GDB
时间轴
2025-06-24
init
2025-10-07
add gdb in emacs
2025-10-09
add complementary skills
2025-10-10
add multithread debugging
2025-10-13
add multiprocess debugging,remote debugging,coredump debugging,add memory problem check
gdb 配置
tui 模式下显示混乱
参考:

总之是创建 ~/.config/gdb/gdbinit 文件然后写入如下内容
1 | define c |
对于c++调试,推荐使用下面的扩展指令,可以更方便查看stl容器:
共有以下指令:
1 | std::vector<T> -- via pvector command |
gdb 看不到程序 printf 输出
这是因为输出存在缓冲区,使用以下命令
1 | call fflush(stdout) |
io 输入输出使用不同的终端
缺省情况,gdb 和程序的输入输出使用同一终端,可以为程序指定单独的输入输出终端,先打开一个终端输入 tty 命令获取当前终端名称然后启动:
1 | gdb -tty /dev/pts/3 ./a.out |
在 emacs 中使用 gdb
主要使用 gdb 的 MI 模式,参考
gdb tui 模式
TUI 模式下最多显示 3 个窗口,命令窗口始终存在
打开 tui 模式并打开源码
1 | (gdb) layout src |
源码窗口代码行数前的断点
- B 表示已经命中过了,至少命中过一次
- b 表示还没有命中的
- +表示断点时是可用的
- -表示断点是 disable 的
显示汇编窗口
1 | (gdb) layout asm |
显示寄存器窗口
1 | (gdb) layout reg |
切分窗口
1 | (gdb) layout split |
切换窗口焦点
1 | (gdb) focus src/asm/reg/cmd |
查看当前拥有焦点的窗口
1 | (gdb) info win |
退出窗口模式
Ctrl + x +a
启动 gdb
编译阶段:加入调试信息
为了让 GDB 能看到函数名、变量名、源码行号,编译时必须加上 -g 参数:
1 | gcc -g hello.c -o hello # 对 C 程序 |
否则 GDB 只能看到汇编和内存地址,无法进行源码级调试。
启动方式
调试一个程序
1 | gdb ./program |
设置程序运行参数
-
设置运行参数(如命令行参数):
1
set args 10 20 30
-
查看当前设置的参数:
1
show args
设置运行环境变量
-
设置程序运行路径(用于找可执行文件):
1
path /your/bin/dir
-
查看运行路径设置:
1
show paths
-
设置环境变量(例如传给
main()程序用的环境):1
set environment USER=yourname
-
查看环境变量:
1
2show environment
show environment USER
设置工作目录
设置工作目录指的是程序运行时的当前目录
-
切换当前目录(等同于 shell 的
cd):1
cd /path/to/dir
-
查看当前目录:
1
pwd
控制程序的输入输出
-
查看程序绑定的终端信息:
1
info terminal
-
重定向输出(如保存输出到文件):
1
run > output.txt
-
指定程序输入输出使用的终端设备:
1
tty /dev/pts/1
调试 core dump 文件
Linux core dump:
一般称之为核心转储、内核转储,我们统称为转储文件。是某个时刻某个进程的内存信息映射,即包含了生成转储文件时该进程的整个内存信息以及寄存器等信息。转储文件可以是某个进程的,也可以是整个系统的。可以是进程活着的时候生成的,也可以是进程或者系统崩溃的时候自动生成的。
为活着的进程创建 core dump 文件一般可以通过 gdb 来生成,使用 gdb 把进程 attach 进来以后,执行 generate-core-file 或者 gcore 命令来生成 core dump 文件。
我们更多时候是对崩溃产生的 core dump 文件进行分析。
为活着的进程产生 coredump 文件
通过 gcore 生成 core dump 文件,完全不影响程序的运行
1 | gdb attach pid |
core dump 是程序崩溃后的转储
1 | gdb ./program core |
打开 Linux core 文件生成功能
Linux 默认没有打开 core 文件生成功能,也就是发生段错误时不会core dumped。可以通过以下命令打开core文件的生成:
1 | # 不限制产生 core 的大小 |
unlimited 意思是系统不限制 core 文件的大小,只要有足够的磁盘空间,会转存程序所占用的全部内存,如果需要限制系统产生 core 的大小,可以使用以下命令:
1 | # core 最大限制大小为 409600 字节 |
可以配置生成的 coredump 文件的名字,可以不覆盖默认的 coredump 文件
1 | echo -e "%e-%p-%t" > /proc/sys/kernel/core_pattern |
关闭 Linux core 文件生成功能
把核心转储功能关闭,只需要将限制大小设为0 即可:
1 | ulimit -c 0 |
注意,如果只是输入命令“ulimit -c unlimited”,这只会在当前终端有效,退出终端或者打开一个新的终端时是无效的。
例子:
编写一个简单的 C 程序,人为制造一个Segmentation fault错误:
1 |
|
上述代码中定义了一个空指针变量 P,然后给空指针 P 赋值,运行程序就会产生一个段错误。
开启了核心转储后,就会产生一个 core 文件。
1 | # 编译 hello.c 生成 hello 程序 |
运行后,我们可以看到 Segmentation fault (core dumped) 提示信息,表示已经在当前目录下产生了一个core 文件:
调试正在运行的程序
1 | gdb ./program <PID> |
- 直接指定 PID 启动 GDB(需要有可执行程序路径):
1 | gdb ./program <PID> |
- 在 GDB 内 attach 到某个 PID:
1 | (gdb) attach <PID> |
常用启动参数
| 参数 | 含义 |
|---|---|
-s 或 -symbols <file> |
指定符号表文件 |
-se <file> |
指定符号表文件,并关联到可执行文件 |
-c 或 -core <file> |
指定 core dump 文件用于调试 |
-d 或 -directory <dir> |
添加源码搜索路径(默认用 $PATH) |
退出输入 quit(q)即可
gdb 中运行 Shell 命令
在 GDB 中可以直接运行操作系统的命令,方法是:
1 | (gdb) shell <命令字符串> |
example
1 | (gdb) shell ls -l |
这会在 GDB 内部启动你系统的 shell(由环境变量 SHELL 决定),然后执行你写的命令。
GDB 也内置了一个命令:
1 | (gdb) make <参数> |
它本质上等价于:
1 | (gdb) shell make <参数> |
也就是说,它会调用系统的 make 工具来重新编译程序,非常方便调试时快速修改代码后重新 build。
1 | (gdb) pip i locals | grep test |
gdb 调试输出日志保存
1 | # 打开日志输出,off为关闭 |
调试程序
源代码
显示源代码
- 显示源代码 list or **l,**默认显示 10 行
- 设置每次显示的行数:set listsize xx
- 查看指定的函数代码:list test_fun
- 查看指定文件指定行代码: list main.cpp:15
搜索源代码
- search 正则表达式
- forward-search 正则表达式
- reverse-search 正则表达式
(输入 search 命令后按回车会继续找下一个匹配的,通过 list 命令指定起始搜索位置)
设置源代码搜索目录
- directory path
断点 (breakpoint)
设置断点
按函数名设置断点
1 | break function |
- 在指定函数的入口处停下。
- 对于 C++ 可以写成:
break ClassName::Functionbreak function(type1, type2)(如果重载)
按行号设置断点
1 | break 42 |
- 在当前源文件的第 42 行 设断点。
相对当前行设置断点
1 | break +5 // 当前行之后5行 |
指定文件 + 行号
1 | break filename.c:42 |
- 在
filename.c的第 42 行设置断点。
指定文件 + 函数名
1 | break filename.c:func |
- 在
filename.c中func函数的入口处设置断点。
按地址设置断点
常用于汇编调试
1 | break *0x4007d0 |
- 在程序内存地址
0x4007d0处设置断点。
设置条件断点
1 | break func if i == 100 |
- 当变量
i == 100且执行到func函数时才停下。
设置下一条语句的断点(无参数)
1 | break |
- 在“下一条将要执行”的语句处设断点。
查看断点
查看所有断点
1 | info breakpoints |
查看指定编号的断点
1 | info break 3 |
删除断点
删除某一个断点
1 | delete <编号> |
- 例如:
delete 1表示删除编号为 1 的断点。
删除多个断点
1 | delete 1 2 3 |
- 同时删除断点 1、2 和 3。
删除所有断点
1 | delete |
- 不加参数表示删除所有断点。GDB 会提示你确认(输入
y)。
为断点添加命令
1 | commands <bnum> |
示例:
1 | break foo if x > 0 |
作用:x > 0 时断点命中,打印后自动继续,不用手动按
c。
1 | b 31 |
为断点设置命令后当程序停到该断点时自动打印出这两个值;
commands 命令后面可以直接跟断点的序号
1 | i b |
清除已有命令
1 | commands <bnum> |
忽略断点次数(ignore)
1 | ignore <bnum> <count> # 忽略断点号 bnum 的触发 count 次 |
例如:
1 | ignore 2 3 |
忽略断点 2 的前三次命中,第 4 次才真正中断。
example
-
调试循环或大函数中的问题时,建议使用:
break <line> if i == 9999
或
ignore <bnum> 9998 -
在你定位 bug 后,不要删断点,直接:
1
disable <bnum> # 保留断点以后复用
-
想测试多个变量变化时:
1
2watch a
watch b -
想搞自动化调试:
1
2
3
4silent
printf "Reached here\n"
continue
end
保存断点到文件并读取
1 | (gdb) save breakpoints d.txt |
关闭后重新打开,应用已经保存的断点信息
1 | (gdb) source d.txt |
观察点 (watchpoint)
观察点是一个特殊的断点,当表达式的值发生变化时,它将中断下来。表达式可以是一个变量的值,也可以包含由运算符组合的一个或多个变量的值,例如’a+b’。有时被称为数据断点
设置观察点
watch <expr>
-
用途:当表达式或变量
expr的 值被改变 时,程序会暂停。 -
示例:
1
2watch x
watch gdata+gdata2>10当变量
x的值发生变化时暂停。任何一个线程满足 gdata+gdata2>10 程序都会停下来
rwatch <expr>
-
用途:当表达式或变量
expr被读取时,程序暂停。 -
示例:
1
rwatch y
当变量
y被读取时暂停程序。
awatch <expr>
-
用途:当表达式或变量
expr被读取或写入时,程序暂停。 -
示例:
1
awatch z
当变量
z被读取或写入时都暂停。
查看当前观察点
1 | info watchpoints |
- 显示所有设置的观察点(类似
info breakpoints)。
删除观察点
1 | delete <编号> |
- 与删除断点的方式一样。
注意事项
- 观察点依赖于 目标架构是否支持硬件观察点(大多数支持)。
- 不支持的情况下,GDB 可能无法设置
watch、rwatch等。 - 观察点数量受限,一般比断点少(通常是 4 个)。
捕获点 (catchpoint)
捕获点是一个特殊的断点,命令语法为:catch event,即捕获到 event 这个事件的时候,程序就会中断下来
命令格式
1 | catch <event> |
也可以使用一次性的捕获点:
1 | tcatch <event> |
常见 catchpoint 类型
| 事件类型 | 描述说明 |
|---|---|
throw |
捕获 C++ 程序抛出异常的位置。 |
catch |
捕获 C++ 程序捕获异常的位置。 |
exec |
捕获程序调用 exec() 系统调用(替换进程映像)。 |
fork |
捕获程序调用 fork() 系统调用(创建子进程)。 |
vfork |
捕获 vfork() 调用(特殊类型的 fork())。 |
load |
捕获动态链接库的加载事件。 |
unload |
捕获动态链接库的卸载事件。 |
示例
1 | catch throw |
在 C++ 抛出异常时中断程序。
1 | catch fork |
在程序调用
fork()时中断。
1 | tcatch exec |
设置一次性的捕获点,在程序调用
exec()系统调用时暂停,之后自动移除。
| 命令 | 描述 |
|---|---|
| catch assert | Catch failed Ada assertions, when raised. |
| catch catch | Catch an exception, when caught. |
| catch exception | Catch Ada exceptions, when raised. |
| catch exec | Catch calls to exec. |
| catch fork | Catch calls to fork. |
| catch handlers | Catch Ada exceptions, when handled. |
| catch load | Catch loads of shared libraries. |
| catch rethrow | Catch an exception, when rethrown. |
| catch signal | Catch signals by their names and/or numbers. |
| catch syscall | Catch system calls by their names, groups and/or numbers. |
| catch throw | Catch an exception, when thrown. |
| catch unload | Catch unloads of shared libraries. |
| catch vfork | Catch calls to vfork. |
程序停止点清除
清除停止点(clear)
1 | clear # 清除当前位置所有停止点 |
说明:
clear是基于“位置”清除,而非编号。
删除断点(delete)
1 | delete # 删除所有断点 |
禁用/启用断点(disable / enable)
1 | disable # 禁用所有断点 |
推荐使用
disable/enable管理调试状态,灵活又不丢失断点信息。
设置 / 修改停止点的条件(condition)
设置条件停止点(设置时)
1 | break foo if x > 5 |
修改断点条件(维护时)
1 | condition <bnum> x > 100 # 修改断点编号为 bnum 的条件 |
调试程序执行
恢复程序运行(继续执行)
| 命令 | 说明 |
|---|---|
continue / c / fg |
从当前断点处继续运行 |
continue <ignore-count> |
忽略接下来的 <count> 次断点命中 |
run / r |
重新启动程序(从头开始) |
适用于程序刚停下,想跳过一些断点或继续往下执行。
单步调试(源代码级)
| 命令 | 说明 |
|---|---|
step / s |
单步执行,会进入函数(Step Into) |
next / n |
单步执行,不进入函数(Step Over) |
step <count> / next <count> |
连续执行 <count> 步 |
用于逐行查看程序逻辑,
step会进函数内部,next则略过。
退出当前函数(函数级跳出)
| 命令 | 说明 |
|---|---|
finish |
继续运行到当前函数返回,并打印返回值和返回地址 |
非常实用,适合跟踪完某个函数后退出它。
跳出循环体 / 块(until)
| 命令 | 说明 |
|---|---|
until <location> / u |
执行直到某个位置或当前块结束(适合退出循环) |
示例:
1 | until 42 # 运行到当前文件的第 42 行 |
用于快速跳出 for/while 循环等结构块。
汇编级单步(指令级调试)
| 命令 | 说明 |
|---|---|
stepi / si |
单步执行一条机器指令(Step Into) |
nexti / ni |
单步执行一条机器指令(Step Over) |
用于底层跟踪,比如跟踪系统调用、libc 内部逻辑或 boot code。
汇编查看建议:
1 | display/i $pc # 实时显示当前执行指令 |
设置 step-mode 模式
主要用于控制是否进入无符号函数
| 命令 | 说明 |
|---|---|
set step-mode on |
即使没有 debug 符号也停住(默认 off) |
set step-mode off |
遇到无符号函数就跳过(默认) |
对调试汇编或只含部分符号的库文件时很有用。
skip 跳过某个函数的单步执行
- skip function
1 | test_str(test.get_str()); |
如果我们不关心 get_str()但是想要看 test_str(),执行 s 命令时会先进入 get_str()
1 | (gdb) s |
skip 不是 jump,虽然 skip 了这个函数,但是实际上它还是会执行,只是跳过了调试
- skip file filename
1 | (gdb) skip file test.cpp |
- skip -gfi 通配符
1 | -gfi可以通过文件名通配符匹配的方式跳过 |
jump 命令跳转
在指定位置恢复执行,如果存在断点,执行到指定位置时将中断下来。如果没有断点,则不会停下来,因此,我们通常会在指定位置设置一个断点。跳转命令不会更改当前堆栈帧,堆栈指针,程序计数器以外的任何寄存器
1 | # 向前跳转或向后跳转跳过某些行都可以,但跳转到别的函数的结果是不可预期的 |
- 核心作用:强制程序跳转到指定位置执行(可以是任意行号或地址),直接 “跳过” 中间的执行步骤。
rn 反向执行
首先要执行 record 命令
必须是 non-stop mode
1 | (gdb) record |
-
核心作用:实现程序执行历史的回溯,让程序 “倒着跑”,用于排查已经发生的错误(如变量何时被意外修改)。
停止模式(默认)
-
当你执行
run或continue时,整个程序和所有线程都会暂停/继续。 -
特点:
- 简单、易用
- 线程调试时无法单独控制线程
-
默认就是停止模式。
非停止模式(Non-stop mode)
-
每个线程可以单独暂停或继续,而不影响其他线程。
-
特点:
- 可以在多线程程序中只暂停某一线程进行调试
- 支持更灵活的线程调试
-
开启方法:
1
set non-stop on
-
注意:
- 不支持某些功能,例如 process record(执行记录)和某些远程 target 功能
查看运行时数据
程序暂停时,使用 print 命令(简写 p)或者用同义命令 inspect 查看当前程序的运行数据,格式为:
1 | print <expr> |
为要调试的程序语言的表达式 是 format 的意思,比如按 16 进制输出就是/x
print(p)输出格式
一般来说,GDB 会根据变量的类型输出变量的值。但你也可以自定义 GDB 的输出的格式。例如,你想输出一个整数的十六进制,或是二进制来查看这个整型变量的中的位的情况。要做到这样,你可以使用 GDB 的数据显示格式:
- x 按十六进制格式显示变量。 (hex)
- d 按十进制格式显示变量。 (decimal)
- u 按十六进制格式显示无符号整型。 (unsinged hex)
- o 按八进制格式显示变量。 (octal)
- t 按二进制格式显示变量。 (two)
- a 按十六进制格式显示变量。 (address)
- c 按字符格式显示变量。 (char)
- f 按浮点数格式显示变量。 (float)
1 | (gdb) p i |
表达式
表达式可以是当前程序运行中的 const 常量,变量,函数等内容,但不能是程序中定义的宏
程序变量
在 GDB 中,你可以随时查看以下三种变量的值:
- 全局变量(所有文件可见的)
- 静态全局变量(当前文件可见的)
- 局部变量(当前 Scope 可见的)
用 print 显示出的变量的值会是函数中的局部变量的值。如果此时你想查看全局变量的值时,你可以使用“::”操作符:
1 | file::variable |
example
1 | gdb) p 'f2.c'::x |
注意:如果你的程序编译时开启了优化选项,那么在用 GDB 调试被优化过的程序时,可能会发生某些变量不能访问,或是取值错误码的情况。这个是很正常的,因为优化程序会删改你的程序,整理你程序的语句顺序,剔除一些无意义的变量等,所以在 GDB 调试这种程序时,运行时的指令和你所编写指令就有不一样,也就会出现你所想象不到的结果。对付这种情况时,需要在编译程序时关闭编译优化。一般来说,几乎所有的编译器都支持编译优化的开关,例如,GNU 的 C/C++编译器 GCC,你可以使用“-gstabs”选项来解决这个问题。
数组
1 | int *array = (int *) malloc (len * sizeof (int)); |
在 GDB 调试过程中,你可以以如下命令显示出这个动态数组的取值:
1 | p *array@len |
@的左边是数组的首地址的值,也就是变量 array 所指向的内容,右边则是数据的长度,其保存在变量 len 中,其输出结果,大约是下面这个样子的:
1 | (gdb) p *array@len |
如果是静态数组的话,可以直接用 print 数组名,就可以显示数组中所有数据的内容了。
examine(x)查看内存
使用 examine 命令(简写是 x)来查看内存地址中的值。x 命令的语法如下所示:
1 | x/<n/f/u> <addr> |
-
n:显示的个数,即从内存地址
开始,显示几个单位(默认为 1)。 -
f:显示格式,比如:
- x 十六进制
- d 十进制
- t 二进制
- c 字符
- f 浮点数
- s 字符串
- i 指令
-
u:读取单位的大小,决定每次读取多少字节:
- b = 1 字节(byte)
- h = 2 字节(half word)
- w = 4 字节(word,默认)
- g = 8 字节(giant/quad word)
查看寄存器
要查看寄存器的值,很简单,可以使用 info registers (i r)
1 | # 查看寄存器的情况。(除了浮点寄存器) |
也可以使用 print 命令来访问寄存器的情况,只需要在寄存器名字前加一个$符号就可以了。如:
1 | p $eip。 |
查看所指定的寄存器的情况。寄存器中放置了程序运行时的数据,比如程序当前运行的指令地址(ip),程序的当前堆栈地址(sp)等等。你同样可以使用 print 命令来访问寄存器的情况,只需要在寄存器名字前加一个$符号就可以了。如:p $eip。
自动显示
你可以设置一些自动显示的变量,当程序停住时,或是在你单步跟踪时,这些变量会自动显示。相关的 GDB 命令是 display。
1 | display <expr> |
- expr 是一个表达式
- fmt 表示显示的格式
- addr 表示内存地址当你用 display 设定好了一个或多个表达式后,只要你的程序被停下来,GDB 会自动显示你所设置的这些表达式的值。
格式 i 和 s 同样被 display 支持,一个非常有用的命令是:
1 | display/i $pc |
$pc 是 GDB 的环境变量,表示着指令的地址,/i 则表示输出格式为机器指令码,也就是汇编。于是当程序停下后,就会出现源代码和机器指令码相对应的情形
删除自动显示
要删除自动显示可以用下面的命令
1 | undisplay <dnums...> |
- dnums 意为所设置好了的自动显式的编号。如果要同时删除几个,编号可以用空格分隔,如果要删除一个范围内的编号,可以用减号表示(如:2-5)
隐藏自动显示
1 | (gdb) disable display <dnums...> |
disable 和 enalbe 不删除自动显示的设置,而只是让其失效和恢复。
查看设置的自动显示的信息
1 | (gdb) info display |
查看 display 设置的自动显示的信息。GDB 会打出一张表格,向你报告当然调试中设置了多少个自动显示设置,其中包括,设置的编号,表达式,是否 enable。
查看函数参数
1 | (gdb) info args |
查看局部变量
1 | (gdb) info locals |
运行中修改值
修改变量的值
1 | (gdb) p test.age=28 |
修改寄存器的值
1 | set var $pc=xxx |
可以配合 info 指令,查看某一行的地址,或查看某一个栈帧的地址
1 | info line 14 |
查看函数调用栈
backtrace/bt 查看栈回溯信息
frame n 切换栈帧
info f n 查看栈帧信息
查看数据类型信息
whatis
1 | (gdb) whatis test1 |
ptype
1 | (gdb) ptype test1 |
可以显示这个类的成员变量,函数等
ptype /m
1 | (gdb) ptype /m test1 |
不显示成员函数了
ptype /t
1 | (gdb) ptype /t test3 |
不显示 typedef
ptype /o
1 | (gdb) ptype /o node |
查看结构体的偏移量和大小
i variables
1 | (gdb) i variables count |
会显示所有变量名含有 count 的变量的定义
set print object on
1 | (gdb) set print object on |
set print object on 表示显示出类的派生类型
调用内部外部函数
- p 表达式
求表达式的值并显示结果值。表达式可以包括对正在调试的程序中的函数的调用,即使函数返回值是 void,也会显示
- call 表达式
求表达式的值并显示结果值,如果是函数调用,返回值是 void 的话,不显示 void 返回值
1 | p sizeof(int) |
还有 strcmp,printf 等
多线程程序调试
线程管理相关命令
info threads
1 | (gdb) info threads |
查看所有线程信息,结果中序号前面有"*"表示当前线程

- Thread 后面跟线程的地址
- LWP 表示 Light Weight Process,轻量级线程(可以在命令行中使用 ps -aL 查看所有轻量级线程)
- 为给线程起名字时默认使用进程的名字
thread find
查找线程
1 | (gdb) thread find multh |
搜索的范围是线程,地址,lwp 以及线程名字,也就是 i threads 的前三项
thread num
1 | (gdb) bt |
切换线程,bt 只会显示当前线程的调用栈
thread name
设置线程名字,设置的是当前线程的名字
1 | (gdb) thread name main |
b breakpoint thread id
为线程单独设置断点
1 | (gdb) b 15 thread 2 |
如果用普通的 b 15,那么所有线程如果能执行到第 15 行都会停止下来
thread apply
为线程执行命令
1 | (gdb) thread apply 3 i args |
-q 不显示线程信息
-s 不显示错误信息
这两个参数都要放在线程 id 后面
set scheduler-locking off|on|step
set scheduler-locking 通过设置锁定策略,限制其他线程的执行,确保调试焦点始终在目标线程上
| 参数 | 作用 | 适用场景 |
|---|---|---|
off |
关闭锁定(默认),调度器可自由切换所有线程执行。 | 需观察多线程交互时(如线程同步、通信),允许其他线程自然执行。 |
on |
开启完全锁定,只有当前被调试的线程能执行,其他线程被暂停。 | 专注调试单个线程的逻辑(如函数调用链、局部变量变化),避免其他线程干扰。 |
step |
分步锁定,仅在单步执行(step)时锁定其他线程,continue 时解锁。 |
单步调试时需要隔离其他线程,但希望 continue 后程序能正常多线程运行。 |
1 | # 查看当前 scheduler-locking 配置 |
打印线程事件信息
1 | (gdb) show print thread-events |
多线程死锁调试
死锁条件:
- 互斥条件
- 保持和请求条件
- 不可剥夺条件
- 循环等待条件
常用命令:
- thread 2
- bt
- f 2
- p _mutex_2

解决死锁的方式:
- 顺序使用锁
- 控制锁的作用范围
- 可以使用超时机制
多进程程序调试
基本概念
inferior
gdb 使用 inferior 来表示一个被调试进程的状态,通常情况下,一个 inferior 代表一个进程,这是 gdb 内部的概念和对象,我们可以把运行的进程 attach 到 inferior 上
1 | (gdb) i inferiors |
set schedule-multiple on/off
允许多个进程同时执行
1 | (gdb) show schedule-multiple |
调试子进程
默认情况下无法调试子进程
set follow-fork-mode child/parent
默认情况下,follow-fork-mode 为 parent,即调试跟着父进程走,设置为 child 时才会跟着子进程走
1 | (gdb) set follow-fork-mode child |
set detach-on-fork on/off
默认情况下,detach-on-fork 为 on,即调试子进程时,父进程继续执行,父进程有可能直接执行结束,无法调试父进程了。因此,如果想要同时调试父进程和子进程,需要
1 | (gdb) set detach-on-fork off |
info inferiors
查看由 gdb 启动的进程,也就是 gdb 的子进程
inferior process_num
切换到 1 号子进程
1 | (gdb) inferior 1 |
制作调试发行版
发行版需要一个没有调试信息的版本,同时也要保留有调试信息的版本,方便调试
方法 1:去掉-g 参数和带有-g 参数的两个版本
在 Makefile 中写两个编译任务,分别是带-g 参数和不带-g 参数的版本
方法 2:strip 命令
1 | strip -g debug_version.o release_version.o |
方法 3:objcopy 命令
1 | # 生成纯调试符号文件 |
直接编辑可执行文件
gdb 启动时加入参数–write
1 | (gdb) gdb --write test.o |
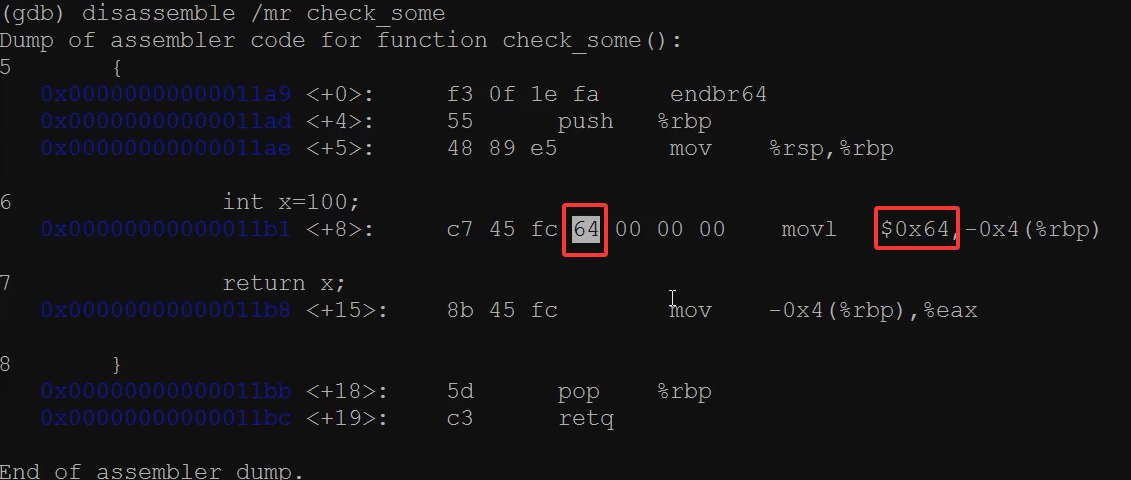
我们要修改的是机器码,修改后直接退出
1 | (gdb) p {unsigned char}0x00000000000011b4=0x65 |
内存检查
内存泄漏检查
call malloc_stats()
1 | (gdb) call malloc_stats() |
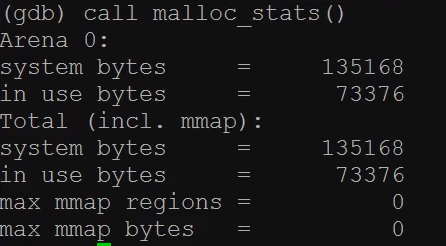
Arena0 表示当前线程使用的内存数据
Total 表示整个进程使用的内存数据
call malloc_info(0, stdout)
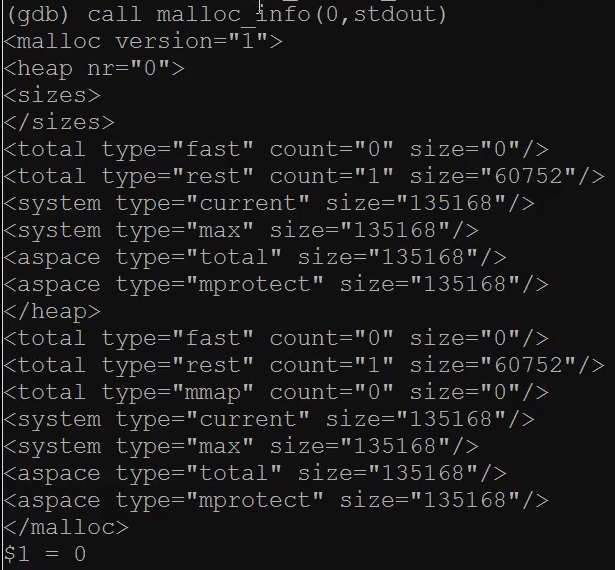
1 | (gdb) call malloc_info(0, stdout) |
输出的是 xml 格式,主要关注rest
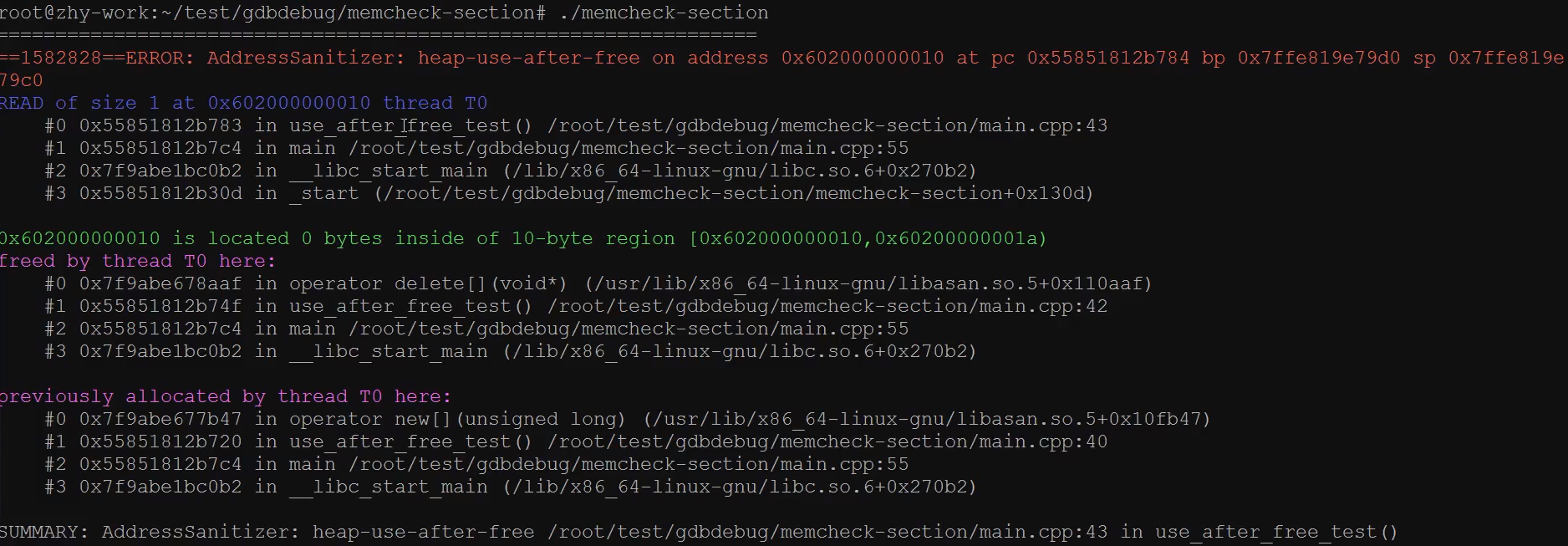
gcc 选项 -fsanitize=address
- 检查内存泄漏
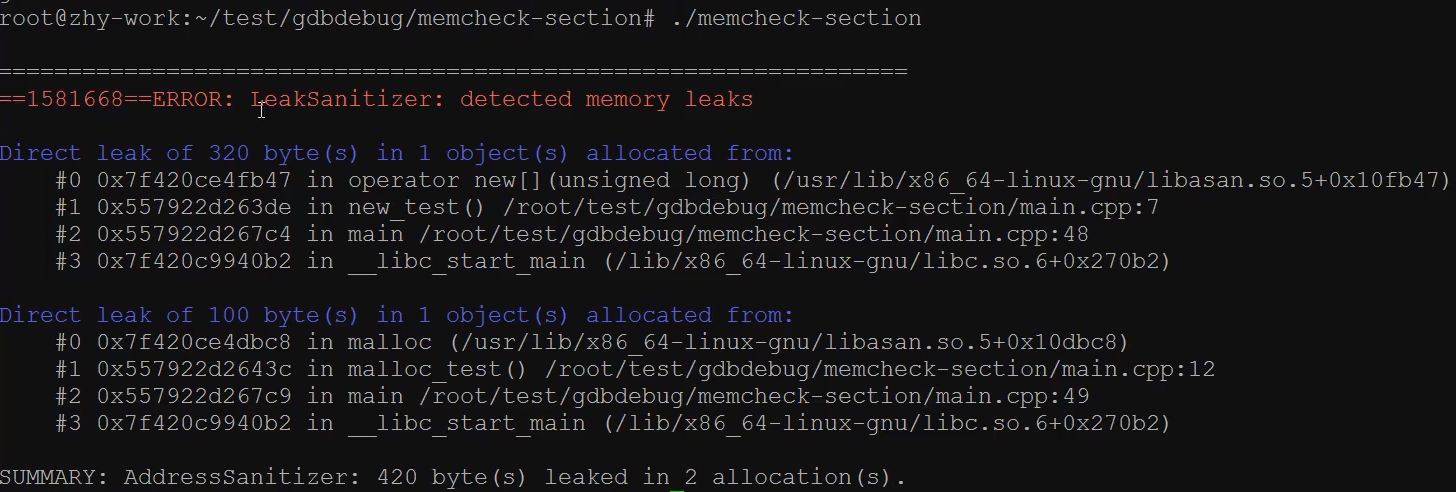
- 检查堆溢出
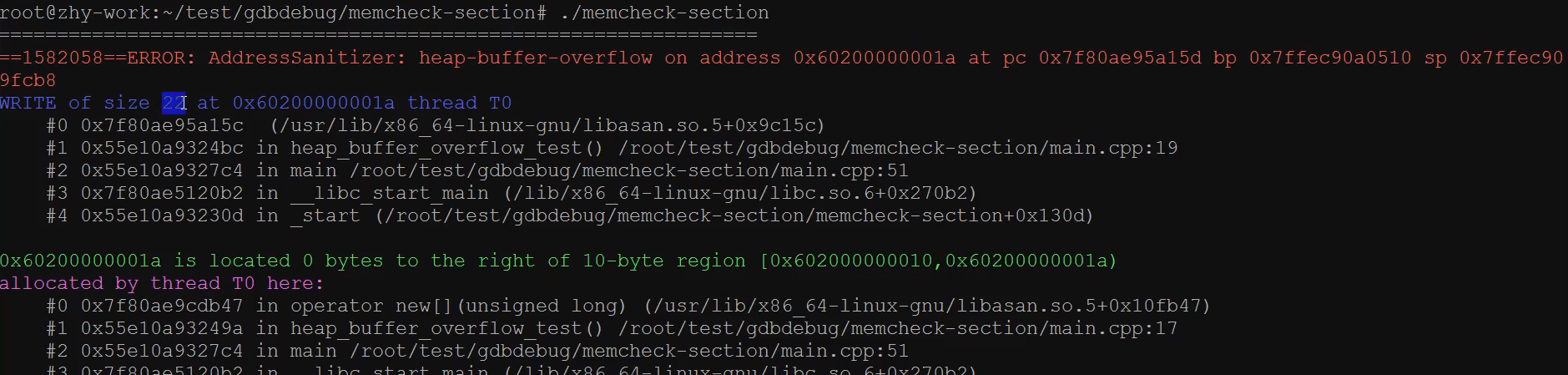
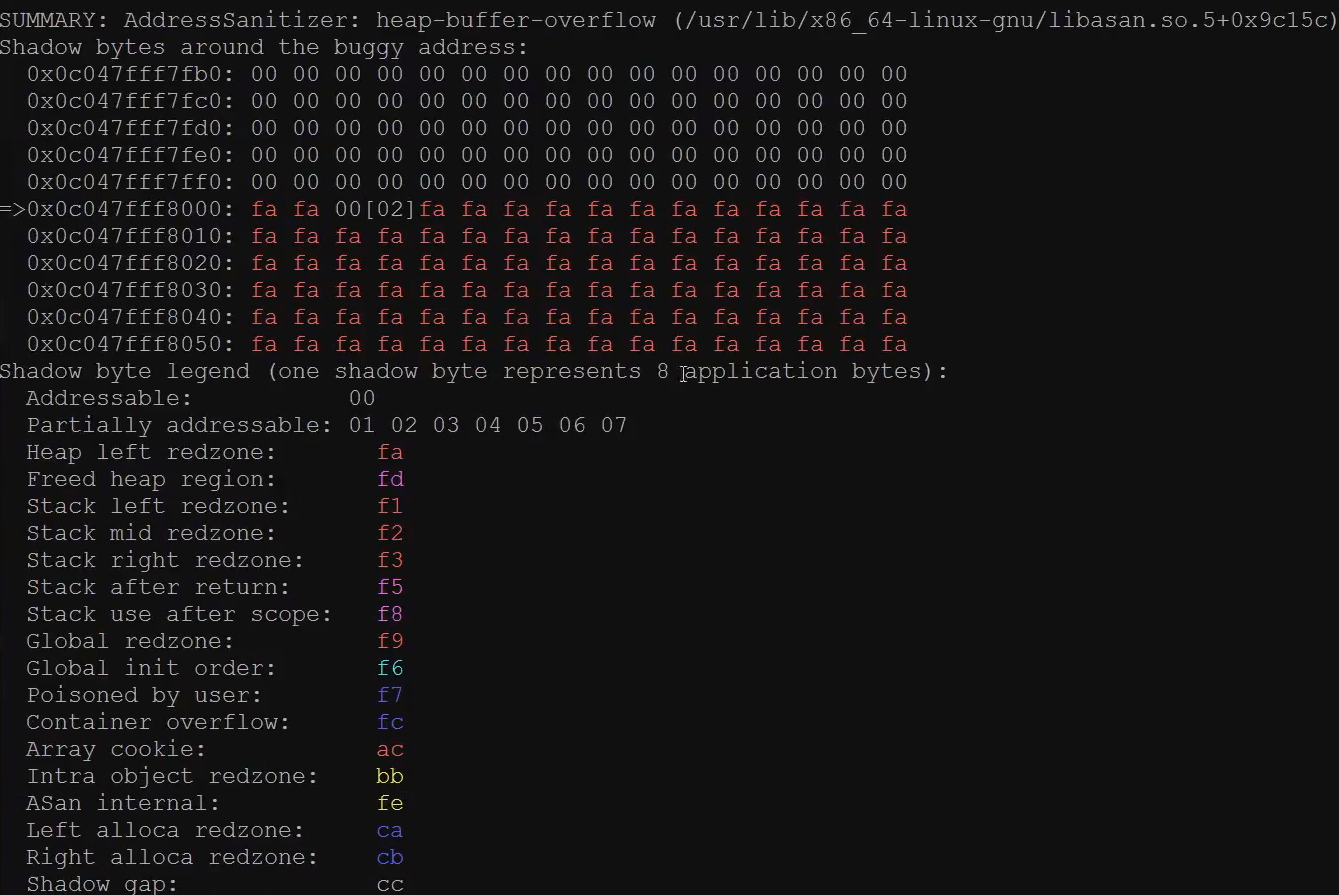
- 检查栈溢出
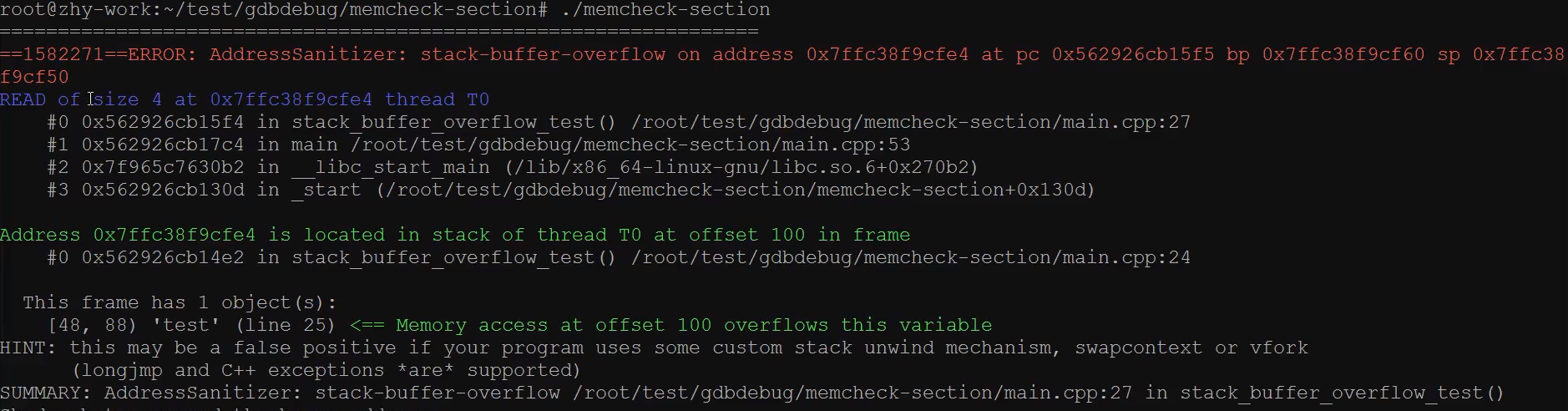
- 检查全局内存溢出

- 检查释放后再使用
远程调试
- 服务器端/被调试机
安装 gdbserver,启动 gdbserver
1 | ifconfig |
- 客户端/调试机
gdb 远程连接并进行调试
1 | (gdb) target remote 10.20.50.83:9988 |