ARM Cache
时间轴
2025-10-25
init
参考文档:

经典的cache架构:
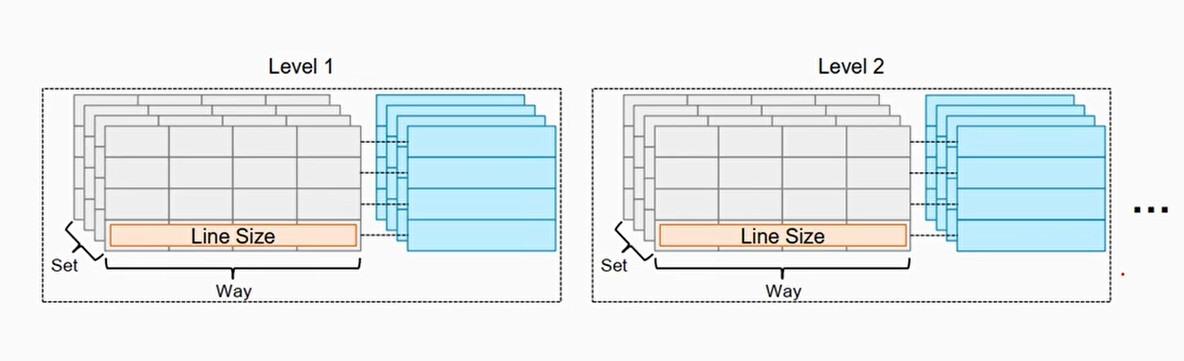
Cache内部架构图
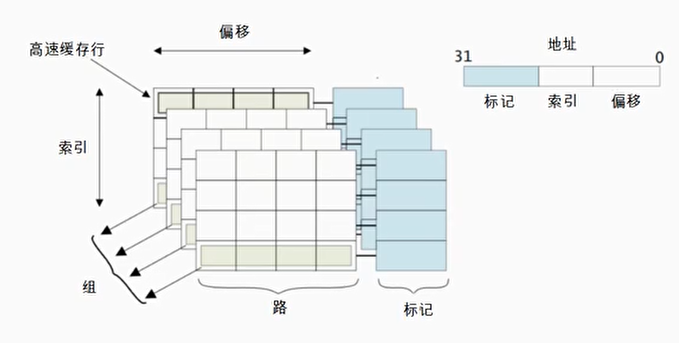
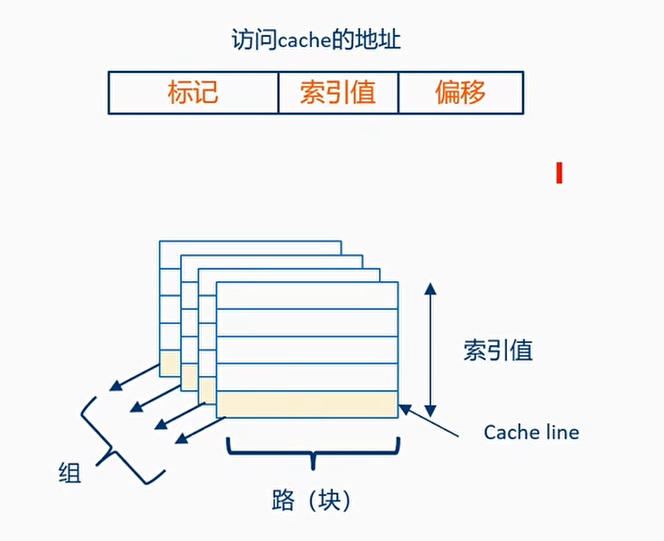
- 高速缓存行:高速缓存中的最小的访问单元
- 索引(index)域: 用于索引和查找是在高速缓存中的哪一行
- 标记(tag):高速缓存地址编码的一部分,通常是高速缓存地址的高位部分,用来判断高速缓存行缓存的数据地址是否和处理器寻址地址一致
- 偏移(offset): 高速缓存行中的偏移。处理器可以按字(word)或者字节(Byte)来寻址高速缓存行的内容
- 组(set):相同索引域的高速缓存行组成一个组
- 路(way): 在组相联的高速缓存中,高速缓存被分成大小相同的几个块
组的作用主要是防止cache的”颠簸”
Cache的类型
ARM64 架构上主要有:
- Instruction Cache (I-Cache)
专门缓存指令流,加快取指速度。 - Data Cache (D-Cache)
缓存数据读写(Load/Store)。 - Unified Cache
一些层级(如 L2、L3)往往是统一缓存(既存指令也存数据),不像 L1 那样严格分指令/数据。
有时称既有I-Cache也有D-Cache的为Separate Cache,它是分离缓存结构:既有独立的 I-Cache,又有独立的 D-Cache。典型于 L1 Cache。
Cache映射方式
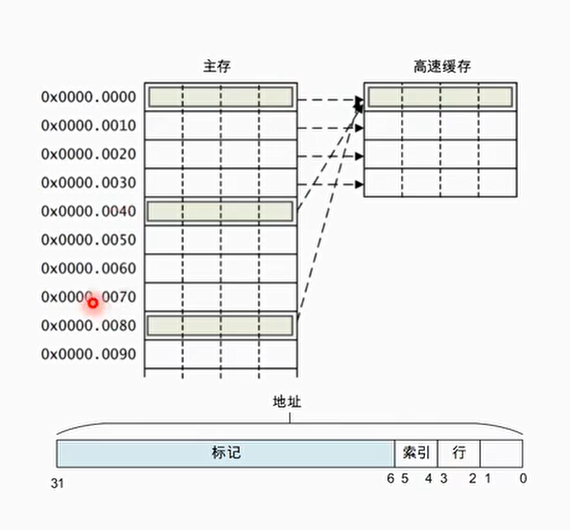
直接映射
每个组只有一行高速缓存行时,称为直接映射高速缓存(direct-mapping)
例子:

0x00,0x40,0x80都映射了同一个高速缓存行里,会频繁发生高速缓存替换性能较低
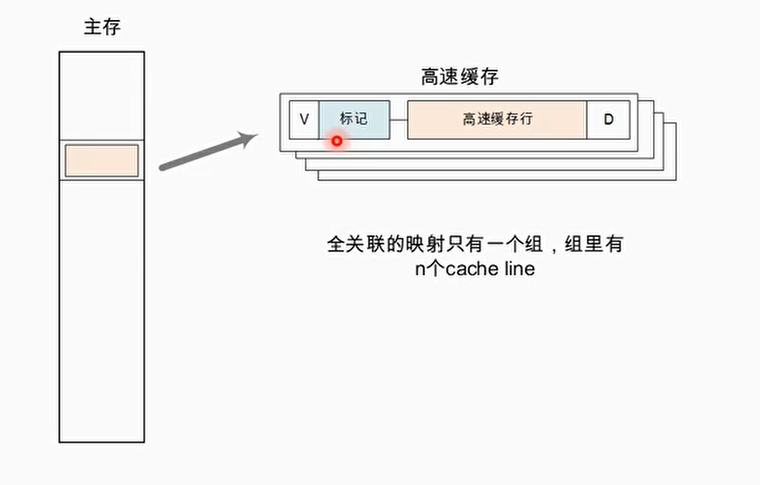
全相联
当cache只有一个组,即主存中只有一个地址与n个cache line对应,成为全相联
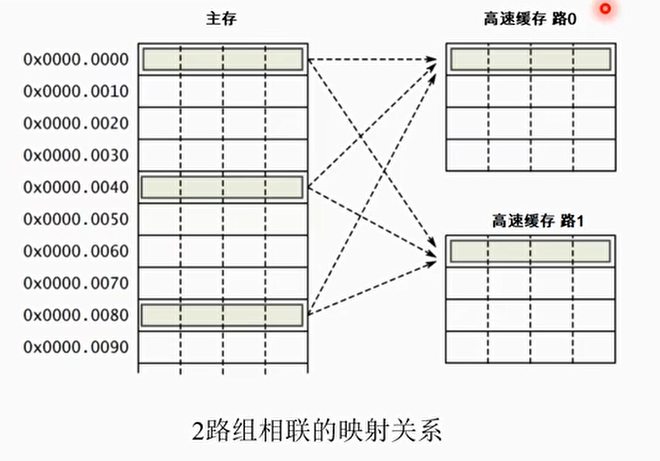
组相联
- 一个二路相联的高速缓存为例,每一路包括4个高速缓存行,那么每两个组有两个高速缓存行可以提供高速缓存行的替换
- 减小高速缓存的颠簸
举例:
- 高速缓存的总大小是32KB,并且是4路(way),所以每一路的大小为8KB:way_size = 32/4 = 8(KB)
- 高速缓存行的大小为32字节,所以每一路包含的高速缓存行数量为:num_cache_line = 8KB/32B=256
由此可以画出高速缓存的结构图: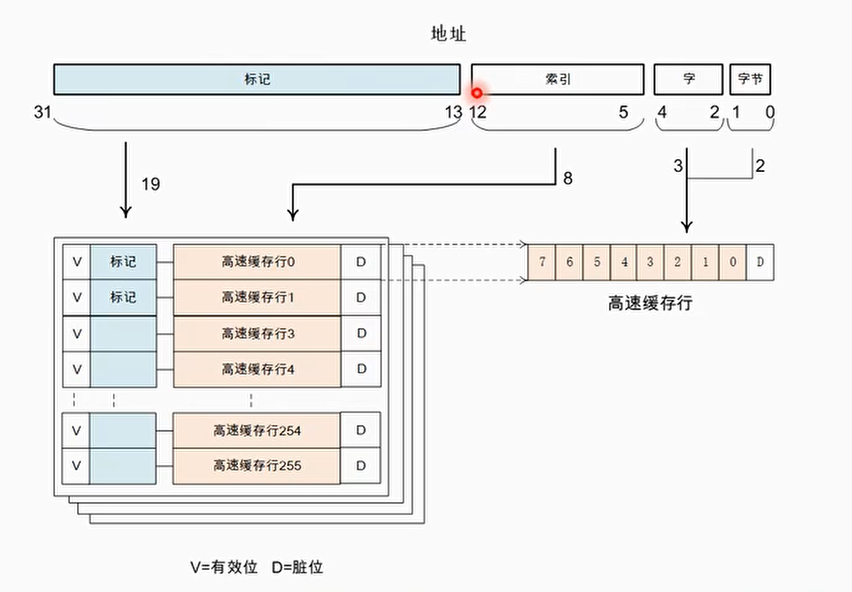
索引值为12-5+1 = 8位,共2^8=256,可以索引256个cache line
1 | Cache Level (L1 / L2 / L3) |
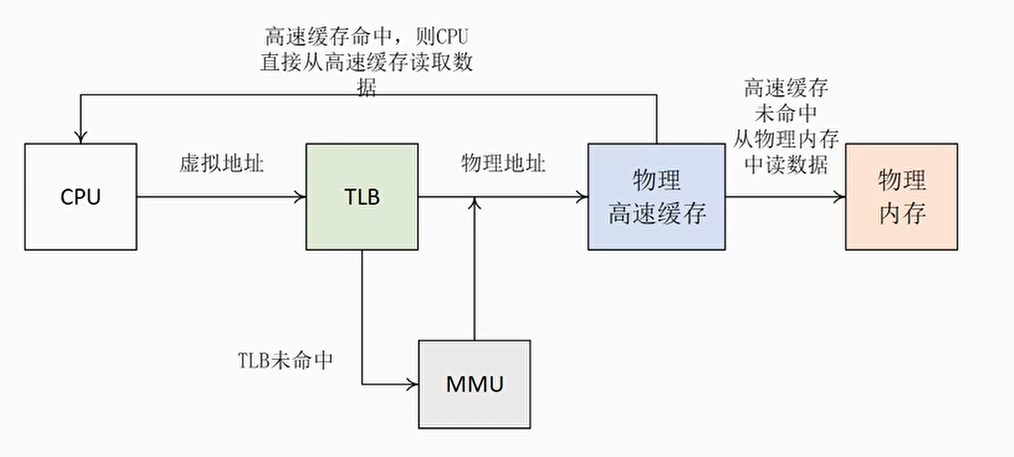
物理高速缓存
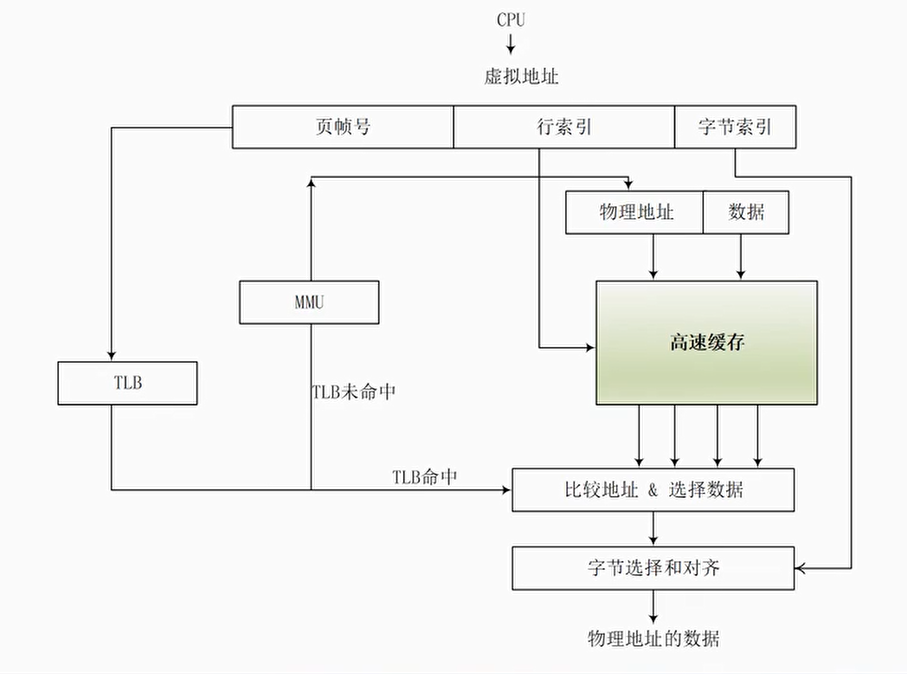
当处理器查询MMU和TLB得到物理地址之后,使用物理地址去查询高速缓存
缺点:处理器在查询MMU和TLB后才能访问高速缓存,增加了流水线的延迟
虚拟高速缓存
处理器使用虚拟地址来寻址高速缓存
缺点:会引入不少问题:
- 重名(Aliasing)问题
- 同名(Homonyms)问题
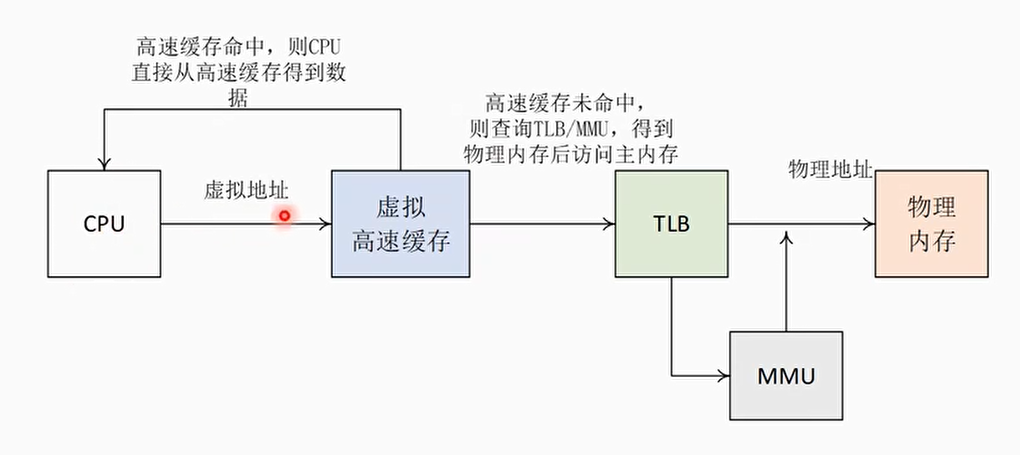
别名问题(Aliasing)
也称重名问题
- 在操作系统中,多个不同的虚拟地址可能映射相同的物理地址。由于采用虚拟高速缓存架构,那么这些不同的虚拟地址会占用高速缓存中不同的高速缓存行,但是它们对应的是相同的物理地址
- 举个例子:VA1和VA2都映射到PA,在cache中有两个cache line缓存了VA1和VA2
- 当程序往VA1写入数据时,VA1对应的高速缓存行以及PA的内容会被更改,但是VA2还保存着旧数据。这样一个物理地址在虚拟高速缓存中就保存了两份数据,这样会产生歧义
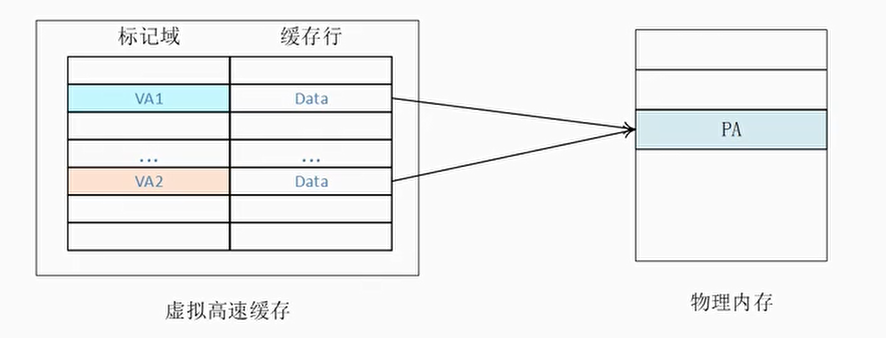
同名问题(Homonyms)
- 相同的虚拟地址对应着不同的物理地址,因为操作系统中不同的进程会存在很多相同的虚拟地址,而这些相同的虚拟地址在经过MMU转换后得到不同的物理地址,这就产生了同名问题
- 同名问题最常见的地方是进程切换。当一个进程切换到另外一个进程时,新进程使用虚拟地址来访问高速缓存的话,新进程会访问到旧进程遗留下来的高速缓存,这些高速缓存数据对于新进程来说是错误和没用的。解决办法是在进程切换时把旧进程遗留下来的高速缓存都置为无效,这样就能保证新进程执行时得到一个干净的虚拟高速缓存。
高速缓存分类
VIVT (Virtual Index Virtual Tag): 使用虚拟地址的索引域和虚拟地址的标记域,相当于是虚拟高速缓存
- CPU 在访问缓存时,不需要先进行地址转换(虚拟地址 → 物理地址),直接用虚拟地址来决定缓存行(index)和匹配标记(tag)。
- 存在别名问题 (Synonym/Aliasing):不同虚拟地址映射到同一物理地址时,会在缓存中出现多份数据,可能导致数据不一致。
PIPT (Physical Index Physical Tag): 使用物理地址索引域和物理地址标记域,相当于是物理高速缓存
- CPU 先通过 MMU 将虚拟地址转换成物理地址,然后用物理地址进行缓存索引和匹配。
- 不存在别名问题
- 常见L2 Cache
VIPT (Virtual Index Physical Tag): 使用虚拟地址索引域和物理地址的标记域
- CPU 使用虚拟地址的低位部分作为缓存索引(Index)。使用物理地址作为标记(Tag),用于匹配判断。因为缓存行对齐(通常是 64 字节或 128 字节),虚拟地址低位与物理地址低位一致,所以可以安全地用虚拟地址索引。
- 避免了别名问题,因为使用了物理地址作为标记
- 受 Page Size 限制:虚拟索引长度必须 ≤ 页面偏移位数,否则不同页的同一虚拟索引会冲突。(VIPT 用虚拟地址的低位索引缓存行)
- 常见L1 Cache
VIPT工作过程
一般视角下:
1 | VA = 虚拟页号 (VPN) | 页内偏移 (PO) |
VIPT视角下PO分成:
1 | PO = Cache Index | Cache Line Offset |
- VIPT 缓存的索引位仅来自虚拟地址的页内偏移部分(而非 VPN),这是为了避免索引位受虚拟地址转换影响(PO 在虚实地址中是一致的)。
- 缓存行偏移(Line Offset)用于定位缓存行内的具体字节
假设 L1 Cache 有 64KB,缓存行 64B:
索引位数 = log₂(64KB / 64B) = log₂(1024) = 10 位
所以缓存索引使用虚拟地址的 10 位
页内偏移 = 12 位(4KB 页)
页内偏移在虚拟地址和物理地址中是完全相同的(分页机制只转换 VPN,不改变 PO)。
若索引位完全落在页内偏移中(即索引位长度 ≤ 页内偏移位长度),则 Cache 索引使用的是 “虚实一致” 的地址位,可避免因 VPN 不同但物理页相同导致的缓存别名问题(Alias Problem)。
所以要求:索引位 ≤ 页内偏移位
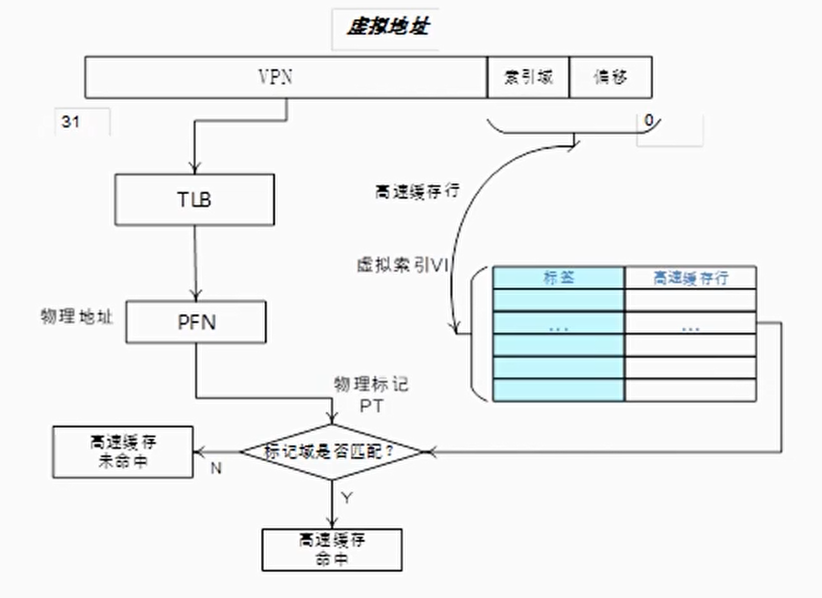
左右两步同时进行
VIPT别名问题
两个虚拟页面同时映射到同一个物理页面时,两个虚拟页面同时一起填满了Cache的一路
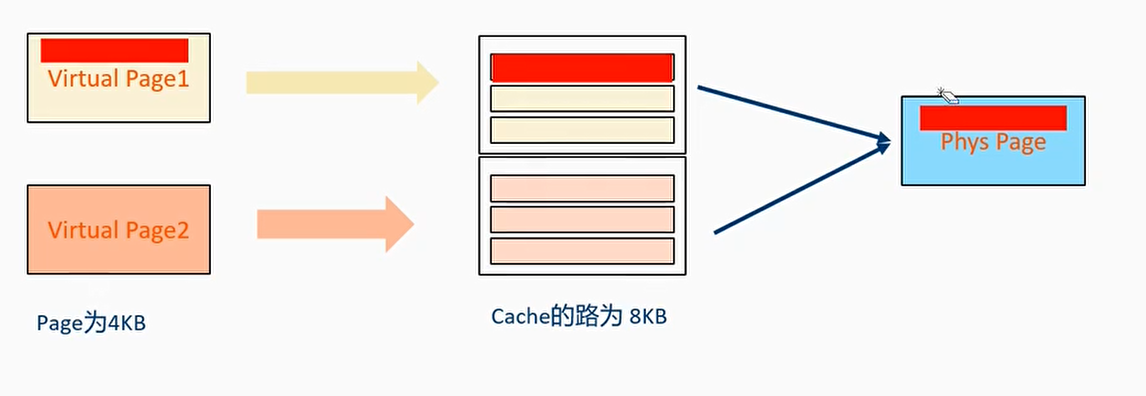
如图,Virtual Page1改写后,Virtual Page2访问的仍然是原来的数据
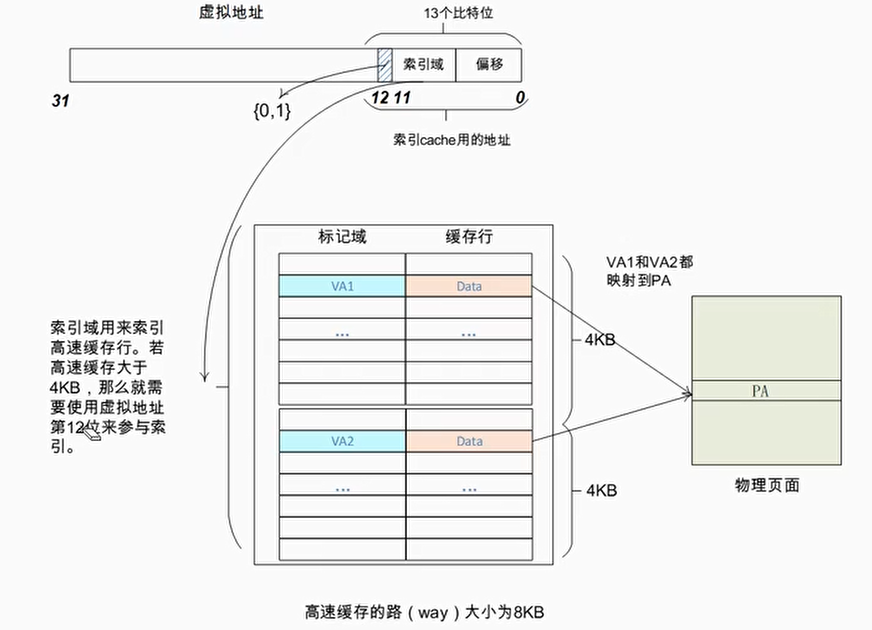
这个别名问题可以通过cache layout 来避免,即让VIPT 缓存的索引位仅来自虚拟地址的页内偏移部分(而非 VPN)
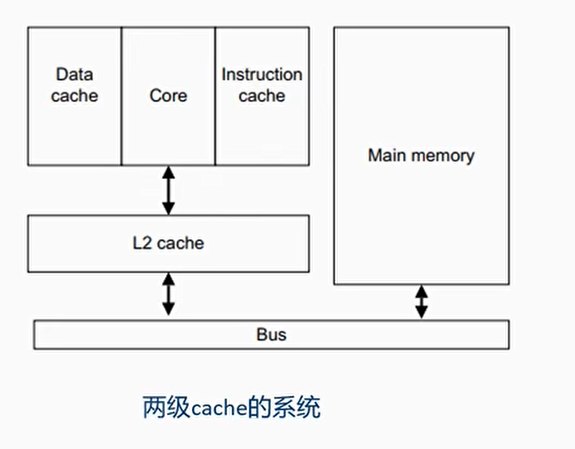
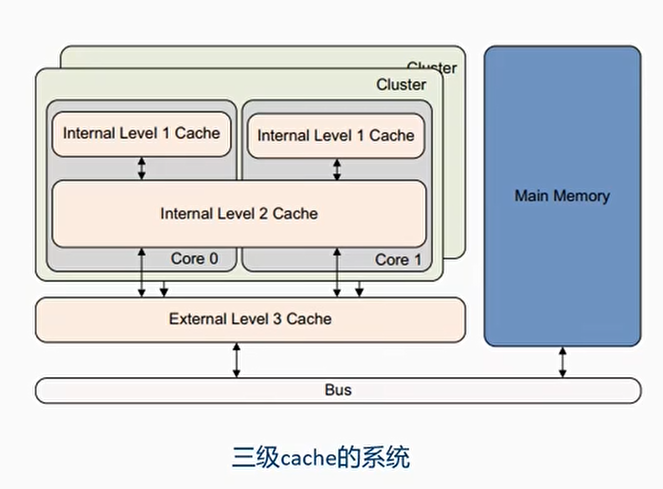
Cache层级
两级cache的系统
三级cache的系统
多级cache的处理流程
举例:
1 | LDR x0,[x1] |
加载x1地址的值到x0,假设x1是cachable的
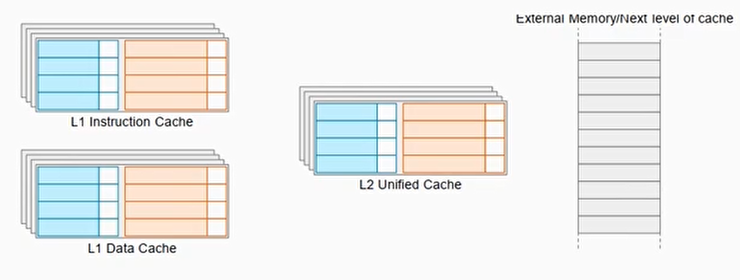
- Case1: 如果x1的值在L1 cache中,那么CPU直接从L1 cache获取了数据
- Case2: 如果x1的值不在L1 cache中,而是在L2 cache中
- 如果L1 cache中没有空间,那么会淘汰一些cache line
- 数据从L2 cache line加载到L1 cache line
- CPU从L1 cache line中读取数据
- Case3: x1的值都不在L1和L2 cache中,但是在内存中
- 如果L1 cache和L2 cache中没有空间,那么会淘汰一些cache line
- 数据从内存中加载到L2和L1的cache line中
- CPU从L1 cache line中读取数据
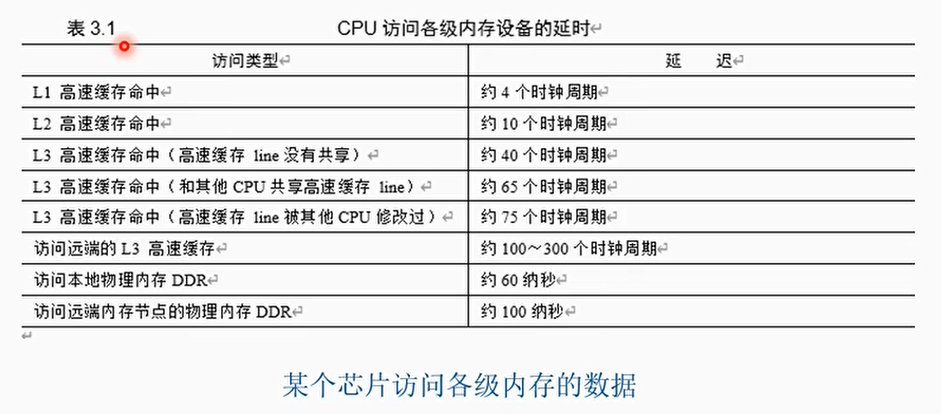
多级cache的访问延迟
Cache的策略(Cache Policies)
Cache相关的策略是在MMU页表中配置。只有Normal内存可以被cacheable
Cache策略包括:
- Cacheable/non-cacheable
- Cacheable细分
- Read/write-allocate
- Write-Back cacheable, write-through cacheable
- Shareability
Cache 的分配策略
- Write allocation(WA): 当write miss的时候才分配一个新的cache line
- Read allocation(RA): 当read miss的时候才分配一个新的cache line
Cache回写策略:
- Write-back(WB): 回写操作仅仅更新到cache,并没有马上更新回内存(cache line is marked as dirty)
- Write through(WT): 回写操作会直接更新cache和内存
Write Back和Write Through
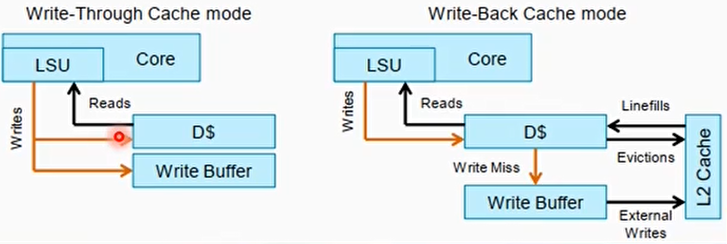
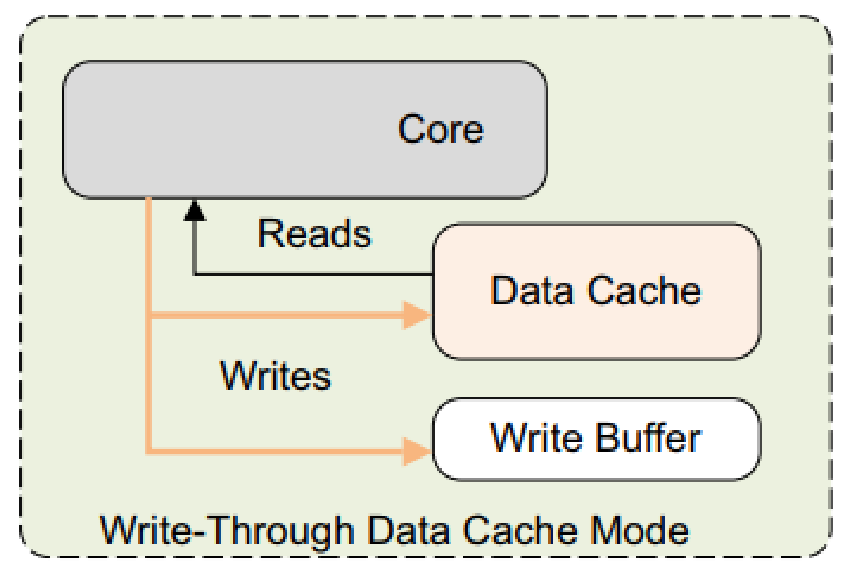
- WT写直通模式
- 进行写操作时,数据同时写入当前的高速缓存,下一级高速缓存或主存储器中
- 直写模式可以降低高速缓存一致性的实现难度,最大的缺点是消耗比较多的总线带宽
- ARM Cortex-A系列处理器把WT模式看成Non-cacheable
- The Cortex-A72 processor memory system treats all Write-Through pages as Non-cacheable
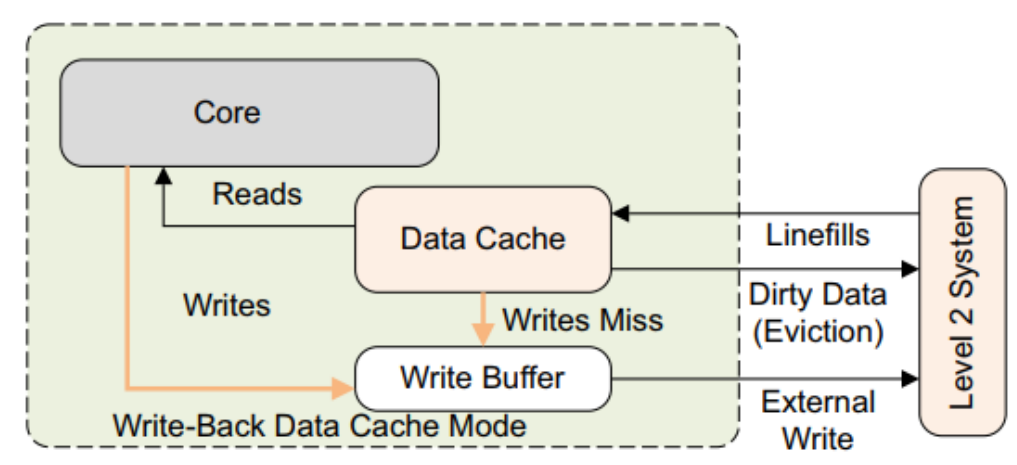
WB模式回写模式
- 写入仅更新缓存并将缓存行标记为脏。仅当cache line被flush或明确清除时,才会更新外部存储器。
- Cache line变成Dirty data

Inner 和 Outer Shareability
- Normal memory可以设置inner或者outer shareability
- 怎么区分是inner或者outer,不同设计有不同的区分
- inner attribute通常是CPU IP集成的caches
- outer attribute are exported on the bus
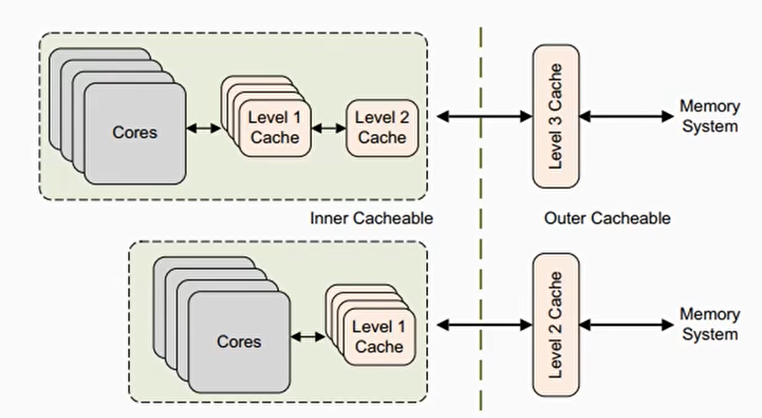


- inner attribute是内部集成的cache
- outer attribute是挂载在外部总线的外部cache
预取指令
AArch64(ARMv8 64-bit)中的预取指令
在 A64 中,使用的是 PRFM(Prefetch Memory)。
指令格式
1 | PRFM <prfop>, [Xn, #imm] // 从 Xn + offset 的地址预取缓存 |
prfop 语法结构说明
1 | <prfop> = <type><target><policy> | #uimm5 |
| 字段 | 含义 | 示例值 |
|---|---|---|
<type> |
预取目的 | PLD 读,PST 写 |
<target> |
预取目标缓存层级 | L1, L2, L3 |
<policy> |
缓存使用策略 | KEEP(重复使用),STRM(流式访问/一次性用) |
#uimm5 |
5 位编码形式 | #0 ~ #31 |
示例
预取读取数据到 L1,保留在缓存
1 | PRFM PLDL1KEEP, [X0, #32] |
意思是:把地址 (X0 + 32) 对应的数据提前加载到 L1 Cache,并且标记为可能反复使用。
预取一次性读取(流式访问)
1 | PRFM PLDL1STRM, [X1] |
意思是:把 [X1] 预加载进缓存,但不长期保留(适合 memcpy 这种顺序流式读取)。
等价立即数写法
1 | PRFM #0, |
#0 在 ARM 预取 hint 表是默认的 PLDL1KEEP。
| uimm5值 | 对应 prfop | 含义 |
|---|---|---|
#0 |
PLDL1KEEP |
读预取到 L1,重用(最常用) |
#1 |
PLDL1STRM |
读预取到 L1,流式(只用一次) |
#4 |
PLDL2KEEP |
读预取到 L2 |
#8 |
PLDL3KEEP |
读预取到 L3 |
#16 |
PSTL1KEEP |
写预取 |
#17 |
PSTL1STRM |
写预取(流式) |
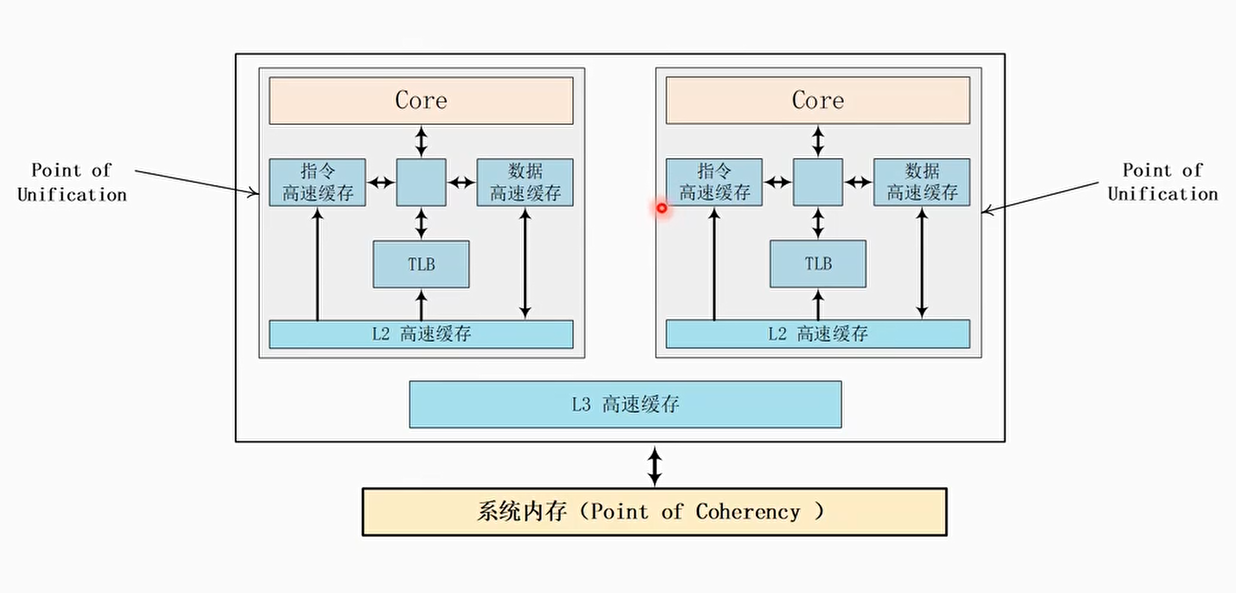
Point of Unification(PoU)和Point of Coherency(PoC)
- PoU: 表示一个CPU中的指令cache,数据cache还有MMU,TLB等看到的是同一份的内存拷贝
- PoU for a PE,是说保证PE看到的I/D cache和MMU是同一份拷贝。大多情况下,PoU是站在单核系统的角度来观察的
- PoU for inner share,意思是说在inner share里面的所有PE都能看到相同的一份拷贝
- PoC: 系统中所有的观察者例如DSP, GPU, CPU, DMA等都能看到同一份内存拷贝

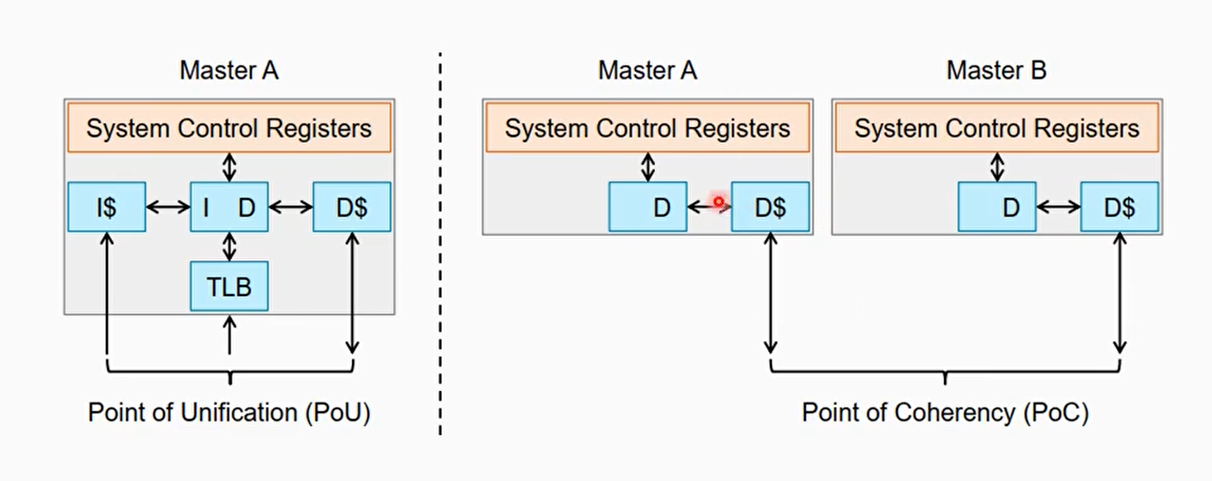
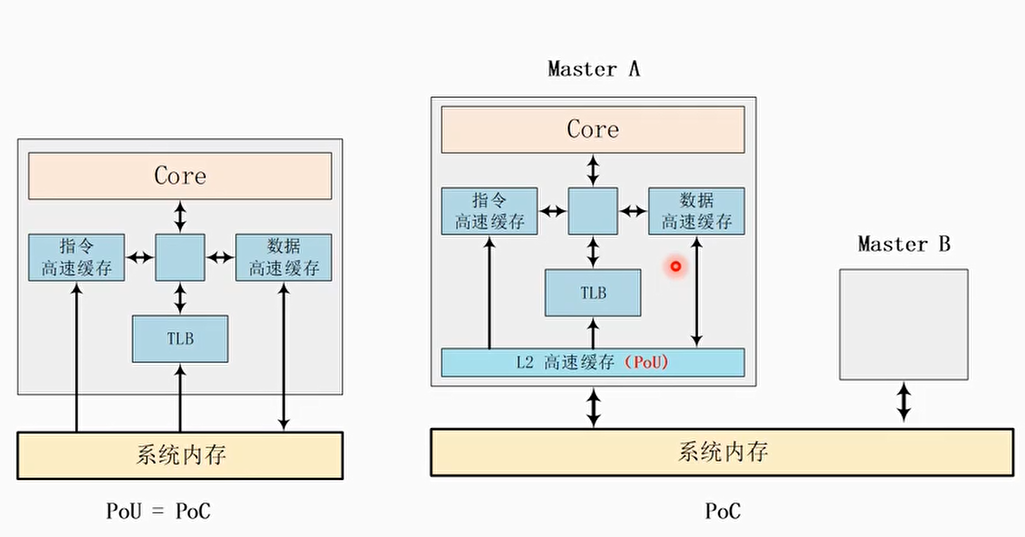
PoU和PoC的区别
- PoC是系统一个概念,和系统配置相关
- 例如,Cortex-A53可以配置L2 cache和没有L2 cache,可能会影响PoU的范围
Cache维护
- Cache的管理操作
- 无效 (Invalidate) 整个高速缓存或者某个高速缓存行。高速缓存上的数据会被丢弃。
- 清除 (Clean) 整个高速缓存或者某个告诉缓存行。相应的告诉缓存行会被标记为脏,数据会写回到下一级高速缓存中或者主存储器中(也可称为flush)
- 清零 (Zero) 操作
- Cache管理的对象
- ALL : 整块高速缓存
- VA: 某个虚拟地址,有时称MVA(修改后的虚拟地址,是包含特定虚拟地址的高速缓存行)
- Set/Way: 特定的告诉缓存行或者组和路
- Cache管理的范围
- PoC
- PoU
- Shareability
- inner
Cache指令格式
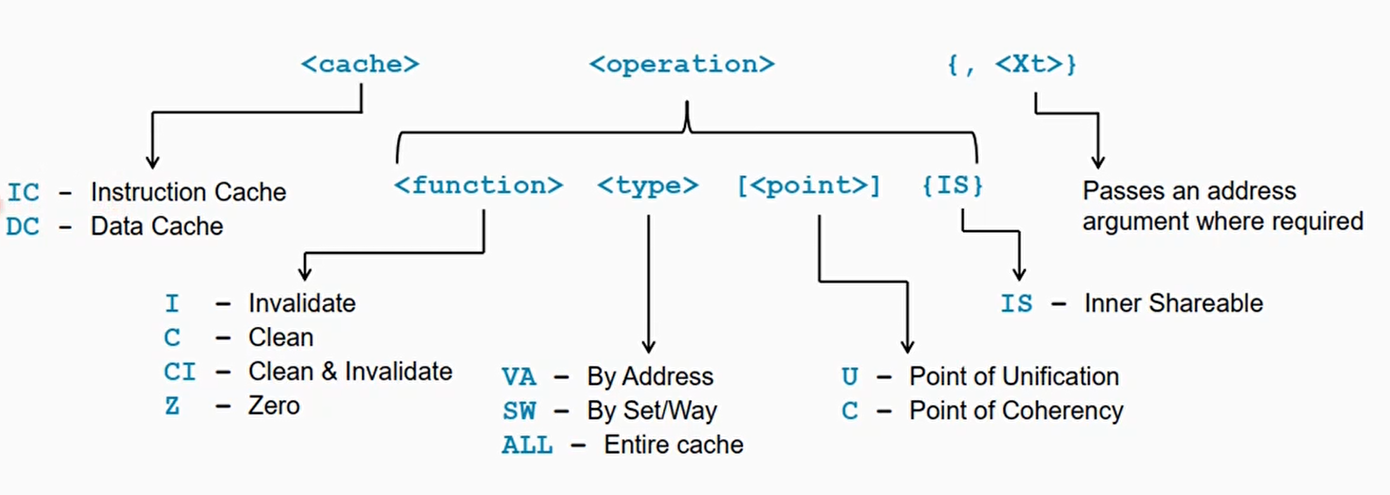
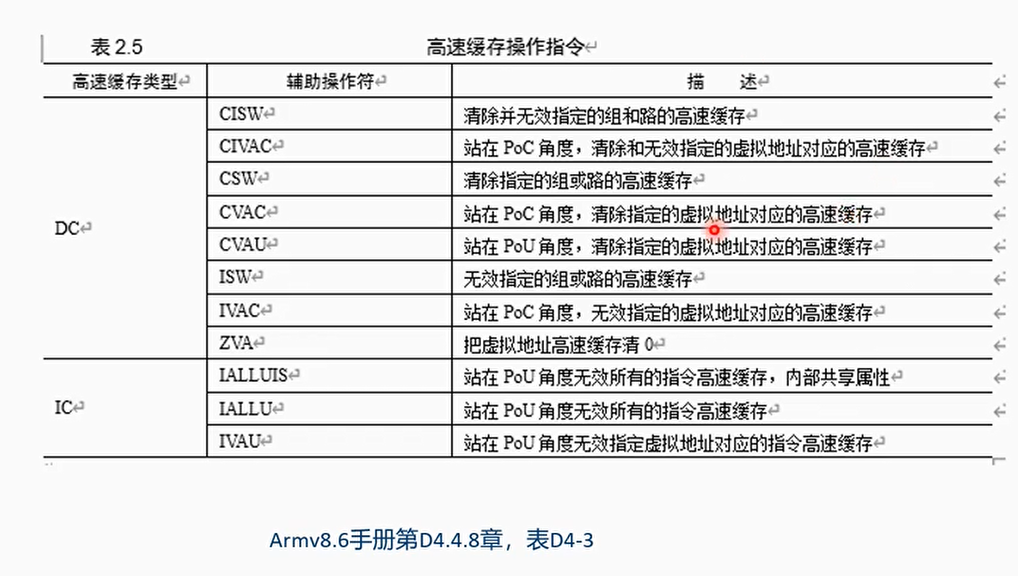
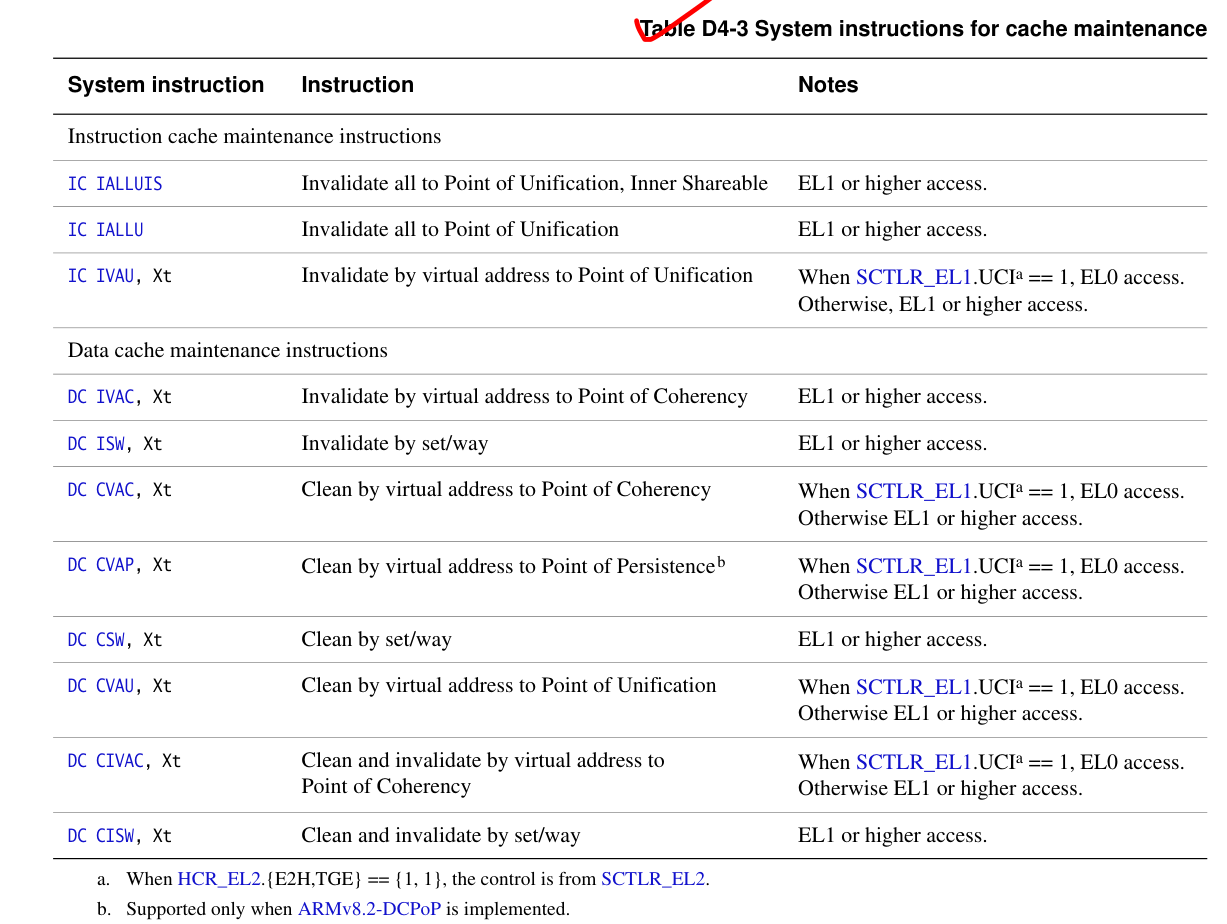
接受地址参数的指令采用一个 64 位寄存器,该寄存器保存要维护的虚拟地址。此地址没有对齐限制。
AArch64 数据缓存按地址无效指令 DC IVAC 需要写权限,否则会生成权限错误。
例子1
遍历所有 CPU 数据缓存(Data Cache)层级(L1/L2/L3…),并对每一级缓存执行逐路逐组的清理(Clean by Set/Way),确保缓存中的数据都回写到内存:
1 | // AArch64: Data Cache Clean by Set/Way |
CLIDR_EL1
| 位段 | 含义 |
|---|---|
| bits [26:24] | LoC = Level of Coherency(缓存一致性层级 × 2) |
| bits [2:0] | L1 cache type |
| bits [5:3] | L2 cache type |
| … | … |
代码整体流程:
| 步骤 | 动作 | 解释 |
|---|---|---|
| 1 | 读 CLIDR_EL1 | 获取系统中有几级 Cache 以及类型 |
| 2 | 解析 LoC | 确定需要遍历多少级缓存 |
| 3 | 逐层循环 | 从 L1 → L2 → L3… 依次处理每一级缓存 |
| 4 | 用 CSSELR_EL1 选择缓存层 | 告诉 CPU:接下来我要访问哪一级的 Cache |
| 5 | 读 CCSIDR_EL1 | 查询该 Cache 的详细配置(组数、路数、行大小) |
| 6 | 双重循环 | 遍历 Set(组)和 Way(路),逐行清理缓存 |
| 7 | DC CSW |
执行 Clean by Set/Way |
| 8 | DSB + ISB |
数据同步屏障,确保清理完成后再继续执行 |
在正常情况下,清理或使整个缓存无效是只有固件应该做的事情,作为内核加电或断电序列的一部分。它也可能需要大量时间,L2 缓存中的行数可能非常大,并且有必要逐个循环它们。因此,这种清理绝对只适用于特殊场合!
例子2
1 | /* Coherency example for data and instruction accesses within the same Inner |
这段代码是标准的 Self-modifying code / JIT 编译同步步骤:
- 写入新指令到内存(可能在 D-Cache)
- 清 D-Cache,把数据写回 PoU
- DSB:保证写回完成
- I-Cache 作废对应地址
- DSB:保证作废完成
- ISB:刷新取指流水线,CPU 执行新指令
Cache discovery
- 在我们做cache指令管理的时候,你需要知道如下信息:
- 系统支持多少级的cache?
- Cache line是多少
- 每一级的cache,它的set和way是多少
- 对于zero操作,我们需要知道多少data可以被zeroed?
- Cache Level ID Register (CLIDR, CLIDR_EL1):列出有多少level的cache,可以读取缓存级别的数量
- Cache Type Register(CTR, CRT_EL0): cache line大小,可以读取缓存行的大小
- 如果这需要由运行在执行级别EL0的用户代码访问, 这可以通过设置系统控制寄存器(SCTLR/SCTLR_EL1) 的 UCT 位来完成。
- sets and ways: 需要访问两个寄存器来获取
- 告诉Cache Size Selection Register(CSSELR, CSSELR_EL1)要查询哪个cache
- 从Cache Size ID Register(CCSIDR, CCSIDR_EL1)中读取相关信息
Cache Discovery其他说明
数据缓存零 ID 寄存器 (DCZID_EL0) 包含要为零操作归零的块大小。
DC ZVA (Data Cache Zero by Virtual Address)
- 将一条 cache line 对应的内存清零
- DCZID_EL0 保存可以归零的块大小
- 访问权限:只有特权级别(EL1 及以上)能访问 DCZID_EL0
控制位:
- SCTLR_EL1.DZE:控制 EL0 是否允许 DC ZVA
- HCR_EL2.TDZ:控制 EL0/EL1 在非安全世界是否允许 DC ZVA
SCTLR/SCTLR_EL1 的 [DZE] 位和 Hypervisor 配置寄存器 (HCR/HCR_EL2) 中的 [TDZ] 位控制哪些执行级别和哪些世界可以访问 DCZID_EL0。CLIDR_EL1、CSSELR_EL1 和 CCSIDR_EL1 只能通过特权代码访问,即 AArch32 中的 PL1 或更高版本,或 AArch64 中的 EL1 或更高版本。
如果在异常级别禁止通过虚拟地址执行数据高速缓存零 (DC ZVA) 指令,EL0 由 SCTLR_EL1.DZE位控制,EL1 和 EL0 中的非安全执行由 HCR_EL2 控制.TDZ 位,然后读取该寄存器返回一个值,指示该指令不受支持。
CLIDR 寄存器只知道处理器本身集成了多少级缓存。它不能提供有关外部存储系统中任何缓存的信息。例如,如果只集成了 L1 和 L2,CLIDR/CLIDR_EL1 标识了两个级别的缓存,处理器不知道任何外部 L3 缓存。在执行缓存维护或与集成缓存保持一致性的代码时,可能需要考虑非集成缓存。
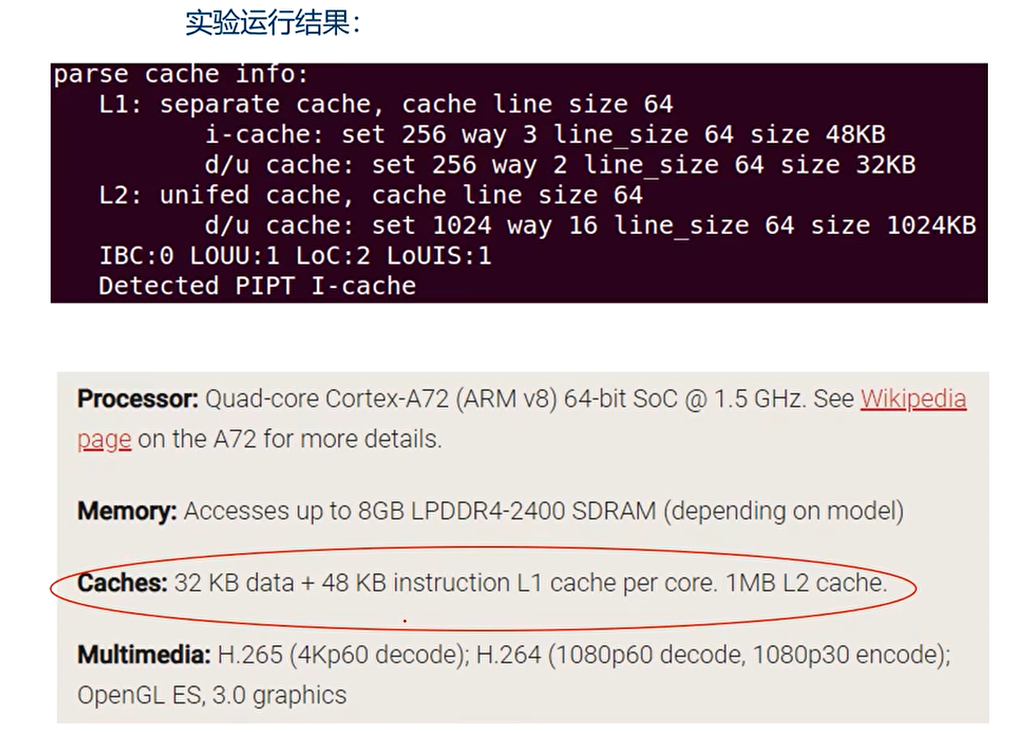
Cache实验一:cache的枚举 Cache Discovery

实验运行结果:
代码
核心思路:
- 先识别每一级 cache 类型(CLIDR)
- 选择层级和类型,读取配置寄存器(CSSELR/CCSIDR)
- 计算每一级 cache 的 set/way/line size 和总大小
- 打印边界信息和 L1 I-Cache 寻址策略**
1 |
|
相关寄存器
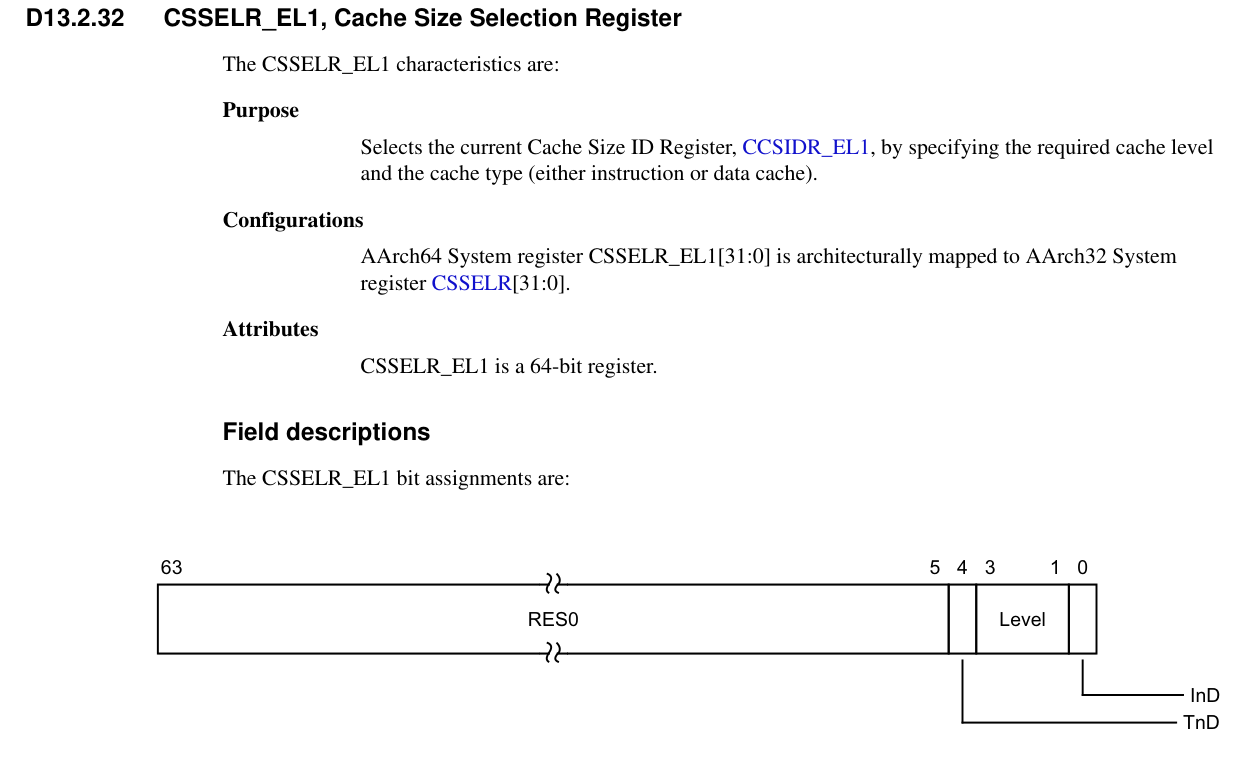
CSSELR_EL1
Cache Size Selection Register
| Bits | 名称 | 含义 |
|---|---|---|
| 63:5 | RES0 | 保留位,读写无意义 |
| 4 | TnD | Allocation Tag not Data:是否选择单独的 Allocation Tag cache 0b0 → 数据、指令或统一缓存 0b1 → 单独 Allocation Tag cache 注意:当 InD = 1(指令缓存)时,这个位为 RES0(无效) |
| 3:1 | Level | 要查询的缓存级别(Cache Level) 0b000 → L1 0b001 → L2 0b010 → L3 0b011 → L4 0b100 → L5 0b101 → L6 0b110 → L7 其他值保留注意:如果选择了未实现的缓存级别,读取 CSSELR_EL1 返回值是不确定的 |
| 0 | InD | Instruction not Data:缓存类型: 0b0 → 数据或统一缓存 ( Data Cache or Unified Cache ) 0b1 → 指令缓存 ( Instruction Cache ) 如果选择未实现的缓存级别,读取 CSSELR_EL1 的 Level 和 InD 返回值是不确定的 |



CCSIDR_EL1
Current Cache Size ID Register


| Bits | 名称 | 含义 |
|---|---|---|
| 63:56 | RES0 | 保留位 |
| 55:32 | NumSets | Cache 中的 set 数减 1 → 实际 set 数 = NumSets + 1注意:set 数不一定是 2 的幂 |
| 31:24 | RES0 | 保留位 |
| 23:3 | Associativity | 描述 cache 的 way 数,Cache 的关联度(ways)减 1 → 实际 associativity = Associativity + 1注意:不一定是 2 的幂 |
| 2:0 | LineSize | Cache line 大小的 log2 减 4计算公式:line_size_bytes = 1 << (LineSize + 4) |

如果ARMv8.5-MemTag is implemented and enabed
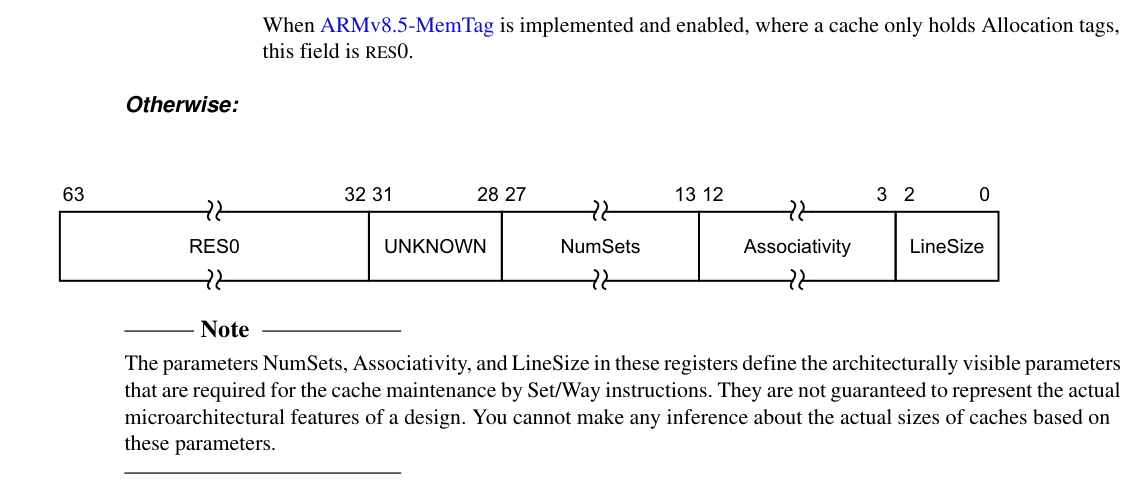
CCSIDR2_EL1
Current Cache Size ID Register 2
ARMv8.3-CCIDX is implemented才有效

| Bits | 名称 | 含义 |
|---|---|---|
| 63:24 | RES0 | 保留位,读写无意义 |
| 23:0 | NumSets | Cache 中的 set 数目减 1计算方法:NumSets + 1 得到实际的 set 数注意:set 数不一定是 2 的幂 |
- 用途:查询指定 cache 的 set 数量。
- 该寄存器一般与 CSSELR_EL1 配合使用:
- 写 CSSELR_EL1 选择 Cache Level 和类型(数据/指令/Tag)
- 读 CCSIDR2_EL1 得到该 cache 的 set 数
- NumSets = 0 表示 1 个 set
- NumSets > 0 表示 实际 set 数 = NumSets + 1

读取CCSIDR2_EL1注意事项:

CLIDR_EL1
Cache Level ID Register
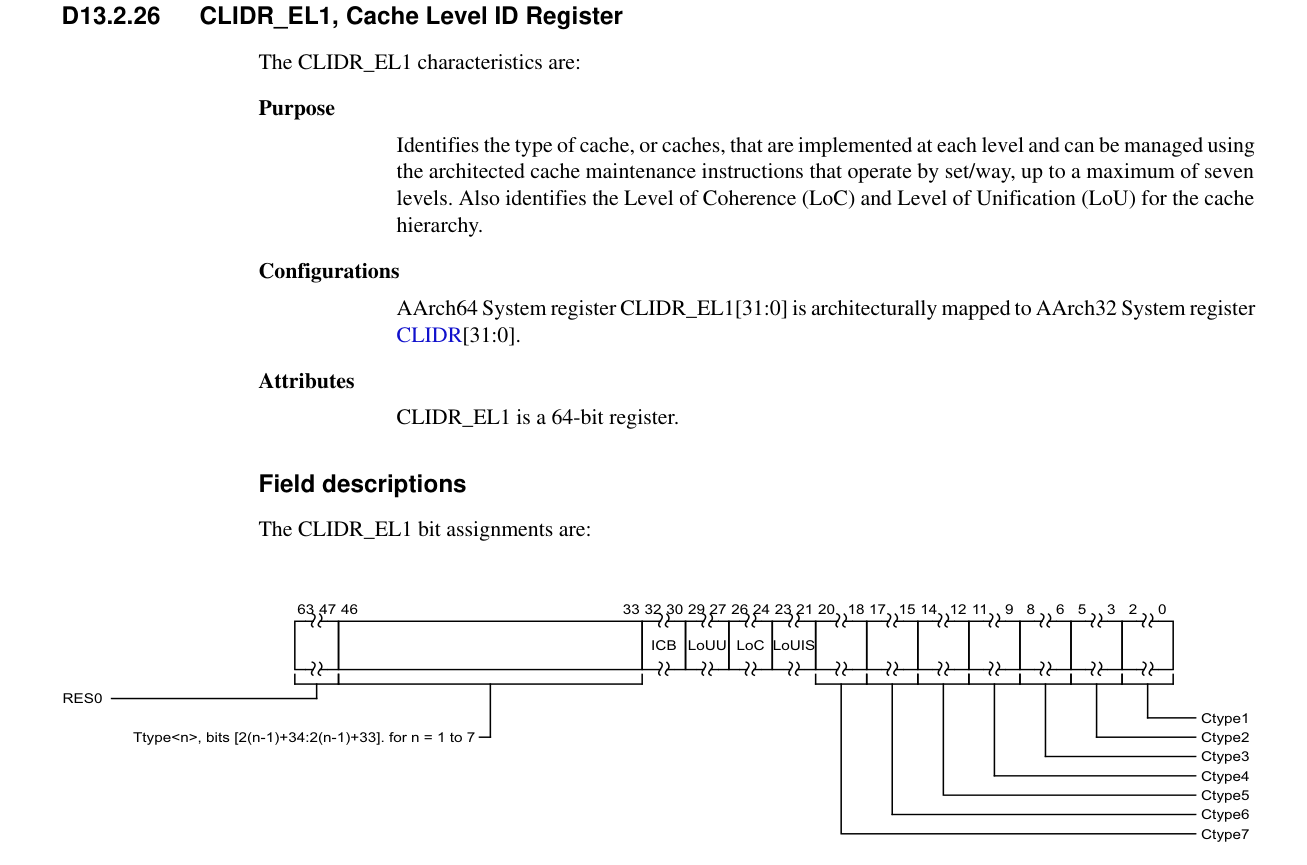
- 用途:
- 标识处理器每一级 cache 的类型(Instruction/Data/Unified/Tag)。
- 指出可以使用 Set/Way cache maintenance instructions 管理的 cache。
- 提供 缓存层次的一致性与共享级别信息(LoC、LoU、LoUIS)。
- 支持最多 7 级缓存。
| Bits | 名称 | 含义 |
|---|---|---|
| 63:47 | RES0 | 保留位 |
| 46:35 | Ttype(n=1..7) | Tag Cache 类型 0b00: 无 Tag Cache 0b01: Separate Allocation Tag Cache 0b10: Unified Allocation Tag + Data (同一行) 0b11: Unified Allocation Tag + Data (分行) |
| 34:32 | ICB | Inner Cache Boundary(内部缓存边界) 0b000: Not disclosed by this mechanism. 0b001: L1 is the highest Inner Cacheable level 0b010: L2 is the highest Inner Cacheable level ……. 0b110: L6 is the highest Inner Cacheable level 0b111: L7 is the highest Inner Cacheable level |
| 31:29 | LoUU | Level of Unification Uniprocessor |
| 28:26 | LoC | Level of Coherence |
| 25:23 | LoUIS | Level of Unification Inner Shareable |
| 22:0 | Ctype(n=1..7) | Cache Type(每一级缓存类型) 0b000: No cache 0b001: Instruction cache only 0b010: Data cache only 0b011: Seprate instruction and data cache 0b100: Unified cache |
CTR_EL0
Cache Type Regiser
作用是提供cache的架构信息

| 位域 | Bits | 名称 | 描述 |
|---|---|---|---|
| 63-38 | RES0 | Reserved | 保留,读出为 0 |
| 37-32 | TimeLine | Tag minimum Line | Tag 最小 line 粒度,表示 Allocation Tag 覆盖的最小 cache line 的大小(log2(以 word=4B 为单位))与**Memory Tagging Extension (MTE)**有关 |
| 31 | RES1 | Reserved | 保留,固定为 1 |
| 30 | RES0 | Reserved | 保留,固定为 0 |
| 29 | DIC | Instruction cache invalidation requirements for data to instruction coherence | 决定是否需要做 I-cache invalidate 来保证数据写入对 I-cache 可见 0 = 数据写入后,必须 invalidate I-cache 才能让指令取到最新数据。 1 = 不需要 invalidate I-cache。 |
| 28 | IDC | Data cache clean requirements for instruction to data coherence | 决定是否需要清理(clean)D-cache 来保证 I/D 一致性 0 = 数据 cache 需要 clean 到 PoU 才能保证 I/D 一致性。 1 = 不需要 D-cache clean。 通常现代核都置 1,表示硬件自动保证一致性 |
| 27-24 | CWG | Cache Writeback Granule | Cache Writeback Granule,缓存写回的最大粒度(log2(以 word=4B 为单位))。表示当一个 cache line 写回时,可能影响的最大内存块大小(以 word=4B 为单位)。 例如 CWG=0b0100 → 2^(4) = 16 words = 64 bytes。 |
| 23-20 | ERG | Exclusives reservation granule | Exclusive Reservation Granule,原子指令(LDXR/STXR)的最大 reservation 范围粒度(log2(以 word=4B 为单位)) |
| 19-16 | DminLine | D minline | Data cache 最小 line 大小(log2(以 word=4B 为单位)) |
| 15-14 | L1IP | Level 1 Instruction cache policy | L1 指令缓存寻址策略: 0 = VPIPT 1 = Reserved 2 = VIPT 3 = PIPT |
| 13-12 | RES1 | Reserved | 保留 |
| 3-0 | IMINLINE / DMINLINE | Instruction minline / Data minline | Instruction cache 最小 line 大小(log2(以 word=4B 为单位)) |
L1Ip
表示L1 Instrucion Cache的类型:

Instruction cache invalidation requirements for data to instruction coherence

Data cache clean requirements from instruction to data coherence

Cache Writeback Granule

通常情况下,CWG = 最大 cache line 大小,因为写回是以整行(cache line)为单位的。
但是,ARM 规范允许微架构不同:
- CWG ≥ cache line size:有些实现可能在写回时会把多个 cache line 合并成更大的突发写(burst),比如 128B。
- CWG = cache line size:常见情况,比如 line=64B → CWG=0b0100(16 words)。
- CWG 未提供 (
0b0000):必须假设最大写回粒度是 2KB,或者自己去读 Cache Size ID Registers 推算。