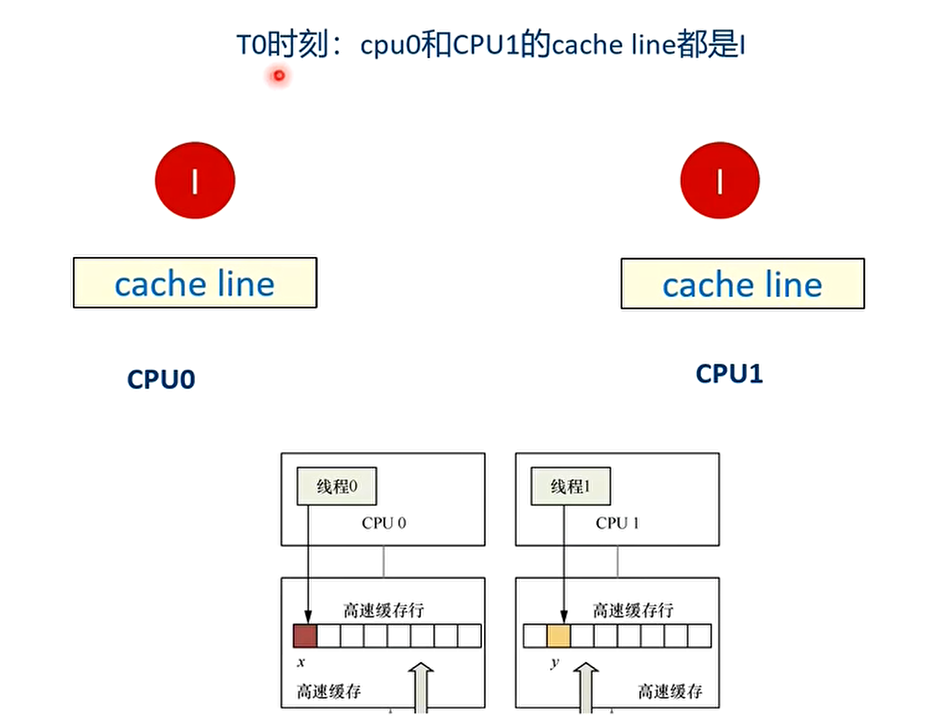
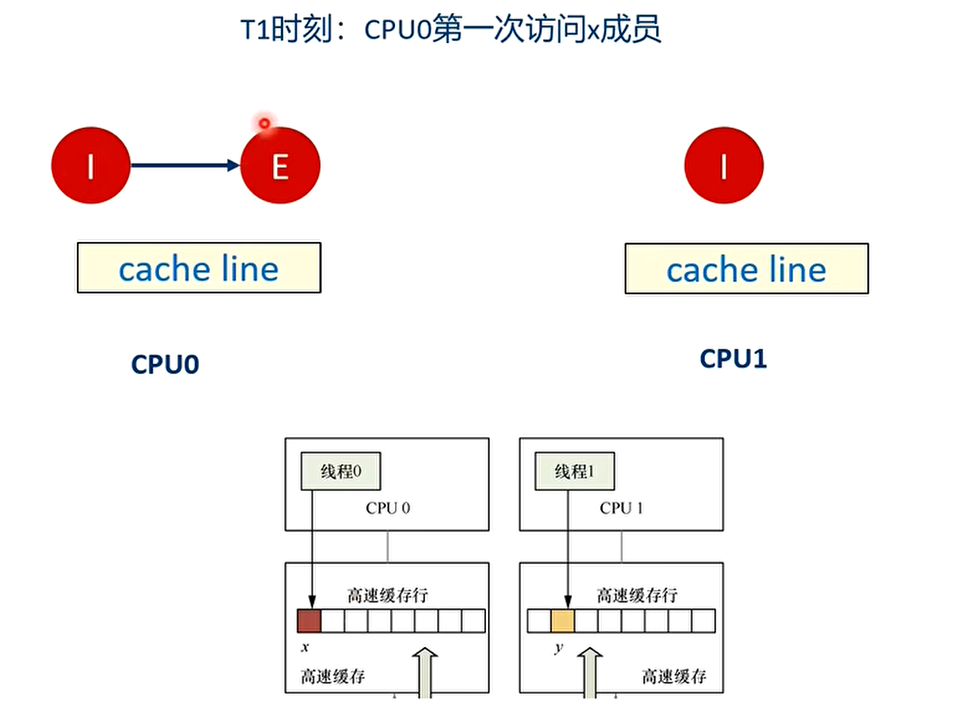
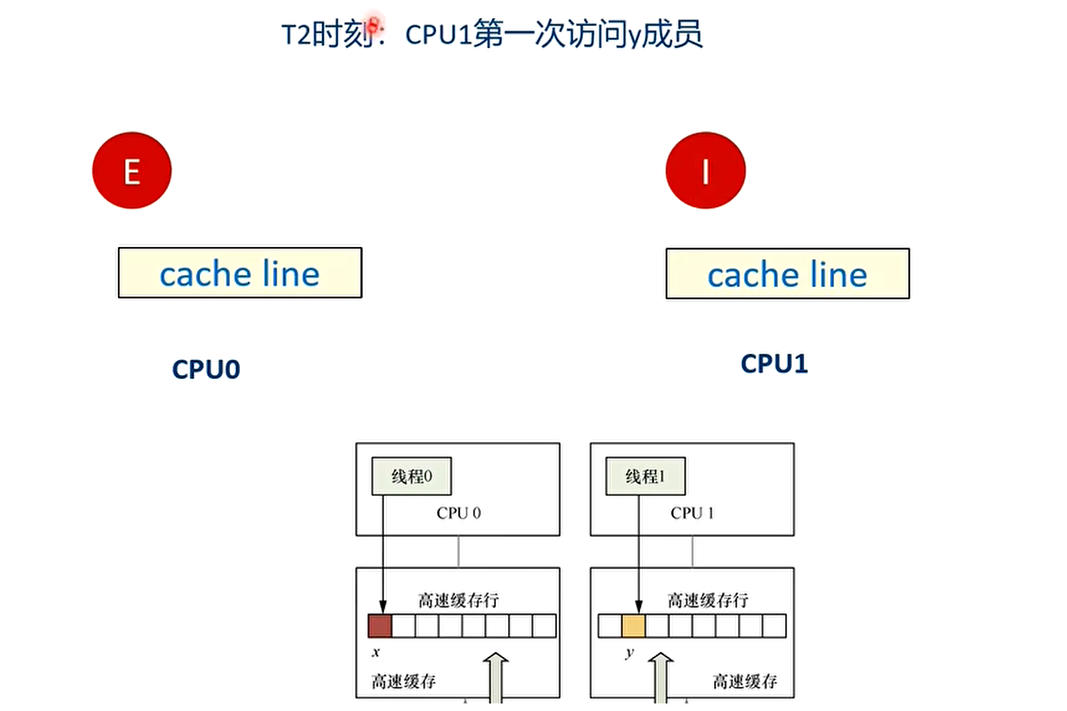
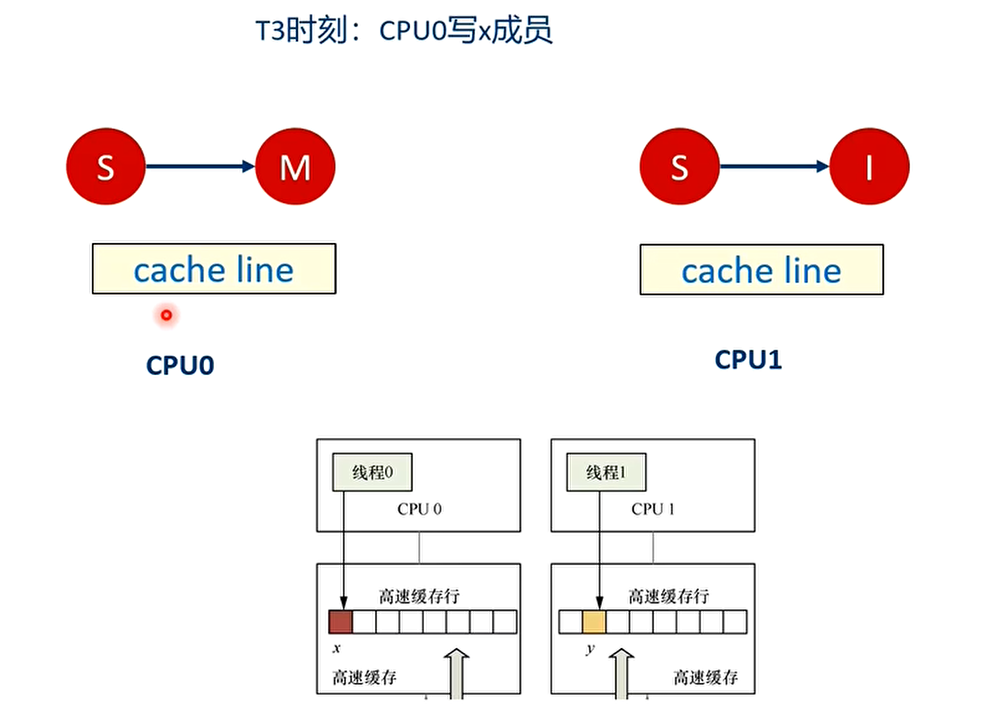
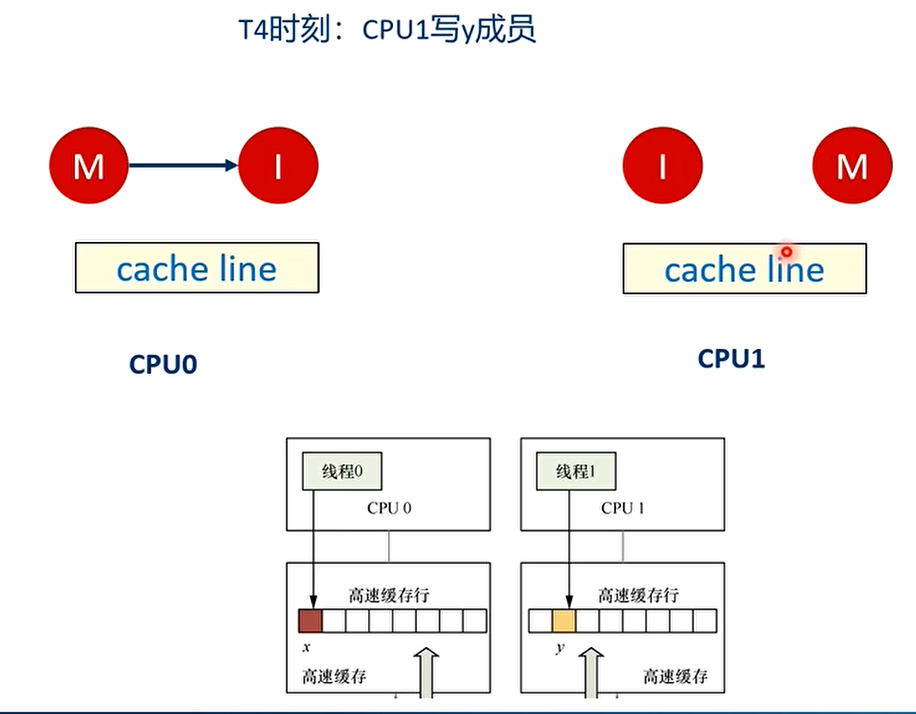
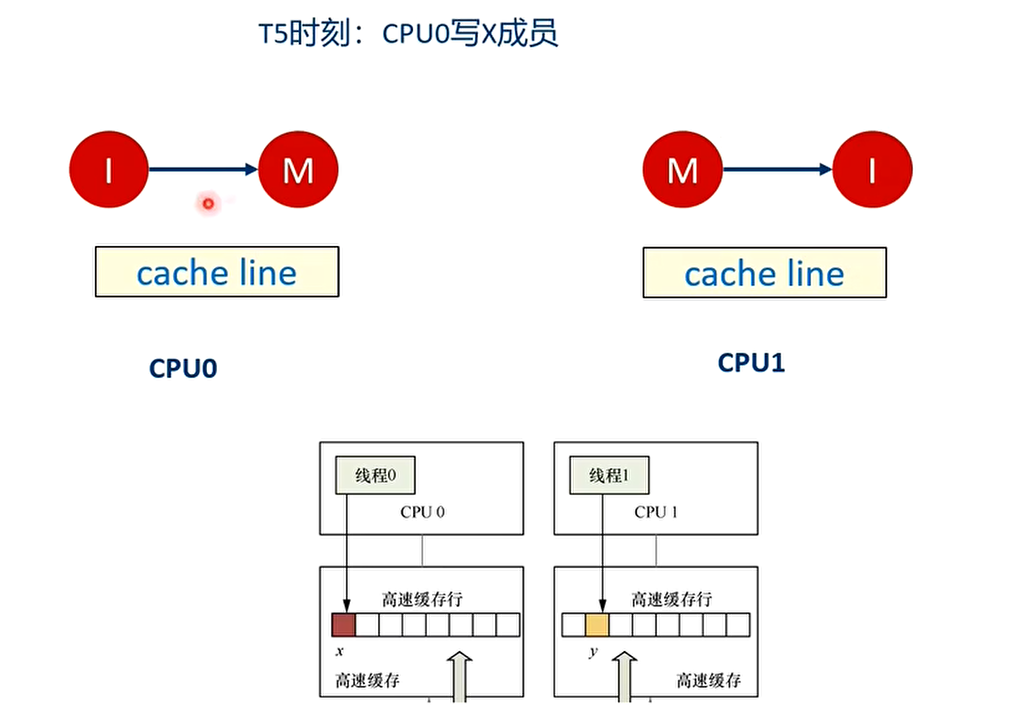
之后会不停地在T4和T5之间重复,争夺cache line,不断地让对方的cache line无效,触发高速缓存写回内存。
解决办法
- 高速缓存伪共享的解决办法就是让多线程操作的数据处在不同的告诉缓存行,通常可以采用高速缓存行填充(padding)技术或者高速缓存行对齐(align)技术,即让数据结构按照高速缓存行对齐,并且尽可能填充满一个高速缓存行大小。
- 下面一个代码定义一个counter_s数据结构,它的起始地址按照高速缓存行的大小对齐,数据结构的成员通过pad[4]来填充。这样,counter_s的大小正好是一个cache line的大小,64个字节,而且它的起始地址也是cache line对齐
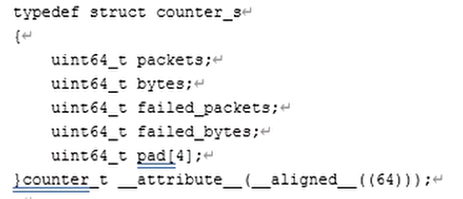
尽可能让counter_s独占一个cache line而不和其他数据结构共享一个cache line
MOESI协议
The ARMv8 processors use the MOESI protocol
Modified
The most up-to-date version of the cache line is within this cache.
No other copies of the memory location exist within other caches.
The contents of the cache line are no longer coherent with main memory.
Owned
This describes a line that is dirty and in possibly more than one cache.
A cache line in the owned state holds the most recent, correct copy of the data.
Only one core can hold the data in the owned state. The other cores can hold the data in the shared state.
Exclusive
- The cache line is present in this cache and coherent with main memory.
- No other copies of the memory location exist within other caches.
Shared
The cache line is present in this cache and is not necessarily coherent with memory, given that the definition of Owned allows for a dirty line to be duplicated into shared lines.
It will, however, have the most recent version of the data.
Copies of it can also exist in other caches in the coherency scheme.
Invalid
- The cache line is invalid.
The following rules apply for the standard implementation of the protocol:
- A write can only be performed if the cache line is in a Modified or Exclusive state. If it is
in a Shared state, all other cached copies must be invalidated first. A write moves the line
into a Modified state. - A cache can discard a shared line at any time, changing it to an Invalid state.
- A Modified line is written back first.
- If a cache holds a line in a Modified state, reads from other caches in the system receive
the updated data from the cache. Conventionally, this is achieved by first writing the data
to main memory and then changing the cache line to a Shared state, before performing a
read. - A cache that has a line in an Exclusive state must move the line to a Shared state when
another cache reads that line. - A Shared state might not be precise. If one cache discards a Shared line, another cache
might not be aware that it can now move the line to an Exclusive state.
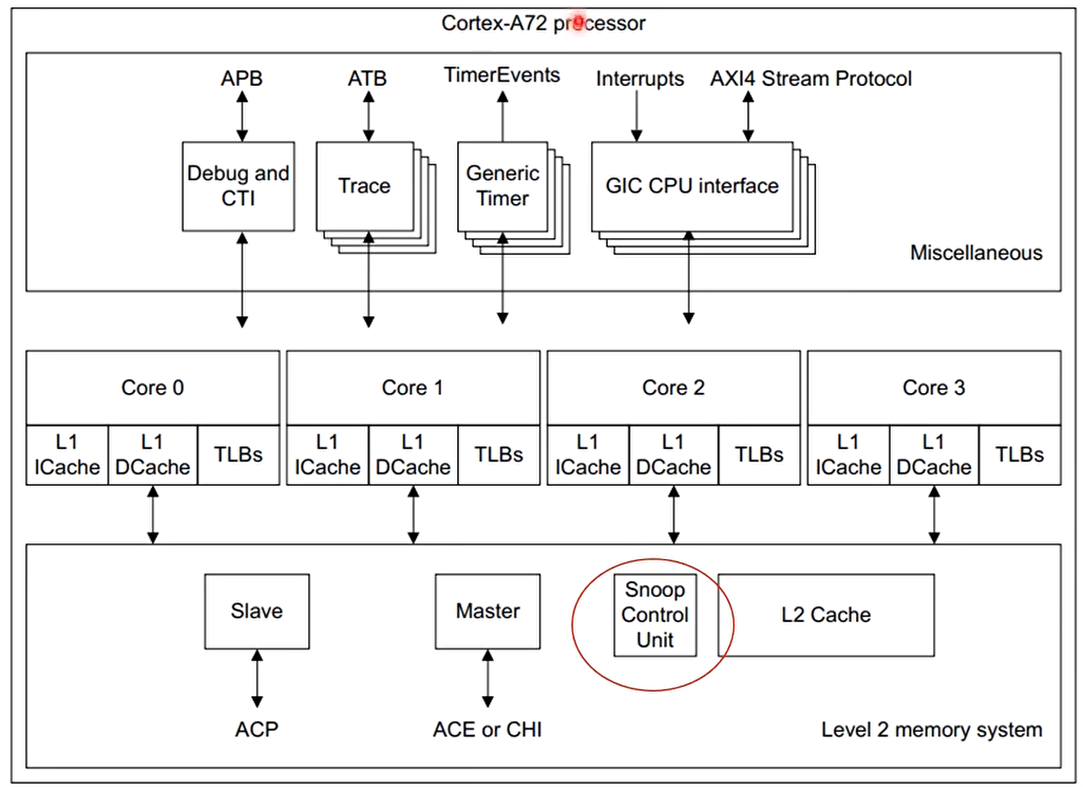
Snoop Control Unit(SCU)
The processor cluster contains a Snoop Control Unit (SCU) that contains duplicate copies of the tags stored in the individual L1 Data Caches. The cache coherency logic therefore:
- Maintains coherency between L1 data caches.
- Arbitrates accesses to L2 interfaces, for both instructions and data.
- Has duplicated Tag RAMs to keep track of what data is allocated in each core’s data.
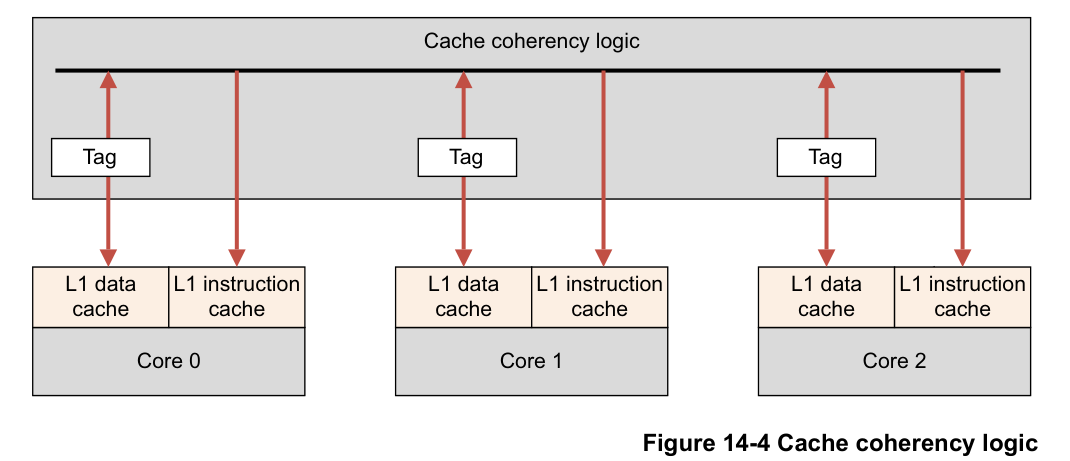
图中的每个内核都有自己的数据和指令缓存。缓存一致性逻辑包含来自 D 缓存的标签的本地副本。但是,指令缓存不参与一致性。数据缓存和一致性逻辑之间有 2 路通信。ARM 多核处理器还实现了优化,可以直接在参与的 L1 缓存之间复制干净数据和移动脏数据,而无需访问和等待外部存储器。此活动由 SCU 在多核系统中处理。
Snoop Control Unit (SCU) 维护每个内核的 L1 数据缓存之间的一致性,并负责管理以下互连操作:
- Arbitration.
- Communication.
- Cache-2-cache and system memory transfers.
该处理器还将这些功能提供给其他系统加速器和非缓存 DMA 驱动的外设,以提高性能并降低系统范围的功耗。
这种系统一致性还降低了在每个操作系统驱动程序内维护软件一致性时所涉及的软件复杂性。每个核心都可以单独配置为参与或不参与数据缓存一致性管理方案。处理器内部的 SCU 设备自动维护集群内内核之间的 1 级数据缓存一致性。
由于可执行代码的更改频率要低得多,因此此功能不会扩展到 L1 指令缓存。一致性管理是使用基于 MOESI的协议实现的,经过优化以减少外部存储器访问的数量。为了使一致性管理对内存访问有效,以下所有条件都必须为真:
- SCU 通过位于私有内存区域的控制寄存器启用。SCU 具有可配置的访问控制,限制哪些处理器可以对
其进行配置。 - MMU 已启用。
- 被访问的页面被标记为 Normal Shareable,缓存策略为 write-back, write-allocate。然而,设备和强排序内存不可缓存,从内核的角度来看,直写缓存的行为类似于未缓存的内存。
SCU 只能在单个集群内保持一致性。如果系统中有额外的处理器或其他总线主控器,当它们与 MP 块共享内存时,需要明确的软件同步
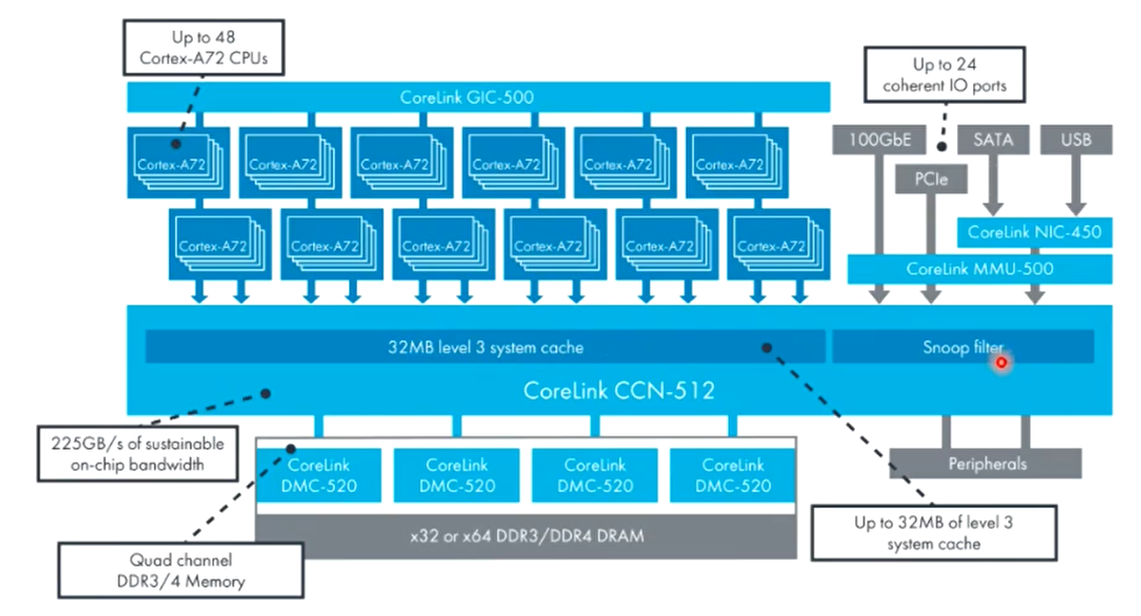
系统间的Cache一致性

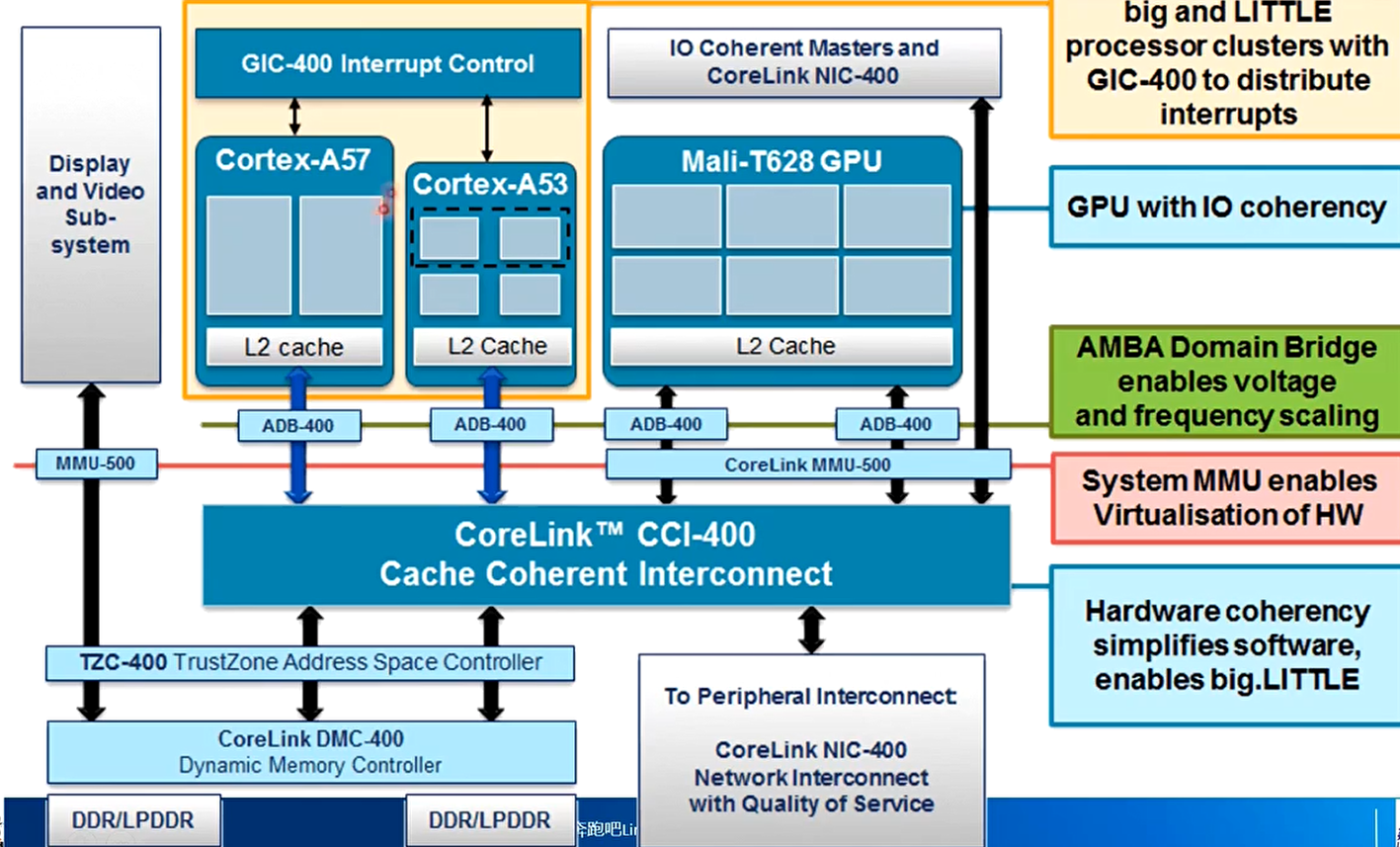
ARM面向服务器市场的CCI是CoreLink CCN

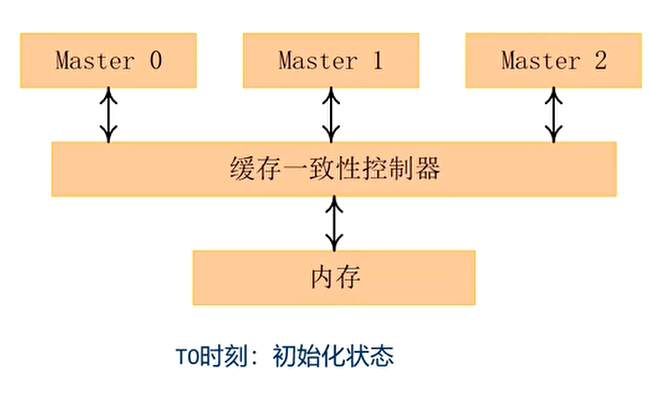
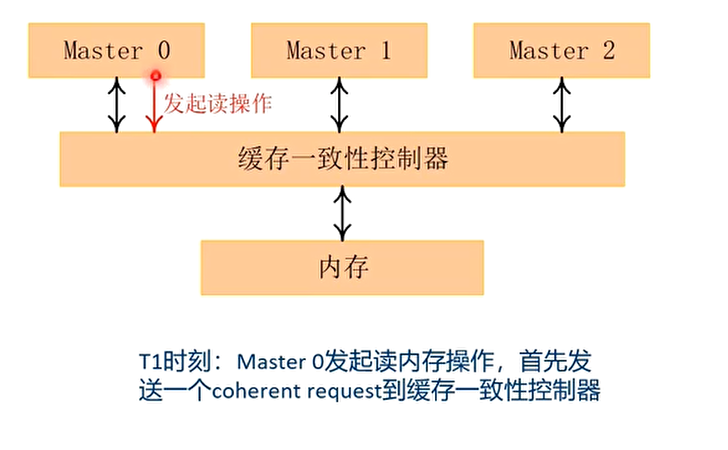
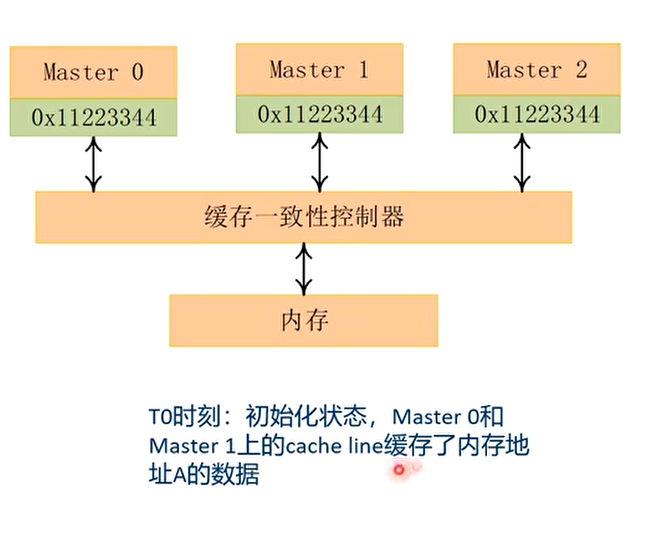
读数据的例子
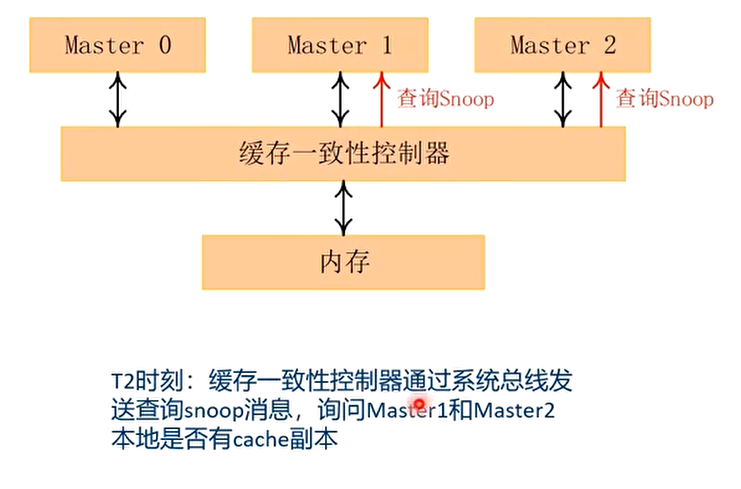
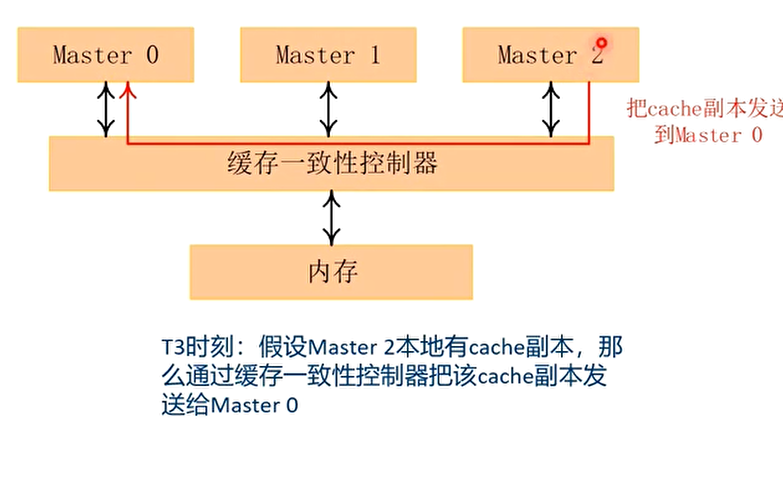
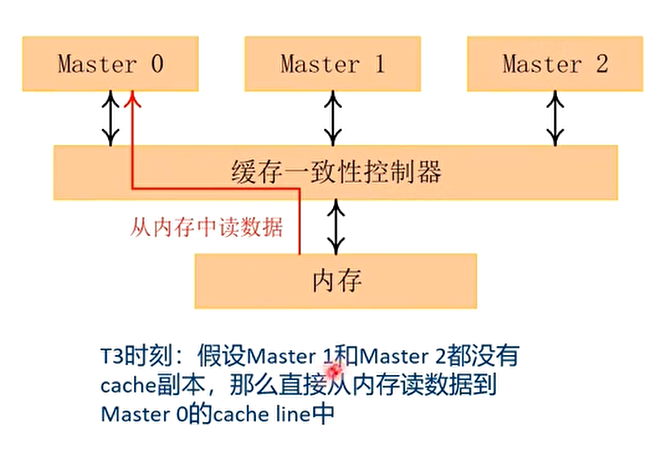
写数据的例子
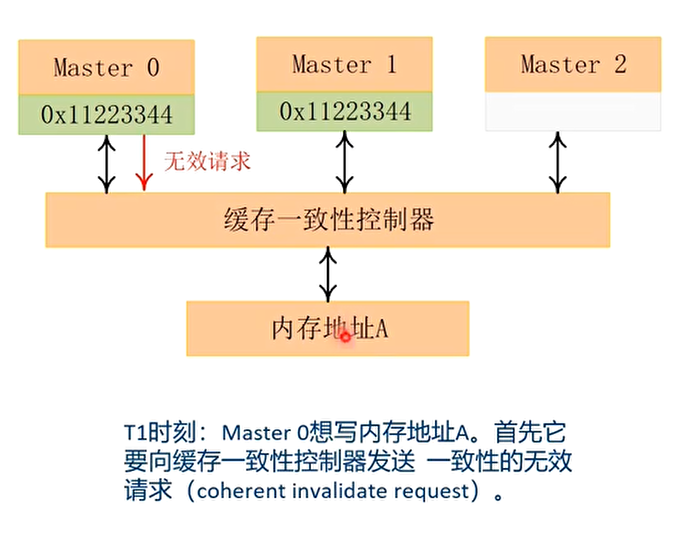
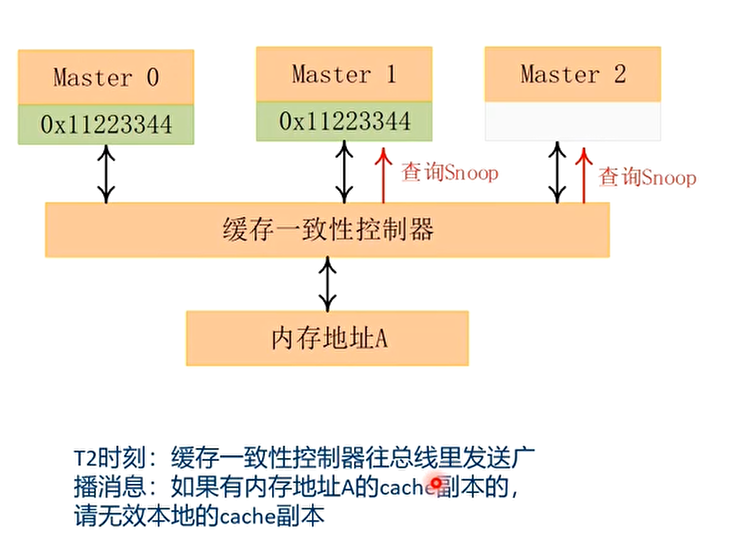
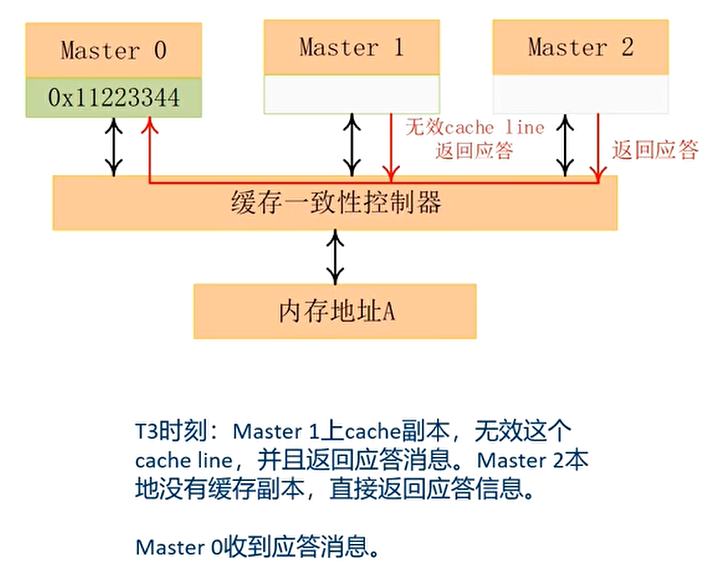
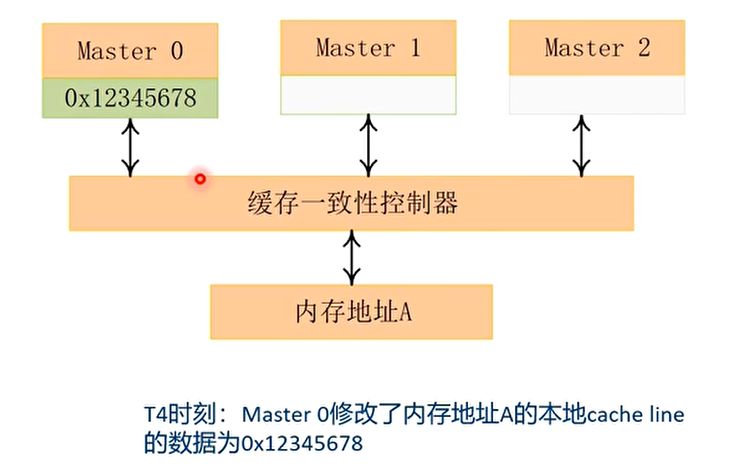
Cache一致性的案例
案例1:高速缓存伪共享的避免
- 一些常用的数据结构在定义时就约定数据结构以一级缓存对齐。例如使用如下的宏来让数据结构首地址以L1 cache对齐
1 |
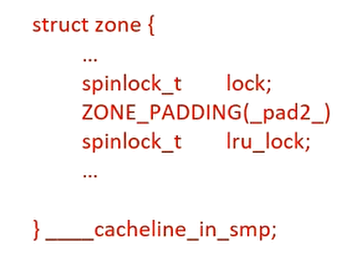
数据结构频繁访问的成员可以单独占用一个高速缓存行,或者相关的成员在高速缓存行中彼此错开,以提高访问效率。例如struct zone数据结构使用ZONE_PADDING技术(填充字节的方式)来让频繁访问的成员在不同的cache line中

案例2:DMA的cache一致性
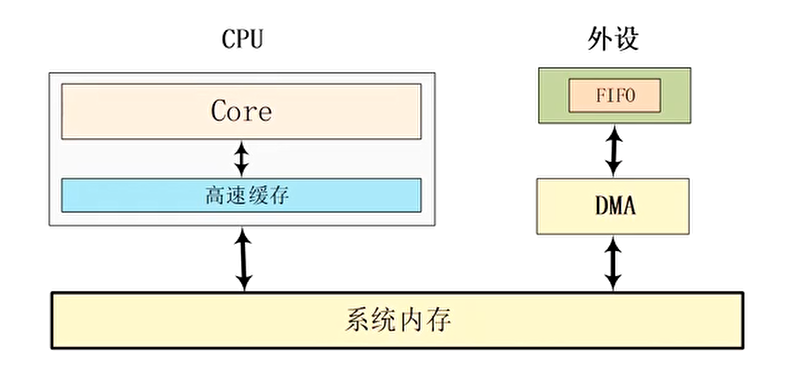
DMA (Direct Memory Access)直接内存访问,它在传输过程中时不需要CPU干预的,可以直接从内存中读写数据
- DMA产生cache一致性问题的原因:
- DMA直接操作系统总线来读写内存,而CPU并不感知
- 如果DMA修改的内存地址,在CPU的cache中有缓存,那么CPU并不知道内存数据被修改了,CPU依然去访问cache的旧数据,导致Cache一致性问题
DMA的cache一致性解决方案
硬件解决办法,需要ACE总线支持(咨询SoC vendor)
使用non-cacheable的内存来进行DMA传输
- 缺点:在不使用DMA的时候,CPU访问这个buffer会导致性能下降
软件干预cache一致性,根据DMA传输数据的方向,软件来维护cache一致性
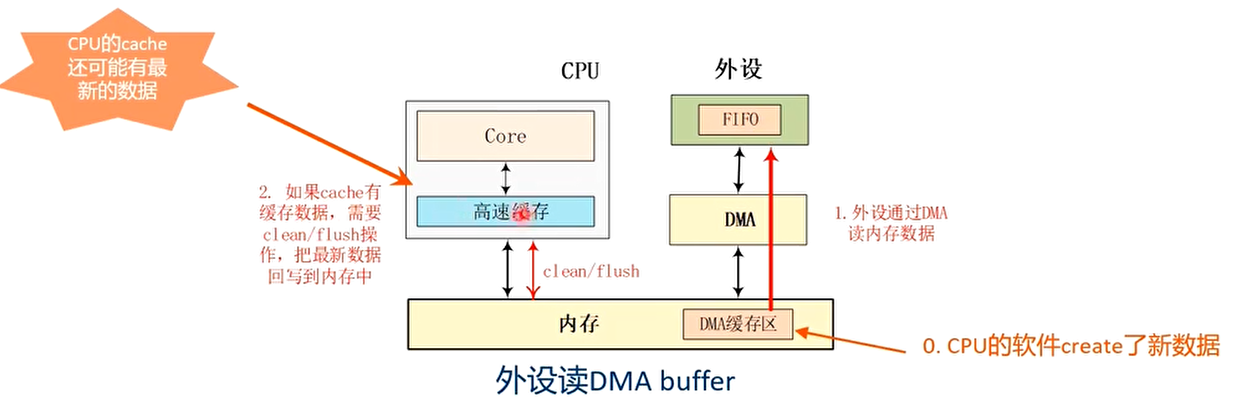
Case 1: 内存->设备FIFO (设备例如网卡,通过DMA读取内存数据到设备FIFO)
- 在DMA传输之前,CPU的cache可能缓存了内存数据,需要调用cache clean/flush操作,把cache内容写入到内存中,因为CPU cache里可能缓存了最新的数据。
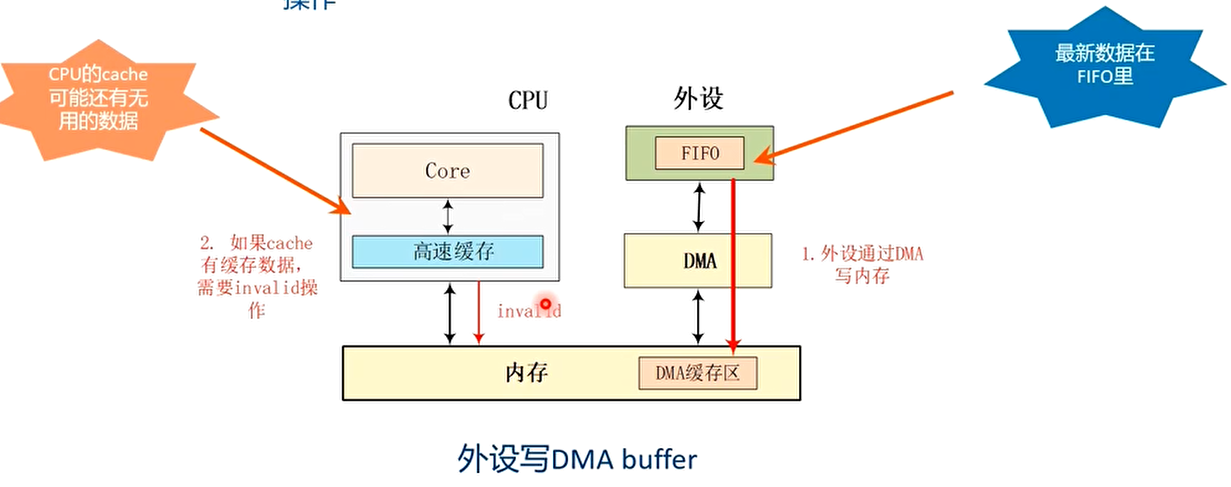
Case 2: 设备FIFO->内存(设备把数据写入到内存中)
- 在DMA传输之前,需要把cache做invalid操作。因为此时最新数据在设备FIFO中,CPU缓存的cache数据是过时的,一会要写入新数据所以做invalid操作
案例3:self-modifying code
指令cache和数据cache是分开的。指令cache一般只读
指令cache和数据cache的一致性问题。指令通常不能修改,但是在某些特殊情况下指令存在被修改的情况
self-modifying code,在执行过程中修改自己的指令(防止软件破解,或者gdb调试代码动态修改程序),过程如下
- 要把修改的指令,加载到数据cache里
- 程序(CPU)修改新指令,数据cache里缓存了最新指令
存在问题:
- 指令cache依然缓存了旧的指令,新指令还在数据cache里

解决思路:
- 使用cache clean操作,把cache line的数据写回到内存
- 使用DSB指令保证其他观察者看到clean操作已经完成
- 无效指令cache
- 使用DSB指令确保其他观察者看到无效操作已经完成
- ISB指令让程序重新预取指令

Cache实验二:false sharing

1 |
|

Cache实验三:flush cache实验

结果:

1 | .global get_cache_line_size |
armv8芯片手册Cache相关章节
ARM Architecture Reference Manual Armv8, for Armv8-A architecture profile
B2.4 Caches and memory hierarchy
D4.4 Cache Support
D5.11 Caches in a VMSAv8-64 implementation
ARM Cortex-A Series Programmer’s Guide for ARMv8-A
- Chapter 11 Cache
ARM Cortex-A72 MPCore Processor Technical Reference Manual
- 6: Level 1 Memory System
- 7:Level 2 Memory System